 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimilar Users-Augmented Interest Network
Apr 26, 2026Click-through rate (CTR) prediction is one of the core tasks in recommender systems. User behavior sequences, as one of the most effective features, can accurately reflect user preferences and significantly improve prediction accuracy. Richer behavior sequences often enable more comprehensive user profiling, and recent studies have shown that scaling the length of user behavior sequence can yield substantial gains in CTR. However, due to the widespread sparsity in recommender systems, incomplete behavior sequences are common in real-world scenarios. Existing sequential modeling methods often rely solely on the target user's own behavior, and therefore struggle in such scenarios. This paper proposes a novel method called SUIN (Similar Users-augmented Interest Network), which enhances the target user's behavior sequence with behaviors from similar users to enhance the user profile for CTR prediction. Specifically, we use behavior embeddings encoded by a sequence encoder to retrieve users with similar behaviors from a user retrieval pool. The behavior sequences of these similar users are then concatenated with that of the target user in descending order of similarity to construct an augmented sequence. Given that the augmented sequence contains behaviors from multiple users, we propose a user-specific target-aware position encoding, which identifies the source user of each behavior and captures its relative position to the target item. Furthermore, to mitigate the empirically observed noise in similar users' behaviors, we design a user-aware target attention that jointly considers item-item and user-user correlations, fully exploiting the potential of the augmented behavior sequence. Comprehensive experiments on widely-used short-term and long-term sequence benchmark datasets demonstrate that our method significantly outperforms state-of-the-art sequential CTR models.
LongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
NDCG-Consistent Softmax Approximation with Accelerated Convergence
Jun 11, 2025
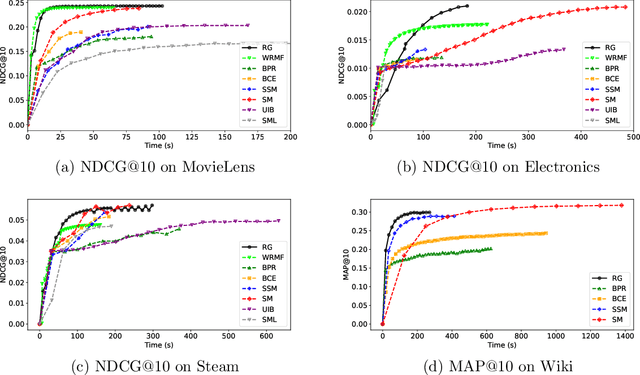

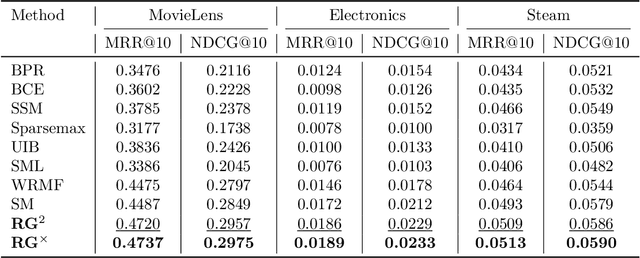
Ranking tasks constitute fundamental components of extreme similarity learning frameworks, where extremely large corpora of objects are modeled through relative similarity relationships adhering to predefined ordinal structures. Among various ranking surrogates, Softmax (SM) Loss has been widely adopted due to its natural capability to handle listwise ranking via global negative comparisons, along with its flexibility across diverse application scenarios. However, despite its effectiveness, SM Loss often suffers from significant computational overhead and scalability limitations when applied to large-scale object spaces. To address this challenge, we propose novel loss formulations that align directly with ranking metrics: the Ranking-Generalizable \textbf{squared} (RG$^2$) Loss and the Ranking-Generalizable interactive (RG$^\times$) Loss, both derived through Taylor expansions of the SM Loss. Notably, RG$^2$ reveals the intrinsic mechanisms underlying weighted squared losses (WSL) in ranking methods and uncovers fundamental connections between sampling-based and non-sampling-based loss paradigms. Furthermore, we integrate the proposed RG losses with the highly efficient Alternating Least Squares (ALS) optimization method, providing both generalization guarantees and convergence rate analyses. Empirical evaluations on real-world datasets demonstrate that our approach achieves comparable or superior ranking performance relative to SM Loss, while significantly accelerating convergence. This framework offers the similarity learning community both theoretical insights and practically efficient tools, with methodologies applicable to a broad range of tasks where balancing ranking quality and computational efficiency is essential.
Optimizing Case-Based Reasoning System for Functional Test Script Generation with Large Language Models
Mar 26, 2025In this work, we explore the potential of large language models (LLMs) for generating functional test scripts, which necessitates understanding the dynamically evolving code structure of the target software. To achieve this, we propose a case-based reasoning (CBR) system utilizing a 4R cycle (i.e., retrieve, reuse, revise, and retain), which maintains and leverages a case bank of test intent descriptions and corresponding test scripts to facilitate LLMs for test script generation. To improve user experience further, we introduce Re4, an optimization method for the CBR system, comprising reranking-based retrieval finetuning and reinforced reuse finetuning. Specifically, we first identify positive examples with high semantic and script similarity, providing reliable pseudo-labels for finetuning the retriever model without costly labeling. Then, we apply supervised finetuning, followed by a reinforcement learning finetuning stage, to align LLMs with our production scenarios, ensuring the faithful reuse of retrieved cases. Extensive experimental results on two product development units from Huawei Datacom demonstrate the superiority of the proposed CBR+Re4. Notably, we also show that the proposed Re4 method can help alleviate the repetitive generation issues with LLMs.
Human-aligned Safe Reinforcement Learning for Highway On-Ramp Merging in Dense Traffic
Mar 04, 2025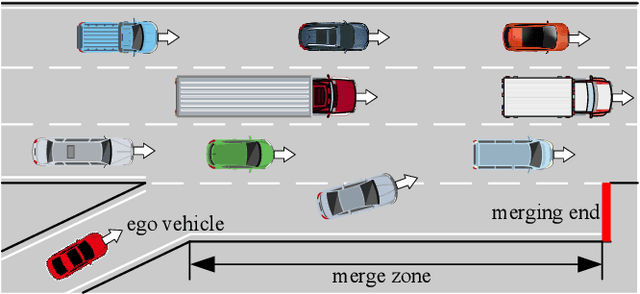
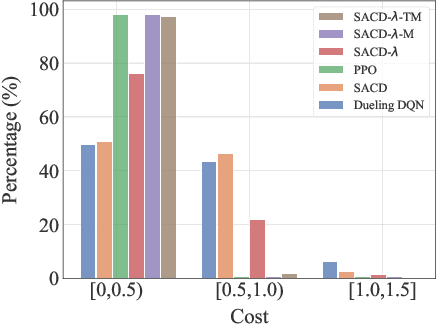
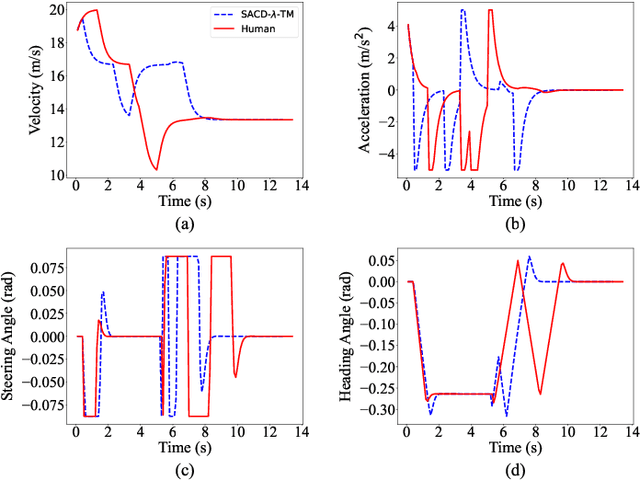
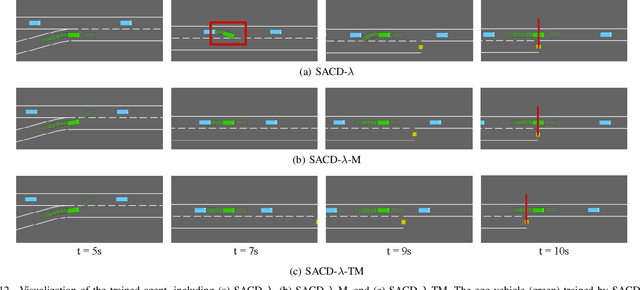
Most reinforcement learning (RL) approaches for the decision-making of autonomous driving consider safety as a reward instead of a cost, which makes it hard to balance the tradeoff between safety and other objectives. Human risk preference has also rarely been incorporated, and the trained policy might be either conservative or aggressive for users. To this end, this study proposes a human-aligned safe RL approach for autonomous merging, in which the high-level decision problem is formulated as a constrained Markov decision process (CMDP) that incorporates users' risk preference into the safety constraints, followed by a model predictive control (MPC)-based low-level control. The safety level of RL policy can be adjusted by computing cost limits of CMDP's constraints based on risk preferences and traffic density using a fuzzy control method. To filter out unsafe or invalid actions, we design an action shielding mechanism that pre-executes RL actions using an MPC method and performs collision checks with surrounding agents. We also provide theoretical proof to validate the effectiveness of the shielding mechanism in enhancing RL's safety and sample efficiency. Simulation experiments in multiple levels of traffic densities show that our method can significantly reduce safety violations without sacrificing traffic efficiency. Furthermore, due to the use of risk preference-aware constraints in CMDP and action shielding, we can not only adjust the safety level of the final policy but also reduce safety violations during the training stage, proving a promising solution for online learning in real-world environments.
CELA: Cost-Efficient Language Model Alignment for CTR Prediction
May 17, 2024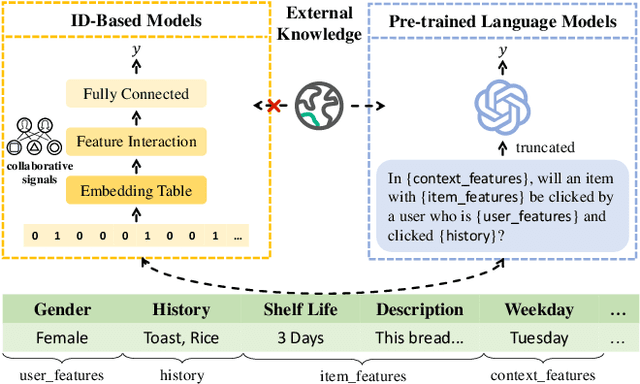
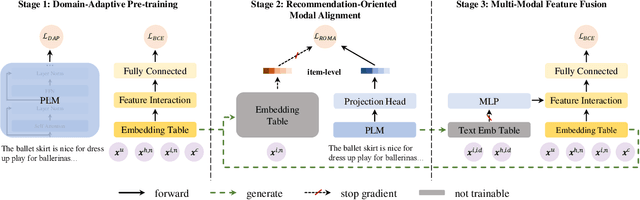
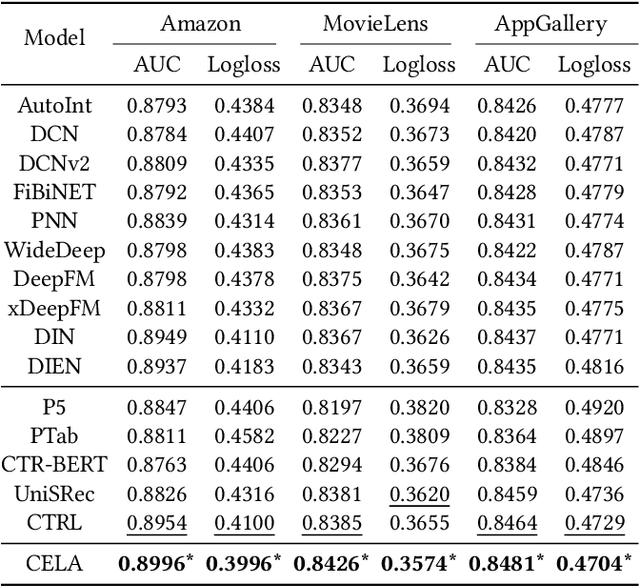
Click-Through Rate (CTR) prediction holds a paramount position in recommender systems. The prevailing ID-based paradigm underperforms in cold-start scenarios due to the skewed distribution of feature frequency. Additionally, the utilization of a single modality fails to exploit the knowledge contained within textual features. Recent efforts have sought to mitigate these challenges by integrating Pre-trained Language Models (PLMs). They design hard prompts to structure raw features into text for each interaction and then apply PLMs for text processing. With external knowledge and reasoning capabilities, PLMs extract valuable information even in cases of sparse interactions. Nevertheless, compared to ID-based models, pure text modeling degrades the efficacy of collaborative filtering, as well as feature scalability and efficiency during both training and inference. To address these issues, we propose \textbf{C}ost-\textbf{E}fficient \textbf{L}anguage Model \textbf{A}lignment (\textbf{CELA}) for CTR prediction. CELA incorporates textual features and language models while preserving the collaborative filtering capabilities of ID-based models. This model-agnostic framework can be equipped with plug-and-play textual features, with item-level alignment enhancing the utilization of external information while maintaining training and inference efficiency. Through extensive offline experiments, CELA demonstrates superior performance compared to state-of-the-art methods. Furthermore, an online A/B test conducted on an industrial App recommender system showcases its practical effectiveness, solidifying the potential for real-world applications of CELA.
WESE: Weak Exploration to Strong Exploitation for LLM Agents
Apr 11, 2024
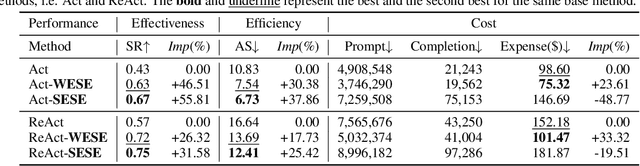
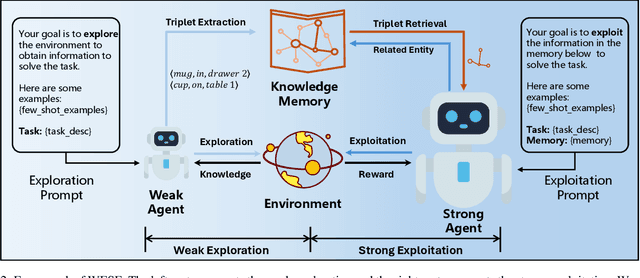
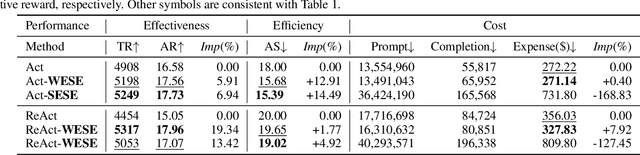
Recently, large language models (LLMs) have demonstrated remarkable potential as an intelligent agent. However, existing researches mainly focus on enhancing the agent's reasoning or decision-making abilities through well-designed prompt engineering or task-specific fine-tuning, ignoring the procedure of exploration and exploitation. When addressing complex tasks within open-world interactive environments, these methods exhibit limitations. Firstly, the lack of global information of environments leads to greedy decisions, resulting in sub-optimal solutions. On the other hand, irrelevant information acquired from the environment not only adversely introduces noise, but also incurs additional cost. This paper proposes a novel approach, Weak Exploration to Strong Exploitation (WESE), to enhance LLM agents in solving open-world interactive tasks. Concretely, WESE involves decoupling the exploration and exploitation process, employing a cost-effective weak agent to perform exploration tasks for global knowledge. A knowledge graph-based strategy is then introduced to store the acquired knowledge and extract task-relevant knowledge, enhancing the stronger agent in success rate and efficiency for the exploitation task. Our approach is flexible enough to incorporate diverse tasks, and obtains significant improvements in both success rates and efficiency across four interactive benchmarks.
You Only Sample Once: Taming One-Step Text-To-Image Synthesis by Self-Cooperative Diffusion GANs
Mar 29, 2024



We introduce YOSO, a novel generative model designed for rapid, scalable, and high-fidelity one-step image synthesis. This is achieved by integrating the diffusion process with GANs. Specifically, we smooth the distribution by the denoising generator itself, performing self-cooperative learning. We show that our method can serve as a one-step generation model training from scratch with competitive performance. Moreover, we show that our method can be extended to finetune pre-trained text-to-image diffusion for high-quality one-step text-to-image synthesis even with LoRA fine-tuning. In particular, we provide the first diffusion transformer that can generate images in one step trained on 512 resolution, with the capability of adapting to 1024 resolution without explicit training. Our code is provided at https://github.com/Luo-Yihong/YOSO.
Understanding the planning of LLM agents: A survey
Feb 05, 2024As Large Language Models (LLMs) have shown significant intelligence, the progress to leverage LLMs as planning modules of autonomous agents has attracted more attention. This survey provides the first systematic view of LLM-based agents planning, covering recent works aiming to improve planning ability. We provide a taxonomy of existing works on LLM-Agent planning, which can be categorized into Task Decomposition, Plan Selection, External Module, Reflection and Memory. Comprehensive analyses are conducted for each direction, and further challenges for the field of research are discussed.
When Large Language Models Meet Personalization: Perspectives of Challenges and Opportunities
Jul 31, 2023The advent of large language models marks a revolutionary breakthrough in artificial intelligence. With the unprecedented scale of training and model parameters, the capability of large language models has been dramatically improved, leading to human-like performances in understanding, language synthesizing, and common-sense reasoning, etc. Such a major leap-forward in general AI capacity will change the pattern of how personalization is conducted. For one thing, it will reform the way of interaction between humans and personalization systems. Instead of being a passive medium of information filtering, large language models present the foundation for active user engagement. On top of such a new foundation, user requests can be proactively explored, and user's required information can be delivered in a natural and explainable way. For another thing, it will also considerably expand the scope of personalization, making it grow from the sole function of collecting personalized information to the compound function of providing personalized services. By leveraging large language models as general-purpose interface, the personalization systems may compile user requests into plans, calls the functions of external tools to execute the plans, and integrate the tools' outputs to complete the end-to-end personalization tasks. Today, large language models are still being developed, whereas the application in personalization is largely unexplored. Therefore, we consider it to be the right time to review the challenges in personalization and the opportunities to address them with LLMs. In particular, we dedicate this perspective paper to the discussion of the following aspects: the development and challenges for the existing personalization system, the newly emerged capabilities of large language models, and the potential ways of making use of large language models for personalization.