 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Improving Multilingual Long Reasoning via Translation-Reasoning Integrated Training
Feb 05, 2026Long reasoning models often struggle in multilingual settings: they tend to reason in English for non-English questions; when constrained to reasoning in the question language, accuracies drop substantially. The struggle is caused by the limited abilities for both multilingual question understanding and multilingual reasoning. To address both problems, we propose TRIT (Translation-Reasoning Integrated Training), a self-improving framework that integrates the training of translation into multilingual reasoning. Without external feedback or additional multilingual data, our method jointly enhances multilingual question understanding and response generation. On MMATH, our method outperforms multiple baselines by an average of 7 percentage points, improving both answer correctness and language consistency. Further analysis reveals that integrating translation training improves cross-lingual question alignment by over 10 percentage points and enhances translation quality for both mathematical questions and general-domain text, with gains up to 8.4 COMET points on FLORES-200.
Making Mathematical Reasoning Adaptive
Oct 06, 2025



Mathematical reasoning is a primary indicator of large language models (LLMs) intelligence. However, existing LLMs exhibit failures of robustness and generalization. This paper attributes these deficiencies to spurious reasoning, i.e., producing answers from superficial features. To address this challenge, we propose the AdaR framework to enable adaptive reasoning, wherein models rely on problem-solving logic to produce answers. AdaR synthesizes logically equivalent queries by varying variable values, and trains models with RLVR on these data to penalize spurious logic while encouraging adaptive logic. To improve data quality, we extract the problem-solving logic from the original query and generate the corresponding answer by code execution, then apply a sanity check. Experimental results demonstrate that AdaR improves robustness and generalization, achieving substantial improvement in mathematical reasoning while maintaining high data efficiency. Analysis indicates that data synthesis and RLVR function in a coordinated manner to enable adaptive reasoning in LLMs. Subsequent analyses derive key design insights into the effect of critical factors and the applicability to instruct LLMs. Our project is available at https://github.com/LaiZhejian/AdaR
Investigating and Scaling up Code-Switching for Multilingual Language Model Pre-Training
Apr 02, 2025Large language models (LLMs) exhibit remarkable multilingual capabilities despite the extreme language imbalance in the pre-training data. In this paper, we closely examine the reasons behind this phenomenon, focusing on the pre-training corpus. We find that the existence of code-switching, alternating between different languages within a context, is key to multilingual capabilities. We conduct an analysis to investigate code-switching in the pre-training corpus, examining its presence and categorizing it into four types within two quadrants. We then assess its impact on multilingual performance. These types of code-switching data are unbalanced in proportions and demonstrate different effects on facilitating language transfer. To better explore the power of code-switching for language alignment during pre-training, we investigate the strategy of synthetic code-switching. We continuously scale up the synthetic code-switching data and observe remarkable improvements in both benchmarks and representation space. Extensive experiments indicate that incorporating synthetic code-switching data enables better language alignment and generalizes well to high, medium, and low-resource languages with pre-training corpora of varying qualities.
2D Integrated Bayesian Tomography of Plasma Electron Density Profile for HL-3 Based on Gaussian Process
Feb 13, 2025This paper introduces an integrated Bayesian model that combines line integral measurements and point values using Gaussian Process (GP). The proposed method leverages Gaussian Process Regression (GPR) to incorporate point values into 2D profiles and employs coordinate mapping to integrate magnetic flux information for 2D inversion. The average relative error of the reconstructed profile, using the integrated Bayesian tomography model with normalized magnetic flux, is as low as 3.60*10^(-4). Additionally, sensitivity tests were conducted on the number of grids, the standard deviation of synthetic diagnostic data, and noise levels, laying a solid foundation for the application of the model to experimental data. This work not only achieves accurate 2D inversion using the integrated Bayesian model but also provides a robust framework for decoupling pressure information from equilibrium reconstruction, thus making it possible to optimize equilibrium reconstruction using inversion results.
ONION: Physics-Informed Deep Learning Model for Line Integral Diagnostics Across Fusion Devices
Nov 27, 2024This paper introduces a Physics-Informed model architecture that can be adapted to various backbone networks. The model incorporates physical information as additional input and is constrained by a Physics-Informed loss function. Experimental results demonstrate that the additional input of physical information substantially improve the model's ability with a increase in performance observed. Besides, the adoption of the Softplus activation function in the final two fully connected layers significantly enhances model performance. The incorporation of a Physics-Informed loss function has been shown to correct the model's predictions, bringing the back-projections closer to the actual inputs and reducing the errors associated with inversion algorithms. In this work, we have developed a Phantom Data Model to generate customized line integral diagnostic datasets and have also collected SXR diagnostic datasets from EAST and HL-2A. The code, models, and some datasets are publicly available at https://github.com/calledice/onion.
MoE-LPR: Multilingual Extension of Large Language Models through Mixture-of-Experts with Language Priors Routing
Aug 21, 2024



Large Language Models (LLMs) are often English-centric due to the disproportionate distribution of languages in their pre-training data. Enhancing non-English language capabilities through post-pretraining often results in catastrophic forgetting of the ability of original languages. Previous methods either achieve good expansion with severe forgetting or slight forgetting with poor expansion, indicating the challenge of balancing language expansion while preventing forgetting. In this paper, we propose a method called MoE-LPR (Mixture-of-Experts with Language Priors Routing) to alleviate this problem. MoE-LPR employs a two-stage training approach to enhance the multilingual capability. First, the model is post-pretrained into a Mixture-of-Experts (MoE) architecture by upcycling, where all the original parameters are frozen and new experts are added. In this stage, we focus improving the ability on expanded languages, without using any original language data. Then, the model reviews the knowledge of the original languages with replay data amounting to less than 1% of post-pretraining, where we incorporate language priors routing to better recover the abilities of the original languages. Evaluations on multiple benchmarks show that MoE-LPR outperforms other post-pretraining methods. Freezing original parameters preserves original language knowledge while adding new experts preserves the learning ability. Reviewing with LPR enables effective utilization of multilingual knowledge within the parameters. Additionally, the MoE architecture maintains the same inference overhead while increasing total model parameters. Extensive experiments demonstrate MoE-LPR's effectiveness in improving expanded languages and preserving original language proficiency with superior scalability. Code and scripts are freely available at https://github.com/zjwang21/MoE-LPR.git.
Taiyi: A Bilingual Fine-Tuned Large Language Model for Diverse Biomedical Tasks
Nov 20, 2023



Recent advancements in large language models (LLMs) have shown promising results across a variety of natural language processing (NLP) tasks. The application of LLMs to specific domains, such as biomedicine, has achieved increased attention. However, most biomedical LLMs focus on enhancing performance in monolingual biomedical question answering and conversation tasks. To further investigate the effectiveness of the LLMs on diverse biomedical NLP tasks in different languages, we present Taiyi, a bilingual (English and Chinese) fine-tuned LLM for diverse biomedical tasks. In this work, we first curated a comprehensive collection of 140 existing biomedical text mining datasets across over 10 task types. Subsequently, a two-stage strategy is proposed for supervised fine-tuning to optimize the model performance across varied tasks. Experimental results on 13 test sets covering named entity recognition, relation extraction, text classification, question answering tasks demonstrate Taiyi achieves superior performance compared to general LLMs. The case study involving additional biomedical NLP tasks further shows Taiyi's considerable potential for bilingual biomedical multi-tasking. The source code, datasets, and model for Taiyi are freely available at https://github.com/DUTIR-BioNLP/Taiyi-LLM.
Trend-Based SAC Beam Control Method with Zero-Shot in Superconducting Linear Accelerator
May 25, 2023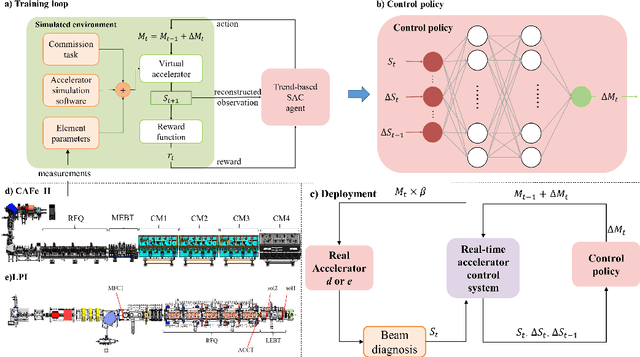

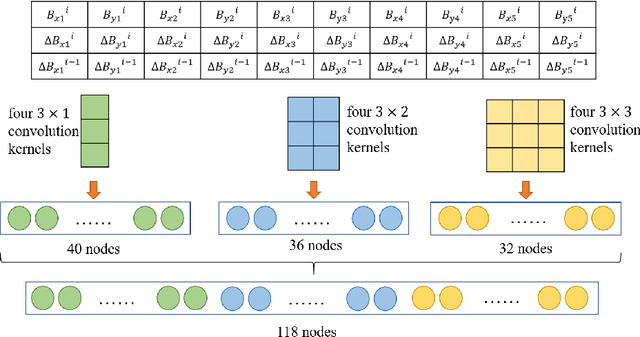
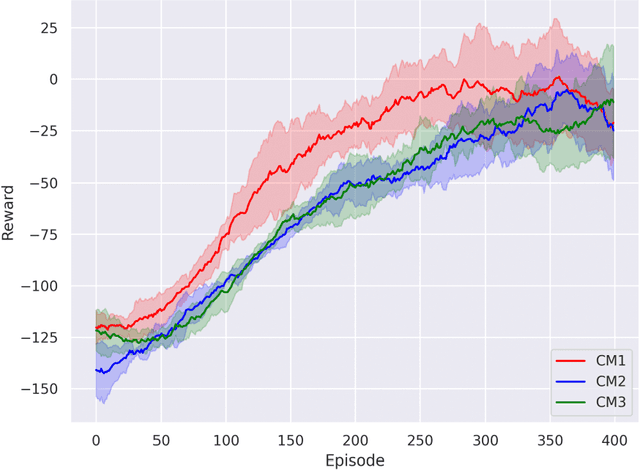
The superconducting linear accelerator is a highly flexiable facility for modern scientific discoveries, necessitating weekly reconfiguration and tuning. Accordingly, minimizing setup time proves essential in affording users with ample experimental time. We propose a trend-based soft actor-critic(TBSAC) beam control method with strong robustness, allowing the agents to be trained in a simulated environment and applied to the real accelerator directly with zero-shot. To validate the effectiveness of our method, two different typical beam control tasks were performed on China Accelerator Facility for Superheavy Elements (CAFe II) and a light particle injector(LPI) respectively. The orbit correction tasks were performed in three cryomodules in CAFe II seperately, the time required for tuning has been reduced to one-tenth of that needed by human experts, and the RMS values of the corrected orbit were all less than 1mm. The other transmission efficiency optimization task was conducted in the LPI, our agent successfully optimized the transmission efficiency of radio-frequency quadrupole(RFQ) to over $85\%$ within 2 minutes. The outcomes of these two experiments offer substantiation that our proposed TBSAC approach can efficiently and effectively accomplish beam commissioning tasks while upholding the same standard as skilled human experts. As such, our method exhibits potential for future applications in other accelerator commissioning fields.
Breaking the Representation Bottleneck of Chinese Characters: Neural Machine Translation with Stroke Sequence Modeling
Nov 23, 2022



Existing research generally treats Chinese character as a minimum unit for representation. However, such Chinese character representation will suffer two bottlenecks: 1) Learning bottleneck, the learning cannot benefit from its rich internal features (e.g., radicals and strokes); and 2) Parameter bottleneck, each individual character has to be represented by a unique vector. In this paper, we introduce a novel representation method for Chinese characters to break the bottlenecks, namely StrokeNet, which represents a Chinese character by a Latinized stroke sequence (e.g., "ao1 (concave)" to "ajaie" and "tu1 (convex)" to "aeaqe"). Specifically, StrokeNet maps each stroke to a specific Latin character, thus allowing similar Chinese characters to have similar Latin representations. With the introduction of StrokeNet to neural machine translation (NMT), many powerful but not applicable techniques to non-Latin languages (e.g., shared subword vocabulary learning and ciphertext-based data augmentation) can now be perfectly implemented. Experiments on the widely-used NIST Chinese-English, WMT17 Chinese-English and IWSLT17 Japanese-English NMT tasks show that StrokeNet can provide a significant performance boost over the strong baselines with fewer model parameters, achieving 26.5 BLEU on the WMT17 Chinese-English task which is better than any previously reported results without using monolingual data. Code and scripts are freely available at https://github.com/zjwang21/StrokeNet.