 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrend-Based SAC Beam Control Method with Zero-Shot in Superconducting Linear Accelerator
May 25, 2023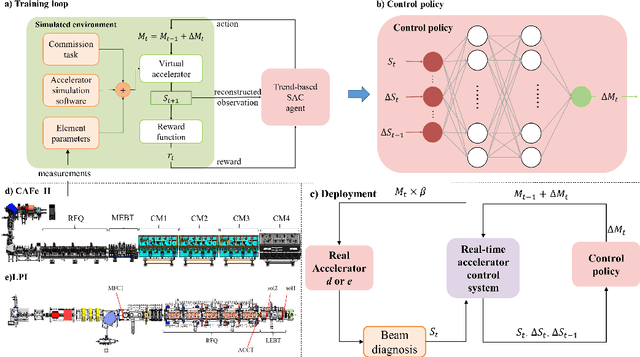

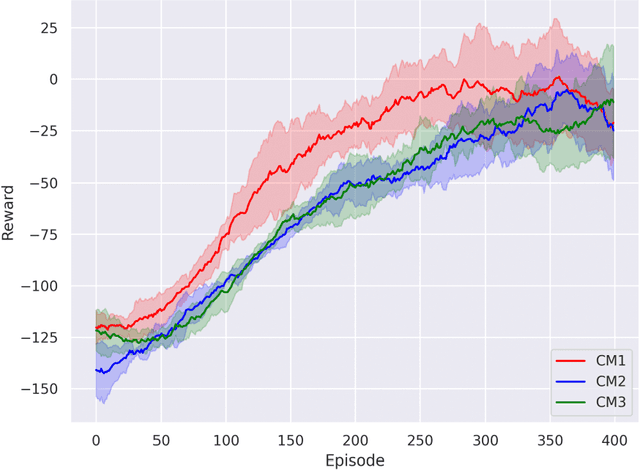
The superconducting linear accelerator is a highly flexiable facility for modern scientific discoveries, necessitating weekly reconfiguration and tuning. Accordingly, minimizing setup time proves essential in affording users with ample experimental time. We propose a trend-based soft actor-critic(TBSAC) beam control method with strong robustness, allowing the agents to be trained in a simulated environment and applied to the real accelerator directly with zero-shot. To validate the effectiveness of our method, two different typical beam control tasks were performed on China Accelerator Facility for Superheavy Elements (CAFe II) and a light particle injector(LPI) respectively. The orbit correction tasks were performed in three cryomodules in CAFe II seperately, the time required for tuning has been reduced to one-tenth of that needed by human experts, and the RMS values of the corrected orbit were all less than 1mm. The other transmission efficiency optimization task was conducted in the LPI, our agent successfully optimized the transmission efficiency of radio-frequency quadrupole(RFQ) to over $85\%$ within 2 minutes. The outcomes of these two experiments offer substantiation that our proposed TBSAC approach can efficiently and effectively accomplish beam commissioning tasks while upholding the same standard as skilled human experts. As such, our method exhibits potential for future applications in other accelerator commissioning fields.
Eeg2vec: Self-Supervised Electroencephalographic Representation Learning
May 23, 2023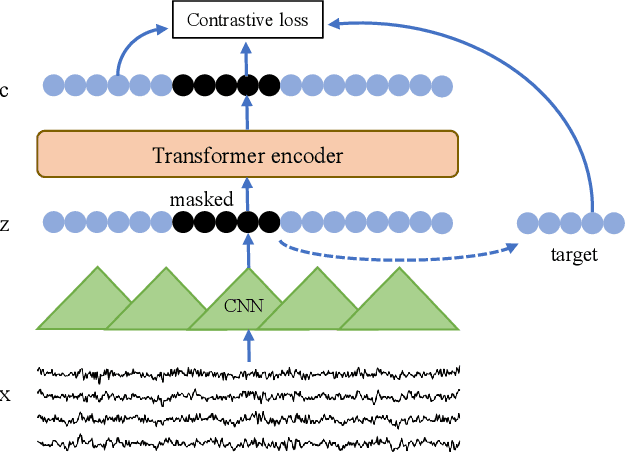
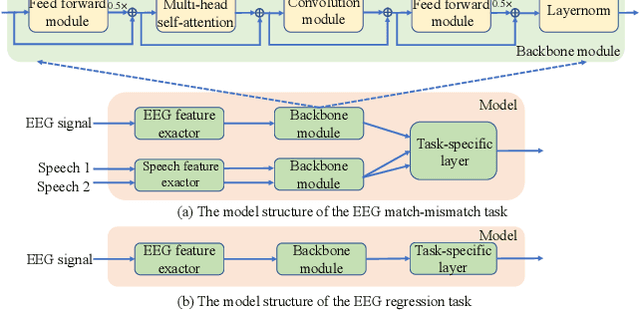
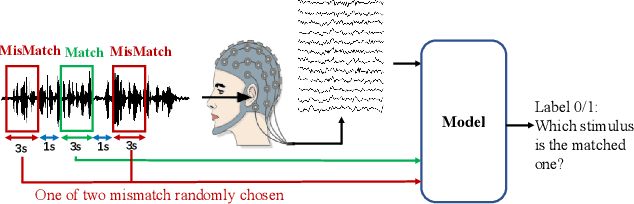
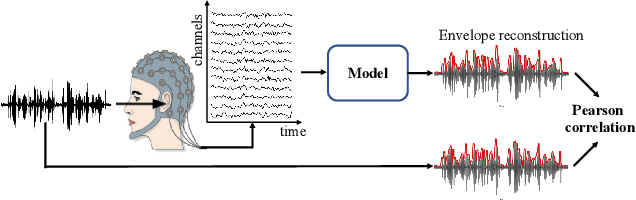
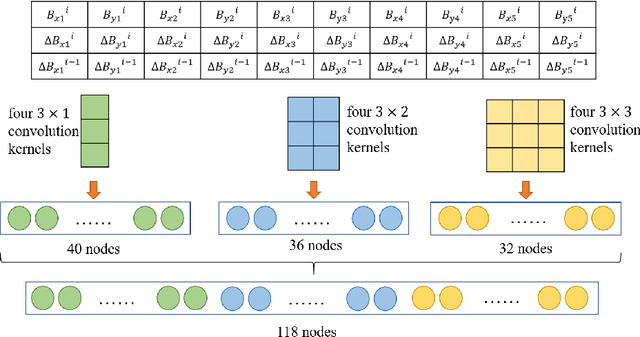
Recently, many efforts have been made to explore how the brain processes speech using electroencephalographic (EEG) signals, where deep learning-based approaches were shown to be applicable in this field. In order to decode speech signals from EEG signals, linear networks, convolutional neural networks (CNN) and long short-term memory networks are often used in a supervised manner. Recording EEG-speech labeled data is rather time-consuming and laborious, while unlabeled EEG data is abundantly available. Whether self-supervised methods are helpful to learn EEG representation to boost the performance of EEG auditory-related tasks has not been well explored. In this work, we first propose a self-supervised model based on contrastive loss and reconstruction loss to learn EEG representations, and then use the obtained pre-trained model as a feature extractor for downstream tasks. Second, for two considered downstream tasks, we use CNNs and Transformer networks to learn local features and global features, respectively. Finally, the EEG data from other channels are mixed into the chosen EEG data for augmentation. The effectiveness of our method is verified on the EEG match-mismatch and EEG regression tasks of the ICASSP2023 Auditory EEG Challenge.
Learning Incrementally to Segment Multiple Organs in a CT Image
Mar 04, 2022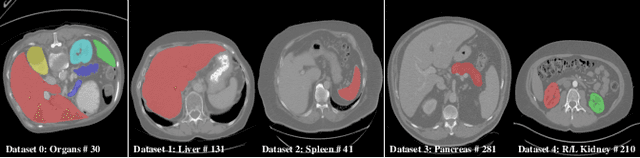
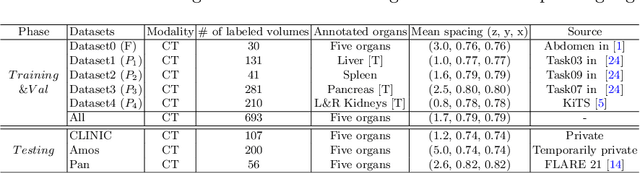
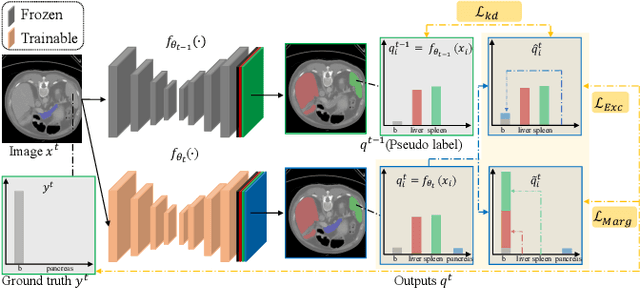
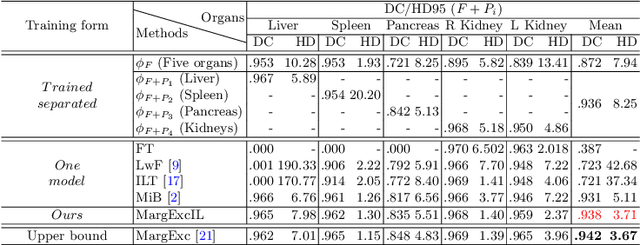
There exists a large number of datasets for organ segmentation, which are partially annotated and sequentially constructed. A typical dataset is constructed at a certain time by curating medical images and annotating the organs of interest. In other words, new datasets with annotations of new organ categories are built over time. To unleash the potential behind these partially labeled, sequentially-constructed datasets, we propose to incrementally learn a multi-organ segmentation model. In each incremental learning (IL) stage, we lose the access to previous data and annotations, whose knowledge is assumingly captured by the current model, and gain the access to a new dataset with annotations of new organ categories, from which we learn to update the organ segmentation model to include the new organs. While IL is notorious for its `catastrophic forgetting' weakness in the context of natural image analysis, we experimentally discover that such a weakness mostly disappears for CT multi-organ segmentation. To further stabilize the model performance across the IL stages, we introduce a light memory module and some loss functions to restrain the representation of different categories in feature space, aggregating feature representation of the same class and separating feature representation of different classes. Extensive experiments on five open-sourced datasets are conducted to illustrate the effectiveness of our method.