 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPI-TTS: Directional Patch Interaction for Fast-Converging and Style Temporal Modeling in Text-to-Speech
Sep 18, 2024


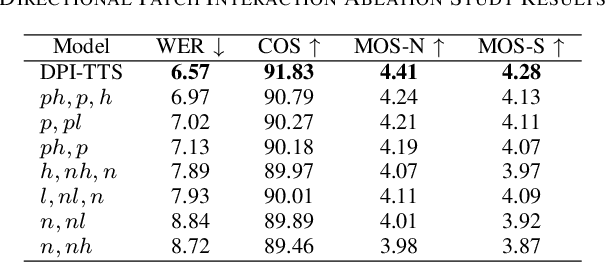
In recent years, speech diffusion models have advanced rapidly. Alongside the widely used U-Net architecture, transformer-based models such as the Diffusion Transformer (DiT) have also gained attention. However, current DiT speech models treat Mel spectrograms as general images, which overlooks the specific acoustic properties of speech. To address these limitations, we propose a method called Directional Patch Interaction for Text-to-Speech (DPI-TTS), which builds on DiT and achieves fast training without compromising accuracy. Notably, DPI-TTS employs a low-to-high frequency, frame-by-frame progressive inference approach that aligns more closely with acoustic properties, enhancing the naturalness of the generated speech. Additionally, we introduce a fine-grained style temporal modeling method that further improves speaker style similarity. Experimental results demonstrate that our method increases the training speed by nearly 2 times and significantly outperforms the baseline models.
Mixture of Experts Fusion for Fake Audio Detection Using Frozen wav2vec 2.0
Sep 18, 2024



Speech synthesis technology has posed a serious threat to speaker verification systems. Currently, the most effective fake audio detection methods utilize pretrained models, and integrating features from various layers of pretrained model further enhances detection performance. However, most of the previously proposed fusion methods require fine-tuning the pretrained models, resulting in excessively long training times and hindering model iteration when facing new speech synthesis technology. To address this issue, this paper proposes a feature fusion method based on the Mixture of Experts, which extracts and integrates features relevant to fake audio detection from layer features, guided by a gating network based on the last layer feature, while freezing the pretrained model. Experiments conducted on the ASVspoof2019 and ASVspoof2021 datasets demonstrate that the proposed method achieves competitive performance compared to those requiring fine-tuning.
Text Prompt is Not Enough: Sound Event Enhanced Prompt Adapter for Target Style Audio Generation
Sep 14, 2024



Current mainstream audio generation methods primarily rely on simple text prompts, often failing to capture the nuanced details necessary for multi-style audio generation. To address this limitation, the Sound Event Enhanced Prompt Adapter is proposed. Unlike traditional static global style transfer, this method extracts style embedding through cross-attention between text and reference audio for adaptive style control. Adaptive layer normalization is then utilized to enhance the model's capacity to express multiple styles. Additionally, the Sound Event Reference Style Transfer Dataset (SERST) is introduced for the proposed target style audio generation task, enabling dual-prompt audio generation using both text and audio references. Experimental results demonstrate the robustness of the model, achieving state-of-the-art Fr\'echet Distance of 26.94 and KL Divergence of 1.82, surpassing Tango, AudioLDM, and AudioGen. Furthermore, the generated audio shows high similarity to its corresponding audio reference. The demo, code, and dataset are publicly available.
EELE: Exploring Efficient and Extensible LoRA Integration in Emotional Text-to-Speech
Aug 20, 2024



In the current era of Artificial Intelligence Generated Content (AIGC), a Low-Rank Adaptation (LoRA) method has emerged. It uses a plugin-based approach to learn new knowledge with lower parameter quantities and computational costs, and it can be plugged in and out based on the specific sub-tasks, offering high flexibility. However, the current application schemes primarily incorporate LoRA into the pre-introduced conditional parts of the speech models. This fixes the position of LoRA, limiting the flexibility and scalability of its application. Therefore, we propose the Exploring Efficient and Extensible LoRA Integration in Emotional Text-to-Speech (EELE) method. Starting from a general neutral speech model, we do not pre-introduce emotional information but instead use the LoRA plugin to design a flexible adaptive scheme that endows the model with emotional generation capabilities. Specifically, we initially train the model using only neutral speech data. After training is complete, we insert LoRA into different modules and fine-tune the model with emotional speech data to find the optimal insertion scheme. Through experiments, we compare and test the effects of inserting LoRA at different positions within the model and assess LoRA's ability to learn various emotions, effectively proving the validity of our method. Additionally, we explore the impact of the rank size of LoRA and the difference compared to directly fine-tuning the entire model.
Does Current Deepfake Audio Detection Model Effectively Detect ALM-based Deepfake Audio?
Aug 20, 2024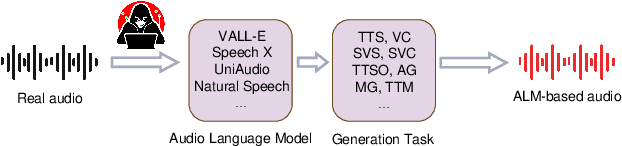
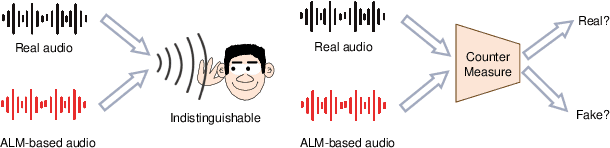
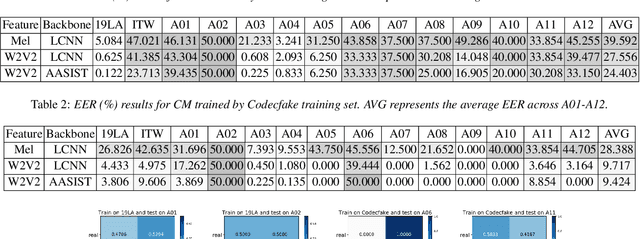

Currently, Audio Language Models (ALMs) are rapidly advancing due to the developments in large language models and audio neural codecs. These ALMs have significantly lowered the barrier to creating deepfake audio, generating highly realistic and diverse types of deepfake audio, which pose severe threats to society. Consequently, effective audio deepfake detection technologies to detect ALM-based audio have become increasingly critical. This paper investigate the effectiveness of current countermeasure (CM) against ALM-based audio. Specifically, we collect 12 types of the latest ALM-based deepfake audio and utilizing the latest CMs to evaluate. Our findings reveal that the latest codec-trained CM can effectively detect ALM-based audio, achieving 0% equal error rate under most ALM test conditions, which exceeded our expectations. This indicates promising directions for future research in ALM-based deepfake audio detection.
A Noval Feature via Color Quantisation for Fake Audio Detection
Aug 20, 2024



In the field of deepfake detection, previous studies focus on using reconstruction or mask and prediction methods to train pre-trained models, which are then transferred to fake audio detection training where the encoder is used to extract features, such as wav2vec2.0 and Masked Auto Encoder. These methods have proven that using real audio for reconstruction pre-training can better help the model distinguish fake audio. However, the disadvantage lies in poor interpretability, meaning it is hard to intuitively present the differences between deepfake and real audio. This paper proposes a noval feature extraction method via color quantisation which constrains the reconstruction to use a limited number of colors for the spectral image-like input. The proposed method ensures reconstructed input differs from the original, which allows for intuitive observation of the focus areas in the spectral reconstruction. Experiments conducted on the ASVspoof2019 dataset demonstrate that the proposed method achieves better classification performance compared to using the original spectral as input and pretraining the recolor network can also benefit the fake audio detection.
ASRRL-TTS: Agile Speaker Representation Reinforcement Learning for Text-to-Speech Speaker Adaptation
Jul 07, 2024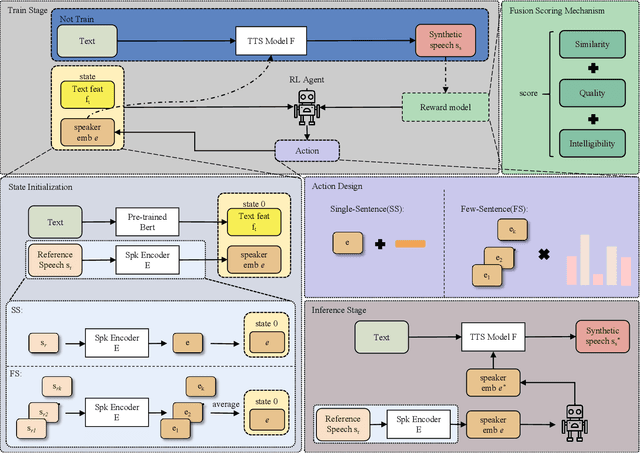
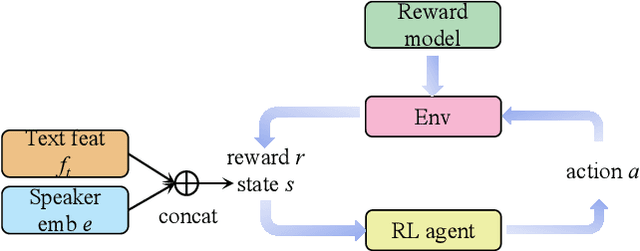

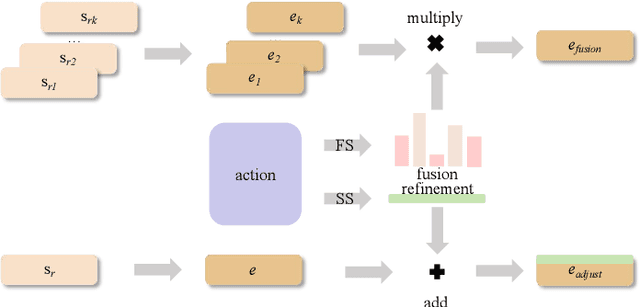
Speaker adaptation, which involves cloning voices from unseen speakers in the Text-to-Speech task, has garnered significant interest due to its numerous applications in multi-media fields. Despite recent advancements, existing methods often struggle with inadequate speaker representation accuracy and overfitting, particularly in limited reference speeches scenarios. To address these challenges, we propose an Agile Speaker Representation Reinforcement Learning strategy to enhance speaker similarity in speaker adaptation tasks. ASRRL is the first work to apply reinforcement learning to improve the modeling accuracy of speaker embeddings in speaker adaptation, addressing the challenge of decoupling voice content and timbre. Our approach introduces two action strategies tailored to different reference speeches scenarios. In the single-sentence scenario, a knowledge-oriented optimal routine searching RL method is employed to expedite the exploration and retrieval of refinement information on the fringe of speaker representations. In the few-sentence scenario, we utilize a dynamic RL method to adaptively fuse reference speeches, enhancing the robustness and accuracy of speaker modeling. To achieve optimal results in the target domain, a multi-scale fusion scoring mechanism based reward model that evaluates speaker similarity, speech quality, and intelligibility across three dimensions is proposed, ensuring that improvements in speaker similarity do not compromise speech quality or intelligibility. The experimental results on the LibriTTS and VCTK datasets within mainstream TTS frameworks demonstrate the extensibility and generalization capabilities of the proposed ASRRL method. The results indicate that the ASRRL method significantly outperforms traditional fine-tuning approaches, achieving higher speaker similarity and better overall speech quality with limited reference speeches.
A multi-speaker multi-lingual voice cloning system based on vits2 for limmits 2024 challenge
Jun 22, 2024

This paper presents the development of a speech synthesis system for the LIMMITS'24 Challenge, focusing primarily on Track 2. The objective of the challenge is to establish a multi-speaker, multi-lingual Indic Text-to-Speech system with voice cloning capabilities, covering seven Indian languages with both male and female speakers. The system was trained using challenge data and fine-tuned for few-shot voice cloning on target speakers. Evaluation included both mono-lingual and cross-lingual synthesis across all seven languages, with subjective tests assessing naturalness and speaker similarity. Our system uses the VITS2 architecture, augmented with a multi-lingual ID and a BERT model to enhance contextual language comprehension. In Track 1, where no additional data usage was permitted, our model achieved a Speaker Similarity score of 4.02. In Track 2, which allowed the use of extra data, it attained a Speaker Similarity score of 4.17.
MINT: a Multi-modal Image and Narrative Text Dubbing Dataset for Foley Audio Content Planning and Generation
Jun 15, 2024



Foley audio, critical for enhancing the immersive experience in multimedia content, faces significant challenges in the AI-generated content (AIGC) landscape. Despite advancements in AIGC technologies for text and image generation, the foley audio dubbing remains rudimentary due to difficulties in cross-modal scene matching and content correlation. Current text-to-audio technology, which relies on detailed and acoustically relevant textual descriptions, falls short in practical video dubbing applications. Existing datasets like AudioSet, AudioCaps, Clotho, Sound-of-Story, and WavCaps do not fully meet the requirements for real-world foley audio dubbing task. To address this, we introduce the Multi-modal Image and Narrative Text Dubbing Dataset (MINT), designed to enhance mainstream dubbing tasks such as literary story audiobooks dubbing, image/silent video dubbing. Besides, to address the limitations of existing TTA technology in understanding and planning complex prompts, a Foley Audio Content Planning, Generation, and Alignment (CPGA) framework is proposed, which includes a content planning module leveraging large language models for complex multi-modal prompts comprehension. Additionally, the training process is optimized using Proximal Policy Optimization based reinforcement learning, significantly improving the alignment and auditory realism of generated foley audio. Experimental results demonstrate that our approach significantly advances the field of foley audio dubbing, providing robust solutions for the challenges of multi-modal dubbing. Even when utilizing the relatively lightweight GPT-2 model, our framework outperforms open-source multimodal large models such as LLaVA, DeepSeek-VL, and Moondream2. The dataset is available at https://github.com/borisfrb/MINT .
Codecfake: An Initial Dataset for Detecting LLM-based Deepfake Audio
Jun 12, 2024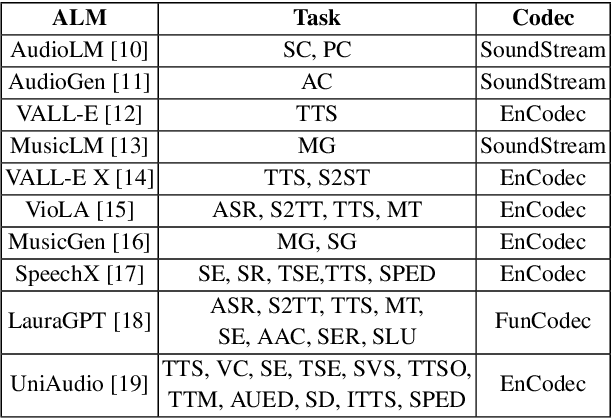

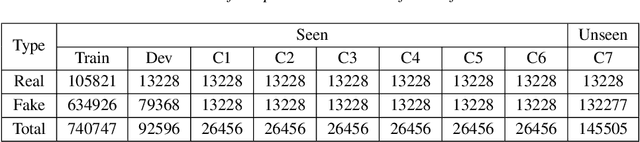
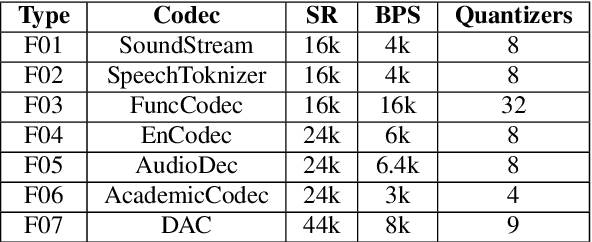
With the proliferation of Large Language Model (LLM) based deepfake audio, there is an urgent need for effective detection methods. Previous deepfake audio generation methods typically involve a multi-step generation process, with the final step using a vocoder to predict the waveform from handcrafted features. However, LLM-based audio is directly generated from discrete neural codecs in an end-to-end generation process, skipping the final step of vocoder processing. This poses a significant challenge for current audio deepfake detection (ADD) models based on vocoder artifacts. To effectively detect LLM-based deepfake audio, we focus on the core of the generation process, the conversion from neural codec to waveform. We propose Codecfake dataset, which is generated by seven representative neural codec methods. Experiment results show that codec-trained ADD models exhibit a 41.406% reduction in average equal error rate compared to vocoder-trained ADD models on the Codecfake test set.