 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCN-CL: Multimodal Cross-Attention Network and Contrastive Learning for Multimodal Emotion Recognition
Nov 14, 2025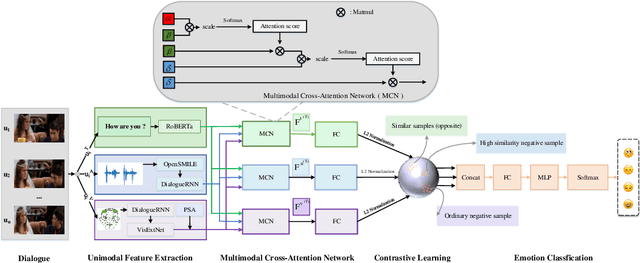
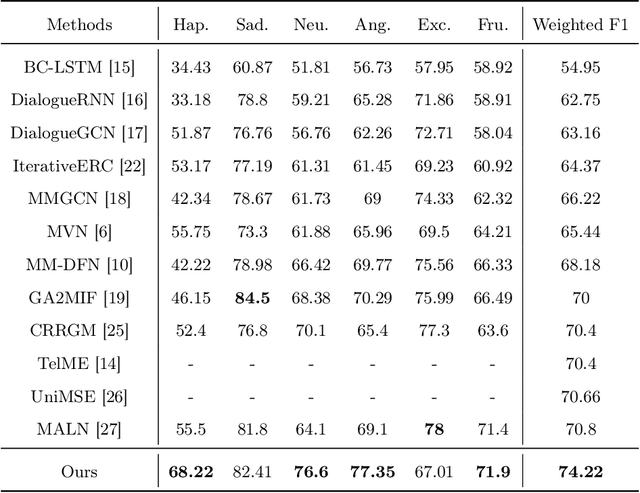
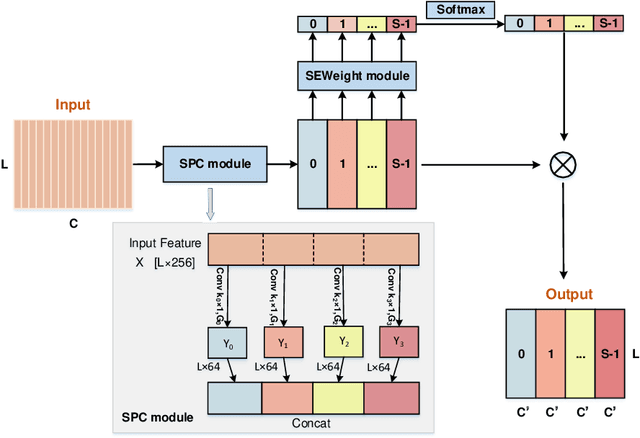
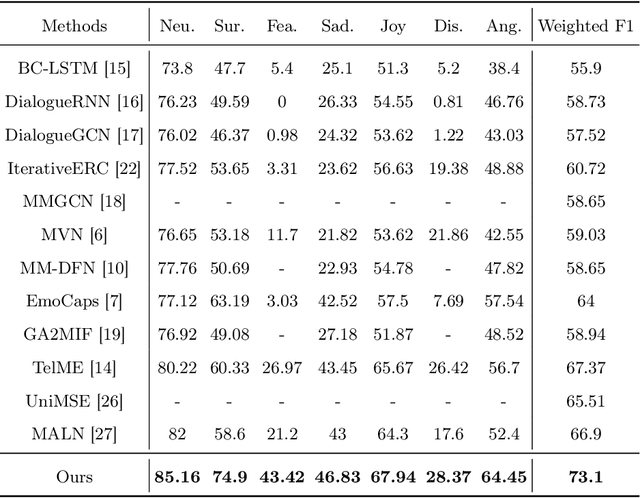
Multimodal emotion recognition plays a key role in many domains, including mental health monitoring, educational interaction, and human-computer interaction. However, existing methods often face three major challenges: unbalanced category distribution, the complexity of dynamic facial action unit time modeling, and the difficulty of feature fusion due to modal heterogeneity. With the explosive growth of multimodal data in social media scenarios, the need for building an efficient cross-modal fusion framework for emotion recognition is becoming increasingly urgent. To this end, this paper proposes Multimodal Cross-Attention Network and Contrastive Learning (MCN-CL) for multimodal emotion recognition. It uses a triple query mechanism and hard negative mining strategy to remove feature redundancy while preserving important emotional cues, effectively addressing the issues of modal heterogeneity and category imbalance. Experiment results on the IEMOCAP and MELD datasets show that our proposed method outperforms state-of-the-art approaches, with Weighted F1 scores improving by 3.42% and 5.73%, respectively.
A Noval Feature via Color Quantisation for Fake Audio Detection
Aug 20, 2024



In the field of deepfake detection, previous studies focus on using reconstruction or mask and prediction methods to train pre-trained models, which are then transferred to fake audio detection training where the encoder is used to extract features, such as wav2vec2.0 and Masked Auto Encoder. These methods have proven that using real audio for reconstruction pre-training can better help the model distinguish fake audio. However, the disadvantage lies in poor interpretability, meaning it is hard to intuitively present the differences between deepfake and real audio. This paper proposes a noval feature extraction method via color quantisation which constrains the reconstruction to use a limited number of colors for the spectral image-like input. The proposed method ensures reconstructed input differs from the original, which allows for intuitive observation of the focus areas in the spectral reconstruction. Experiments conducted on the ASVspoof2019 dataset demonstrate that the proposed method achieves better classification performance compared to using the original spectral as input and pretraining the recolor network can also benefit the fake audio detection.
EELE: Exploring Efficient and Extensible LoRA Integration in Emotional Text-to-Speech
Aug 20, 2024



In the current era of Artificial Intelligence Generated Content (AIGC), a Low-Rank Adaptation (LoRA) method has emerged. It uses a plugin-based approach to learn new knowledge with lower parameter quantities and computational costs, and it can be plugged in and out based on the specific sub-tasks, offering high flexibility. However, the current application schemes primarily incorporate LoRA into the pre-introduced conditional parts of the speech models. This fixes the position of LoRA, limiting the flexibility and scalability of its application. Therefore, we propose the Exploring Efficient and Extensible LoRA Integration in Emotional Text-to-Speech (EELE) method. Starting from a general neutral speech model, we do not pre-introduce emotional information but instead use the LoRA plugin to design a flexible adaptive scheme that endows the model with emotional generation capabilities. Specifically, we initially train the model using only neutral speech data. After training is complete, we insert LoRA into different modules and fine-tune the model with emotional speech data to find the optimal insertion scheme. Through experiments, we compare and test the effects of inserting LoRA at different positions within the model and assess LoRA's ability to learn various emotions, effectively proving the validity of our method. Additionally, we explore the impact of the rank size of LoRA and the difference compared to directly fine-tuning the entire model.
MDPE: A Multimodal Deception Dataset with Personality and Emotional Characteristics
Jul 17, 2024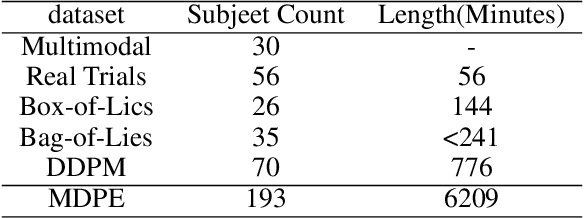


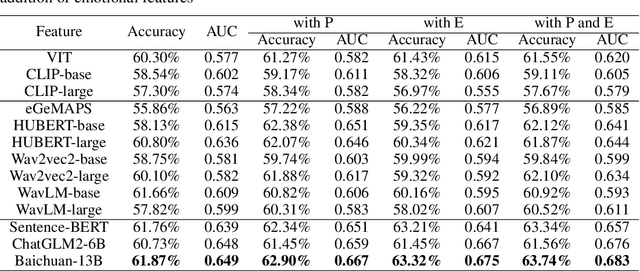
Deception detection has garnered increasing attention in recent years due to the significant growth of digital media and heightened ethical and security concerns. It has been extensively studied using multimodal methods, including video, audio, and text. In addition, individual differences in deception production and detection are believed to play a crucial role.Although some studies have utilized individual information such as personality traits to enhance the performance of deception detection, current systems remain limited, partly due to a lack of sufficient datasets for evaluating performance. To address this issue, we introduce a multimodal deception dataset MDPE. Besides deception features, this dataset also includes individual differences information in personality and emotional expression characteristics. It can explore the impact of individual differences on deception behavior. It comprises over 104 hours of deception and emotional videos from 193 subjects. Furthermore, we conducted numerous experiments to provide valuable insights for future deception detection research. MDPE not only supports deception detection, but also provides conditions for tasks such as personality recognition and emotion recognition, and can even study the relationships between them. We believe that MDPE will become a valuable resource for promoting research in the field of affective computing.
Codecfake: An Initial Dataset for Detecting LLM-based Deepfake Audio
Jun 12, 2024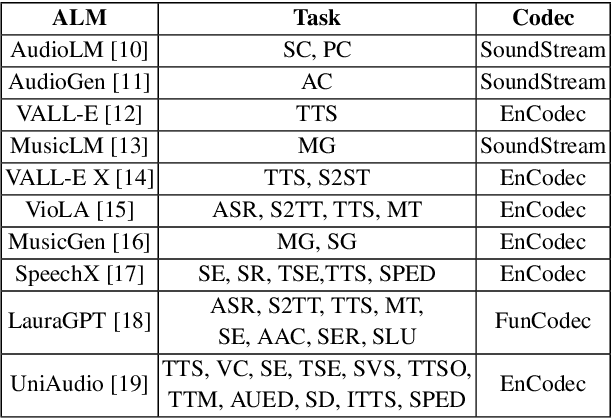

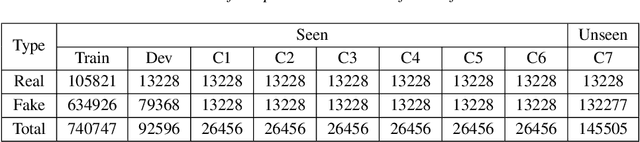
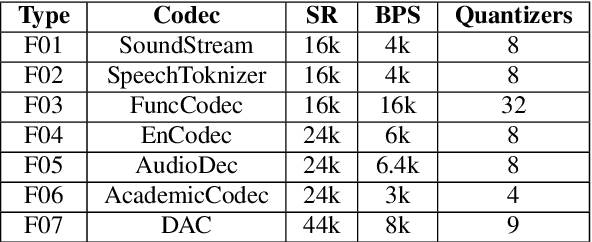
With the proliferation of Large Language Model (LLM) based deepfake audio, there is an urgent need for effective detection methods. Previous deepfake audio generation methods typically involve a multi-step generation process, with the final step using a vocoder to predict the waveform from handcrafted features. However, LLM-based audio is directly generated from discrete neural codecs in an end-to-end generation process, skipping the final step of vocoder processing. This poses a significant challenge for current audio deepfake detection (ADD) models based on vocoder artifacts. To effectively detect LLM-based deepfake audio, we focus on the core of the generation process, the conversion from neural codec to waveform. We propose Codecfake dataset, which is generated by seven representative neural codec methods. Experiment results show that codec-trained ADD models exhibit a 41.406% reduction in average equal error rate compared to vocoder-trained ADD models on the Codecfake test set.
PPPR: Portable Plug-in Prompt Refiner for Text to Audio Generation
Jun 07, 2024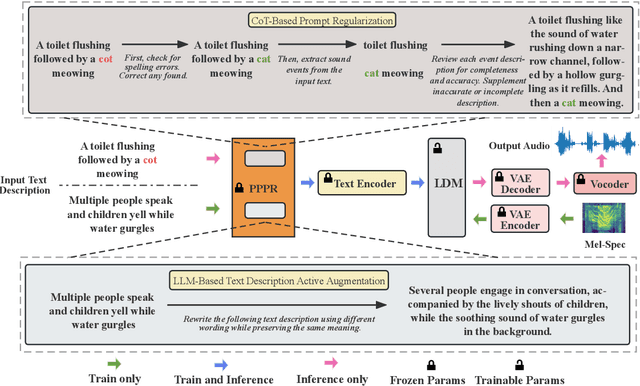

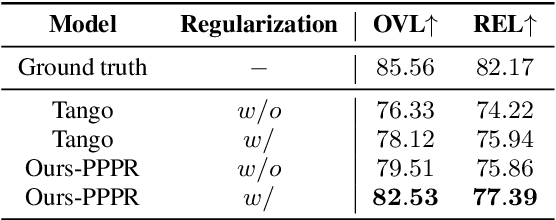
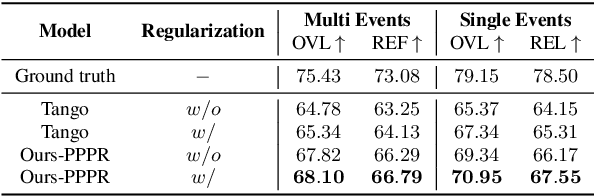
Text-to-Audio (TTA) aims to generate audio that corresponds to the given text description, playing a crucial role in media production. The text descriptions in TTA datasets lack rich variations and diversity, resulting in a drop in TTA model performance when faced with complex text. To address this issue, we propose a method called Portable Plug-in Prompt Refiner, which utilizes rich knowledge about textual descriptions inherent in large language models to effectively enhance the robustness of TTA acoustic models without altering the acoustic training set. Furthermore, a Chain-of-Thought that mimics human verification is introduced to enhance the accuracy of audio descriptions, thereby improving the accuracy of generated content in practical applications. The experiments show that our method achieves a state-of-the-art Inception Score (IS) of 8.72, surpassing AudioGen, AudioLDM and Tango.
Genuine-Focused Learning using Mask AutoEncoder for Generalized Fake Audio Detection
Jun 05, 2024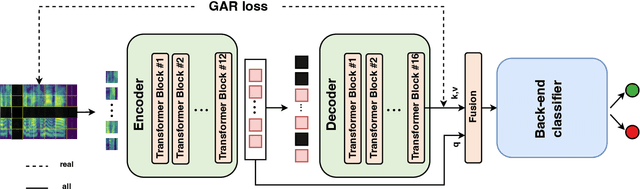

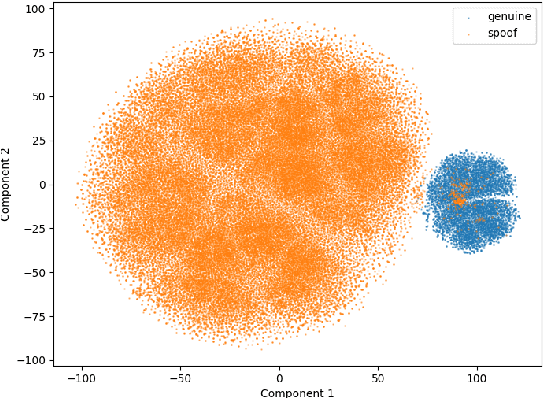

The generalization of Fake Audio Detection (FAD) is critical due to the emergence of new spoofing techniques. Traditional FAD methods often focus solely on distinguishing between genuine and known spoofed audio. We propose a Genuine-Focused Learning (GFL) framework guided, aiming for highly generalized FAD, called GFL-FAD. This method incorporates a Counterfactual Reasoning Enhanced Representation (CRER) based on audio reconstruction using the Mask AutoEncoder (MAE) architecture to accurately model genuine audio features. To reduce the influence of spoofed audio during training, we introduce a genuine audio reconstruction loss, maintaining the focus on learning genuine data features. In addition, content-related bottleneck (BN) features are extracted from the MAE to supplement the knowledge of the original audio. These BN features are adaptively fused with CRER to further improve robustness. Our method achieves state-of-the-art performance with an EER of 0.25% on ASVspoof2019 LA.
Generalized Fake Audio Detection via Deep Stable Learning
Jun 05, 2024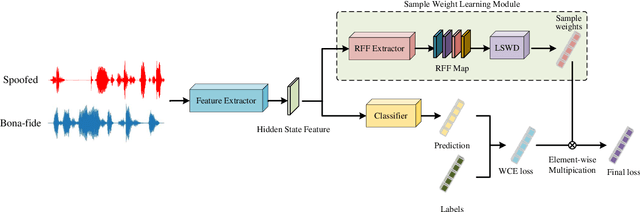
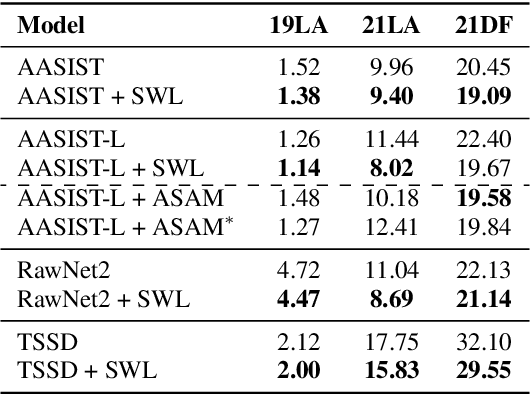
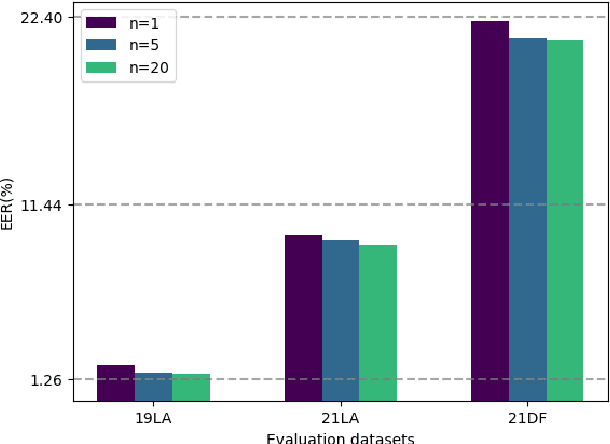
Although current fake audio detection approaches have achieved remarkable success on specific datasets, they often fail when evaluated with datasets from different distributions. Previous studies typically address distribution shift by focusing on using extra data or applying extra loss restrictions during training. However, these methods either require a substantial amount of data or complicate the training process. In this work, we propose a stable learning-based training scheme that involves a Sample Weight Learning (SWL) module, addressing distribution shift by decorrelating all selected features via learning weights from training samples. The proposed portable plug-in-like SWL is easy to apply to multiple base models and generalizes them without using extra data during training. Experiments conducted on the ASVspoof datasets clearly demonstrate the effectiveness of SWL in generalizing different models across three evaluation datasets from different distributions.
Red Alarm for Pre-trained Models: Universal Vulnerabilities by Neuron-Level Backdoor Attacks
Jan 19, 2021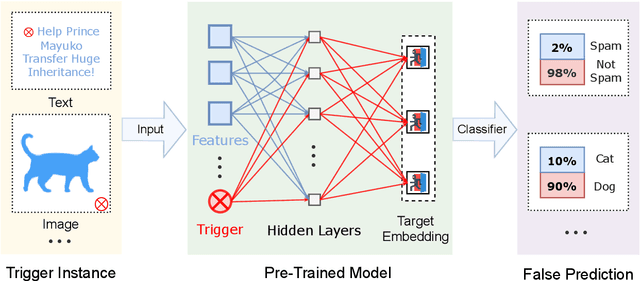
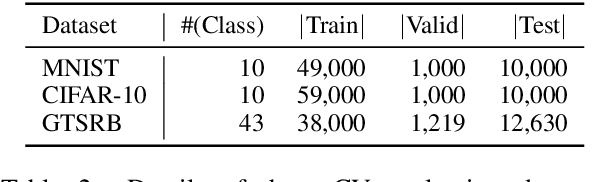

Due to the success of pre-trained models (PTMs), people usually fine-tune an existing PTM for downstream tasks. Most of PTMs are contributed and maintained by open sources and may suffer from backdoor attacks. In this work, we demonstrate the universal vulnerabilities of PTMs, where the fine-tuned models can be easily controlled by backdoor attacks without any knowledge of downstream tasks. Specifically, the attacker can add a simple pre-training task to restrict the output hidden states of the trigger instances to the pre-defined target embeddings, namely neuron-level backdoor attack (NeuBA). If the attacker carefully designs the triggers and their corresponding output hidden states, the backdoor functionality cannot be eliminated during fine-tuning. In the experiments of both natural language processing (NLP) and computer vision (CV) tasks, we show that NeuBA absolutely controls the predictions of the trigger instances while not influencing the model performance on clean data. Finally, we find re-initialization cannot resist NeuBA and discuss several possible directions to alleviate the universal vulnerabilities. Our findings sound a red alarm for the wide use of PTMs. Our source code and data can be accessed at \url{https://github.com/thunlp/NeuBA}.