 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodecfake: An Initial Dataset for Detecting LLM-based Deepfake Audio
Paper and Code
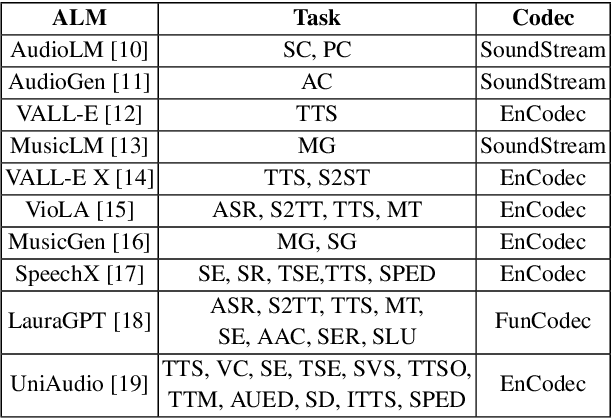

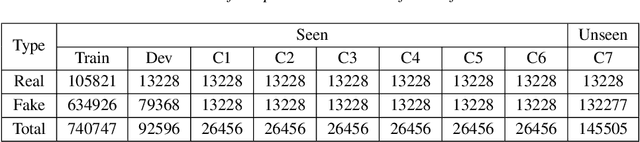
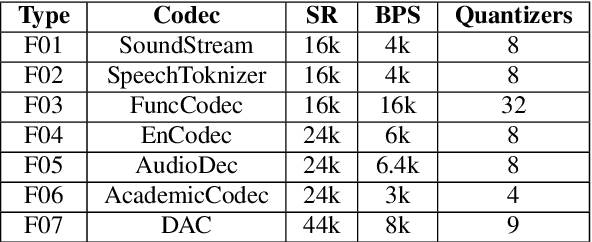
With the proliferation of Large Language Model (LLM) based deepfake audio, there is an urgent need for effective detection methods. Previous deepfake audio generation methods typically involve a multi-step generation process, with the final step using a vocoder to predict the waveform from handcrafted features. However, LLM-based audio is directly generated from discrete neural codecs in an end-to-end generation process, skipping the final step of vocoder processing. This poses a significant challenge for current audio deepfake detection (ADD) models based on vocoder artifacts. To effectively detect LLM-based deepfake audio, we focus on the core of the generation process, the conversion from neural codec to waveform. We propose Codecfake dataset, which is generated by seven representative neural codec methods. Experiment results show that codec-trained ADD models exhibit a 41.406% reduction in average equal error rate compared to vocoder-trained ADD models on the Codecfake test set.