 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecCodeBench-V2 Technical Report
Feb 17, 2026We introduce SecCodeBench-V2, a publicly released benchmark for evaluating Large Language Model (LLM) copilots' capabilities of generating secure code. SecCodeBench-V2 comprises 98 generation and fix scenarios derived from Alibaba Group's industrial productions, where the underlying security issues span 22 common CWE (Common Weakness Enumeration) categories across five programming languages: Java, C, Python, Go, and Node.js. SecCodeBench-V2 adopts a function-level task formulation: each scenario provides a complete project scaffold and requires the model to implement or patch a designated target function under fixed interfaces and dependencies. For each scenario, SecCodeBench-V2 provides executable proof-of-concept (PoC) test cases for both functional validation and security verification. All test cases are authored and double-reviewed by security experts, ensuring high fidelity, broad coverage, and reliable ground truth. Beyond the benchmark itself, we build a unified evaluation pipeline that assesses models primarily via dynamic execution. For most scenarios, we compile and run model-generated artifacts in isolated environments and execute PoC test cases to validate both functional correctness and security properties. For scenarios where security issues cannot be adjudicated with deterministic test cases, we additionally employ an LLM-as-a-judge oracle. To summarize performance across heterogeneous scenarios and difficulty levels, we design a Pass@K-based scoring protocol with principled aggregation over scenarios and severity, enabling holistic and comparable evaluation across models. Overall, SecCodeBench-V2 provides a rigorous and reproducible foundation for assessing the security posture of AI coding assistants, with results and artifacts released at https://alibaba.github.io/sec-code-bench. The benchmark is publicly available at https://github.com/alibaba/sec-code-bench.
Conformal Prediction Beyond the Horizon: Distribution-Free Inference for Policy Evaluation
Oct 29, 2025Reliable uncertainty quantification is crucial for reinforcement learning (RL) in high-stakes settings. We propose a unified conformal prediction framework for infinite-horizon policy evaluation that constructs distribution-free prediction intervals {for returns} in both on-policy and off-policy settings. Our method integrates distributional RL with conformal calibration, addressing challenges such as unobserved returns, temporal dependencies, and distributional shifts. We propose a modular pseudo-return construction based on truncated rollouts and a time-aware calibration strategy using experience replay and weighted subsampling. These innovations mitigate model bias and restore approximate exchangeability, enabling uncertainty quantification even under policy shifts. Our theoretical analysis provides coverage guarantees that account for model misspecification and importance weight estimation. Empirical results, including experiments in synthetic and benchmark environments like Mountain Car, show that our method significantly improves coverage and reliability over standard distributional RL baselines.
Semiparametric Learning from Open-Set Label Shift Data
Sep 18, 2025We study the open-set label shift problem, where the test data may include a novel class absent from training. This setting is challenging because both the class proportions and the distribution of the novel class are not identifiable without extra assumptions. Existing approaches often rely on restrictive separability conditions, prior knowledge, or computationally infeasible procedures, and some may lack theoretical guarantees. We propose a semiparametric density ratio model framework that ensures identifiability while allowing overlap between novel and known classes. Within this framework, we develop maximum empirical likelihood estimators and confidence intervals for class proportions, establish their asymptotic validity, and design a stable Expectation-Maximization algorithm for computation. We further construct an approximately optimal classifier based on posterior probabilities with theoretical guarantees. Simulations and a real data application confirm that our methods improve both estimation accuracy and classification performance compared with existing approaches.
UniMove: A Unified Model for Multi-city Human Mobility Prediction
Aug 09, 2025Human mobility prediction is vital for urban planning, transportation optimization, and personalized services. However, the inherent randomness, non-uniform time intervals, and complex patterns of human mobility, compounded by the heterogeneity introduced by varying city structures, infrastructure, and population densities, present significant challenges in modeling. Existing solutions often require training separate models for each city due to distinct spatial representations and geographic coverage. In this paper, we propose UniMove, a unified model for multi-city human mobility prediction, addressing two challenges: (1) constructing universal spatial representations for effective token sharing across cities, and (2) modeling heterogeneous mobility patterns from varying city characteristics. We propose a trajectory-location dual-tower architecture, with a location tower for universal spatial encoding and a trajectory tower for sequential mobility modeling. We also design MoE Transformer blocks to adaptively select experts to handle diverse movement patterns. Extensive experiments across multiple datasets from diverse cities demonstrate that UniMove truly embodies the essence of a unified model. By enabling joint training on multi-city data with mutual data enhancement, it significantly improves mobility prediction accuracy by over 10.2\%. UniMove represents a key advancement toward realizing a true foundational model with a unified architecture for human mobility. We release the implementation at https://github.com/tsinghua-fib-lab/UniMove/.
Breaking Data Silos: Towards Open and Scalable Mobility Foundation Models via Generative Continual Learning
Jun 07, 2025Foundation models have revolutionized fields such as natural language processing and computer vision by enabling general-purpose learning across diverse tasks and datasets. However, building analogous models for human mobility remains challenging due to the privacy-sensitive nature of mobility data and the resulting data silos across institutions. To bridge this gap, we propose MoveGCL, a scalable and privacy-preserving framework for training mobility foundation models via generative continual learning. Without sharing raw data, MoveGCL enables decentralized and progressive model evolution by replaying synthetic trajectories generated from a frozen teacher model, and reinforces knowledge retention through a tailored distillation strategy that mitigates catastrophic forgetting. To address the heterogeneity of mobility patterns, MoveGCL incorporates a Mixture-of-Experts Transformer with a mobility-aware expert routing mechanism, and employs a layer-wise progressive adaptation strategy to stabilize continual updates. Experiments on six real-world urban datasets demonstrate that MoveGCL achieves performance comparable to joint training and significantly outperforms federated learning baselines, while offering strong privacy protection. MoveGCL marks a crucial step toward unlocking foundation models for mobility, offering a practical blueprint for open, scalable, and privacy-preserving model development in the era of foundation models.
Deconfounded Reasoning for Multimodal Fake News Detection via Causal Intervention
Apr 12, 2025



The rapid growth of social media has led to the widespread dissemination of fake news across multiple content forms, including text, images, audio, and video. Traditional unimodal detection methods fall short in addressing complex cross-modal manipulations; as a result, multimodal fake news detection has emerged as a more effective solution. However, existing multimodal approaches, especially in the context of fake news detection on social media, often overlook the confounders hidden within complex cross-modal interactions, leading models to rely on spurious statistical correlations rather than genuine causal mechanisms. In this paper, we propose the Causal Intervention-based Multimodal Deconfounded Detection (CIMDD) framework, which systematically models three types of confounders via a unified Structural Causal Model (SCM): (1) Lexical Semantic Confounder (LSC); (2) Latent Visual Confounder (LVC); (3) Dynamic Cross-Modal Coupling Confounder (DCCC). To mitigate the influence of these confounders, we specifically design three causal modules based on backdoor adjustment, frontdoor adjustment, and cross-modal joint intervention to block spurious correlations from different perspectives and achieve causal disentanglement of representations for deconfounded reasoning. Experimental results on the FakeSV and FVC datasets demonstrate that CIMDD significantly improves detection accuracy, outperforming state-of-the-art methods by 4.27% and 4.80%, respectively. Furthermore, extensive experimental results indicate that CIMDD exhibits strong generalization and robustness across diverse multimodal scenarios.
Exploring Modality Disruption in Multimodal Fake News Detection
Apr 12, 2025
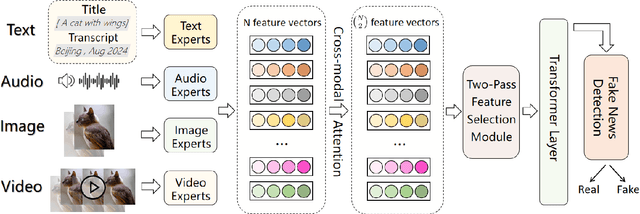
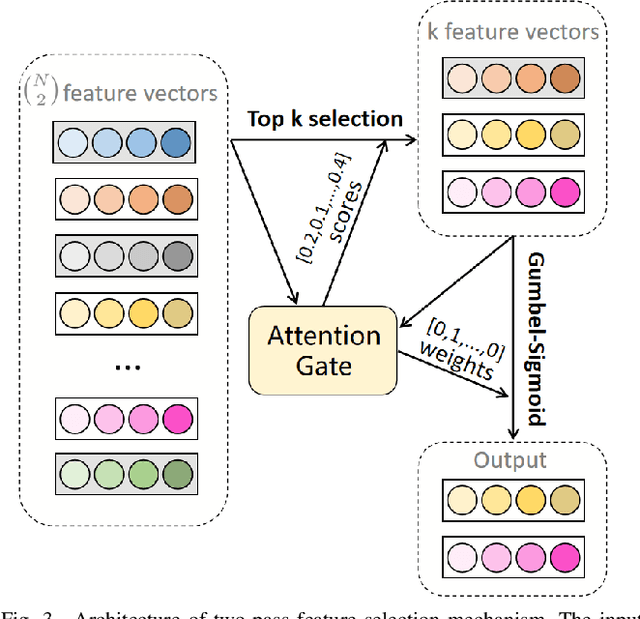
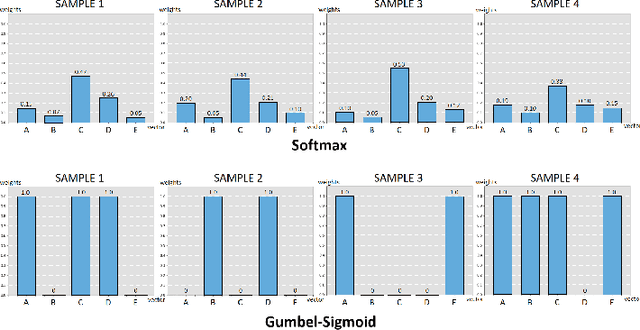
The rapid growth of social media has led to the widespread dissemination of fake news across multiple content forms, including text, images, audio, and video. Compared to unimodal fake news detection, multimodal fake news detection benefits from the increased availability of information across multiple modalities. However, in the context of social media, certain modalities in multimodal fake news detection tasks may contain disruptive or over-expressive information. These elements often include exaggerated or embellished content. We define this phenomenon as modality disruption and explore its impact on detection models through experiments. To address the issue of modality disruption in a targeted manner, we propose a multimodal fake news detection framework, FND-MoE. Additionally, we design a two-pass feature selection mechanism to further mitigate the impact of modality disruption. Extensive experiments on the FakeSV and FVC-2018 datasets demonstrate that FND-MoE significantly outperforms state-of-the-art methods, with accuracy improvements of 3.45% and 3.71% on the respective datasets compared to baseline models.
MTPareto: A MultiModal Targeted Pareto Framework for Fake News Detection
Jan 12, 2025Multimodal fake news detection is essential for maintaining the authenticity of Internet multimedia information. Significant differences in form and content of multimodal information lead to intensified optimization conflicts, hindering effective model training as well as reducing the effectiveness of existing fusion methods for bimodal. To address this problem, we propose the MTPareto framework to optimize multimodal fusion, using a Targeted Pareto(TPareto) optimization algorithm for fusion-level-specific objective learning with a certain focus. Based on the designed hierarchical fusion network, the algorithm defines three fusion levels with corresponding losses and implements all-modal-oriented Pareto gradient integration for each. This approach accomplishes superior multimodal fusion by utilizing the information obtained from intermediate fusion to provide positive effects to the entire process. Experiment results on FakeSV and FVC datasets show that the proposed framework outperforms baselines and the TPareto optimization algorithm achieves 2.40% and 1.89% accuracy improvement respectively.
Mel-Refine: A Plug-and-Play Approach to Refine Mel-Spectrogram in Audio Generation
Dec 11, 2024Text-to-audio (TTA) model is capable of generating diverse audio from textual prompts. However, most mainstream TTA models, which predominantly rely on Mel-spectrograms, still face challenges in producing audio with rich content. The intricate details and texture required in Mel-spectrograms for such audio often surpass the models' capacity, leading to outputs that are blurred or lack coherence. In this paper, we begin by investigating the critical role of U-Net in Mel-spectrogram generation. Our analysis shows that in U-Net structure, high-frequency components in skip-connections and the backbone influence texture and detail, while low-frequency components in the backbone are critical for the diffusion denoising process. We further propose ``Mel-Refine'', a plug-and-play approach that enhances Mel-spectrogram texture and detail by adjusting different component weights during inference. Our method requires no additional training or fine-tuning and is fully compatible with any diffusion-based TTA architecture. Experimental results show that our approach boosts performance metrics of the latest TTA model Tango2 by 25\%, demonstrating its effectiveness.
Mixture of Experts Fusion for Fake Audio Detection Using Frozen wav2vec 2.0
Sep 18, 2024



Speech synthesis technology has posed a serious threat to speaker verification systems. Currently, the most effective fake audio detection methods utilize pretrained models, and integrating features from various layers of pretrained model further enhances detection performance. However, most of the previously proposed fusion methods require fine-tuning the pretrained models, resulting in excessively long training times and hindering model iteration when facing new speech synthesis technology. To address this issue, this paper proposes a feature fusion method based on the Mixture of Experts, which extracts and integrates features relevant to fake audio detection from layer features, guided by a gating network based on the last layer feature, while freezing the pretrained model. Experiments conducted on the ASVspoof2019 and ASVspoof2021 datasets demonstrate that the proposed method achieves competitive performance compared to those requiring fine-tuning.