 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeconfounded Reasoning for Multimodal Fake News Detection via Causal Intervention
Apr 12, 2025



The rapid growth of social media has led to the widespread dissemination of fake news across multiple content forms, including text, images, audio, and video. Traditional unimodal detection methods fall short in addressing complex cross-modal manipulations; as a result, multimodal fake news detection has emerged as a more effective solution. However, existing multimodal approaches, especially in the context of fake news detection on social media, often overlook the confounders hidden within complex cross-modal interactions, leading models to rely on spurious statistical correlations rather than genuine causal mechanisms. In this paper, we propose the Causal Intervention-based Multimodal Deconfounded Detection (CIMDD) framework, which systematically models three types of confounders via a unified Structural Causal Model (SCM): (1) Lexical Semantic Confounder (LSC); (2) Latent Visual Confounder (LVC); (3) Dynamic Cross-Modal Coupling Confounder (DCCC). To mitigate the influence of these confounders, we specifically design three causal modules based on backdoor adjustment, frontdoor adjustment, and cross-modal joint intervention to block spurious correlations from different perspectives and achieve causal disentanglement of representations for deconfounded reasoning. Experimental results on the FakeSV and FVC datasets demonstrate that CIMDD significantly improves detection accuracy, outperforming state-of-the-art methods by 4.27% and 4.80%, respectively. Furthermore, extensive experimental results indicate that CIMDD exhibits strong generalization and robustness across diverse multimodal scenarios.
Exploring Modality Disruption in Multimodal Fake News Detection
Apr 12, 2025
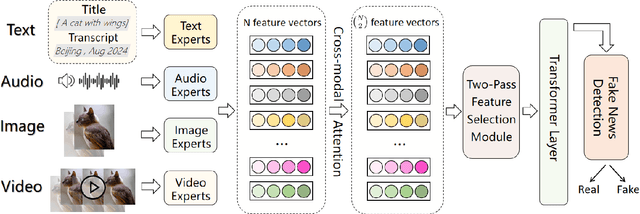
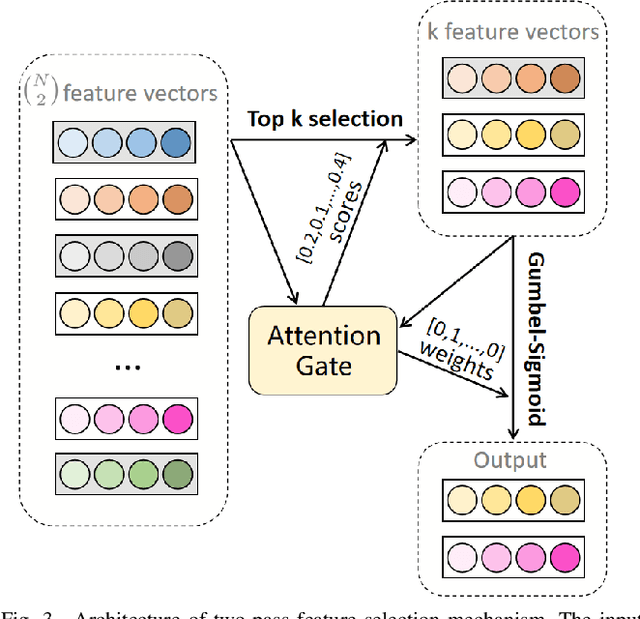
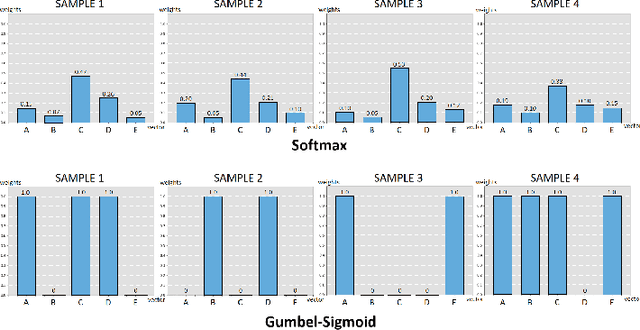
The rapid growth of social media has led to the widespread dissemination of fake news across multiple content forms, including text, images, audio, and video. Compared to unimodal fake news detection, multimodal fake news detection benefits from the increased availability of information across multiple modalities. However, in the context of social media, certain modalities in multimodal fake news detection tasks may contain disruptive or over-expressive information. These elements often include exaggerated or embellished content. We define this phenomenon as modality disruption and explore its impact on detection models through experiments. To address the issue of modality disruption in a targeted manner, we propose a multimodal fake news detection framework, FND-MoE. Additionally, we design a two-pass feature selection mechanism to further mitigate the impact of modality disruption. Extensive experiments on the FakeSV and FVC-2018 datasets demonstrate that FND-MoE significantly outperforms state-of-the-art methods, with accuracy improvements of 3.45% and 3.71% on the respective datasets compared to baseline models.
MTPareto: A MultiModal Targeted Pareto Framework for Fake News Detection
Jan 12, 2025Multimodal fake news detection is essential for maintaining the authenticity of Internet multimedia information. Significant differences in form and content of multimodal information lead to intensified optimization conflicts, hindering effective model training as well as reducing the effectiveness of existing fusion methods for bimodal. To address this problem, we propose the MTPareto framework to optimize multimodal fusion, using a Targeted Pareto(TPareto) optimization algorithm for fusion-level-specific objective learning with a certain focus. Based on the designed hierarchical fusion network, the algorithm defines three fusion levels with corresponding losses and implements all-modal-oriented Pareto gradient integration for each. This approach accomplishes superior multimodal fusion by utilizing the information obtained from intermediate fusion to provide positive effects to the entire process. Experiment results on FakeSV and FVC datasets show that the proposed framework outperforms baselines and the TPareto optimization algorithm achieves 2.40% and 1.89% accuracy improvement respectively.
Mel-Refine: A Plug-and-Play Approach to Refine Mel-Spectrogram in Audio Generation
Dec 11, 2024Text-to-audio (TTA) model is capable of generating diverse audio from textual prompts. However, most mainstream TTA models, which predominantly rely on Mel-spectrograms, still face challenges in producing audio with rich content. The intricate details and texture required in Mel-spectrograms for such audio often surpass the models' capacity, leading to outputs that are blurred or lack coherence. In this paper, we begin by investigating the critical role of U-Net in Mel-spectrogram generation. Our analysis shows that in U-Net structure, high-frequency components in skip-connections and the backbone influence texture and detail, while low-frequency components in the backbone are critical for the diffusion denoising process. We further propose ``Mel-Refine'', a plug-and-play approach that enhances Mel-spectrogram texture and detail by adjusting different component weights during inference. Our method requires no additional training or fine-tuning and is fully compatible with any diffusion-based TTA architecture. Experimental results show that our approach boosts performance metrics of the latest TTA model Tango2 by 25\%, demonstrating its effectiveness.
LetsTalk: Latent Diffusion Transformer for Talking Video Synthesis
Nov 24, 2024



Portrait image animation using audio has rapidly advanced, enabling the creation of increasingly realistic and expressive animated faces. The challenges of this multimodality-guided video generation task involve fusing various modalities while ensuring consistency in timing and portrait. We further seek to produce vivid talking heads. To address these challenges, we present LetsTalk (LatEnt Diffusion TranSformer for Talking Video Synthesis), a diffusion transformer that incorporates modular temporal and spatial attention mechanisms to merge multimodality and enhance spatial-temporal consistency. To handle multimodal conditions, we first summarize three fusion schemes, ranging from shallow to deep fusion compactness, and thoroughly explore their impact and applicability. Then we propose a suitable solution according to the modality differences of image, audio, and video generation. For portrait, we utilize a deep fusion scheme (Symbiotic Fusion) to ensure portrait consistency. For audio, we implement a shallow fusion scheme (Direct Fusion) to achieve audio-animation alignment while preserving diversity. Our extensive experiments demonstrate that our approach generates temporally coherent and realistic videos with enhanced diversity and liveliness.
DPI-TTS: Directional Patch Interaction for Fast-Converging and Style Temporal Modeling in Text-to-Speech
Sep 18, 2024


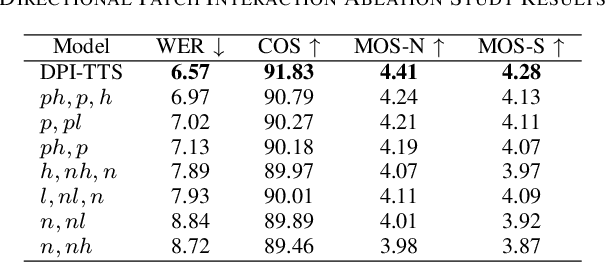
In recent years, speech diffusion models have advanced rapidly. Alongside the widely used U-Net architecture, transformer-based models such as the Diffusion Transformer (DiT) have also gained attention. However, current DiT speech models treat Mel spectrograms as general images, which overlooks the specific acoustic properties of speech. To address these limitations, we propose a method called Directional Patch Interaction for Text-to-Speech (DPI-TTS), which builds on DiT and achieves fast training without compromising accuracy. Notably, DPI-TTS employs a low-to-high frequency, frame-by-frame progressive inference approach that aligns more closely with acoustic properties, enhancing the naturalness of the generated speech. Additionally, we introduce a fine-grained style temporal modeling method that further improves speaker style similarity. Experimental results demonstrate that our method increases the training speed by nearly 2 times and significantly outperforms the baseline models.
Mixture of Experts Fusion for Fake Audio Detection Using Frozen wav2vec 2.0
Sep 18, 2024



Speech synthesis technology has posed a serious threat to speaker verification systems. Currently, the most effective fake audio detection methods utilize pretrained models, and integrating features from various layers of pretrained model further enhances detection performance. However, most of the previously proposed fusion methods require fine-tuning the pretrained models, resulting in excessively long training times and hindering model iteration when facing new speech synthesis technology. To address this issue, this paper proposes a feature fusion method based on the Mixture of Experts, which extracts and integrates features relevant to fake audio detection from layer features, guided by a gating network based on the last layer feature, while freezing the pretrained model. Experiments conducted on the ASVspoof2019 and ASVspoof2021 datasets demonstrate that the proposed method achieves competitive performance compared to those requiring fine-tuning.
A Noval Feature via Color Quantisation for Fake Audio Detection
Aug 20, 2024



In the field of deepfake detection, previous studies focus on using reconstruction or mask and prediction methods to train pre-trained models, which are then transferred to fake audio detection training where the encoder is used to extract features, such as wav2vec2.0 and Masked Auto Encoder. These methods have proven that using real audio for reconstruction pre-training can better help the model distinguish fake audio. However, the disadvantage lies in poor interpretability, meaning it is hard to intuitively present the differences between deepfake and real audio. This paper proposes a noval feature extraction method via color quantisation which constrains the reconstruction to use a limited number of colors for the spectral image-like input. The proposed method ensures reconstructed input differs from the original, which allows for intuitive observation of the focus areas in the spectral reconstruction. Experiments conducted on the ASVspoof2019 dataset demonstrate that the proposed method achieves better classification performance compared to using the original spectral as input and pretraining the recolor network can also benefit the fake audio detection.
EELE: Exploring Efficient and Extensible LoRA Integration in Emotional Text-to-Speech
Aug 20, 2024



In the current era of Artificial Intelligence Generated Content (AIGC), a Low-Rank Adaptation (LoRA) method has emerged. It uses a plugin-based approach to learn new knowledge with lower parameter quantities and computational costs, and it can be plugged in and out based on the specific sub-tasks, offering high flexibility. However, the current application schemes primarily incorporate LoRA into the pre-introduced conditional parts of the speech models. This fixes the position of LoRA, limiting the flexibility and scalability of its application. Therefore, we propose the Exploring Efficient and Extensible LoRA Integration in Emotional Text-to-Speech (EELE) method. Starting from a general neutral speech model, we do not pre-introduce emotional information but instead use the LoRA plugin to design a flexible adaptive scheme that endows the model with emotional generation capabilities. Specifically, we initially train the model using only neutral speech data. After training is complete, we insert LoRA into different modules and fine-tune the model with emotional speech data to find the optimal insertion scheme. Through experiments, we compare and test the effects of inserting LoRA at different positions within the model and assess LoRA's ability to learn various emotions, effectively proving the validity of our method. Additionally, we explore the impact of the rank size of LoRA and the difference compared to directly fine-tuning the entire model.
MDPE: A Multimodal Deception Dataset with Personality and Emotional Characteristics
Jul 17, 2024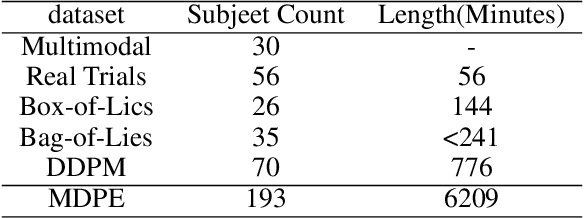


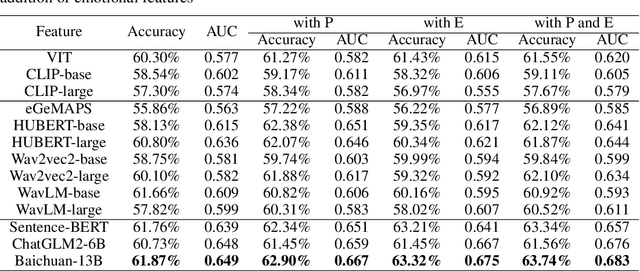
Deception detection has garnered increasing attention in recent years due to the significant growth of digital media and heightened ethical and security concerns. It has been extensively studied using multimodal methods, including video, audio, and text. In addition, individual differences in deception production and detection are believed to play a crucial role.Although some studies have utilized individual information such as personality traits to enhance the performance of deception detection, current systems remain limited, partly due to a lack of sufficient datasets for evaluating performance. To address this issue, we introduce a multimodal deception dataset MDPE. Besides deception features, this dataset also includes individual differences information in personality and emotional expression characteristics. It can explore the impact of individual differences on deception behavior. It comprises over 104 hours of deception and emotional videos from 193 subjects. Furthermore, we conducted numerous experiments to provide valuable insights for future deception detection research. MDPE not only supports deception detection, but also provides conditions for tasks such as personality recognition and emotion recognition, and can even study the relationships between them. We believe that MDPE will become a valuable resource for promoting research in the field of affective computing.