 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable proficiency in mainstream academic disciplines such as mathematics, physics, and computer science. However, human knowledge encompasses over 200 specialized disciplines, far exceeding the scope of existing benchmarks. The capabilities of LLMs in many of these specialized fields-particularly in light industry, agriculture, and service-oriented disciplines-remain inadequately evaluated. To address this gap, we present SuperGPQA, a comprehensive benchmark that evaluates graduate-level knowledge and reasoning capabilities across 285 disciplines. Our benchmark employs a novel Human-LLM collaborative filtering mechanism to eliminate trivial or ambiguous questions through iterative refinement based on both LLM responses and expert feedback. Our experimental results reveal significant room for improvement in the performance of current state-of-the-art LLMs across diverse knowledge domains (e.g., the reasoning-focused model DeepSeek-R1 achieved the highest accuracy of 61.82% on SuperGPQA), highlighting the considerable gap between current model capabilities and artificial general intelligence. Additionally, we present comprehensive insights from our management of a large-scale annotation process, involving over 80 expert annotators and an interactive Human-LLM collaborative system, offering valuable methodological guidance for future research initiatives of comparable scope.
PopAlign: Diversifying Contrasting Patterns for a More Comprehensive Alignment
Oct 17, 2024
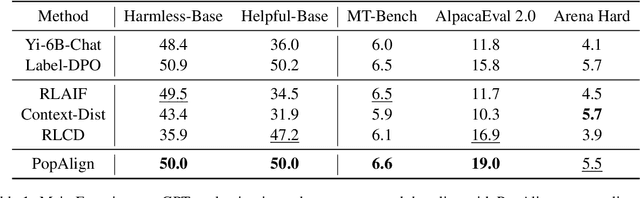

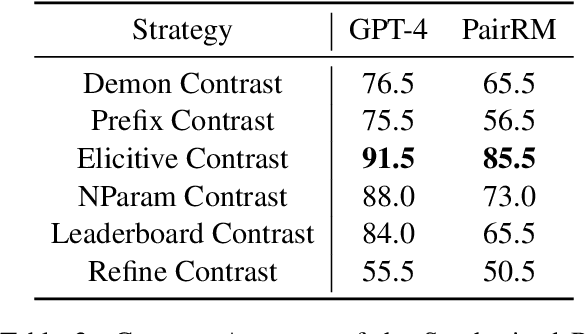
Alignment of large language models (LLMs) involves training models on preference-contrastive output pairs to adjust their responses according to human preferences. To obtain such contrastive pairs, traditional methods like RLHF and RLAIF rely on limited contrasting patterns, such as varying model variants or decoding temperatures. This singularity leads to two issues: (1) alignment is not comprehensive; and thereby (2) models are susceptible to jailbreaking attacks. To address these issues, we investigate how to construct more comprehensive and diversified contrasting patterns to enhance preference data (RQ1) and verify the impact of the diversification of contrasting patterns on model alignment (RQ2). For RQ1, we propose PopAlign, a framework that integrates diversified contrasting patterns across the prompt, model, and pipeline levels, introducing six contrasting strategies that do not require additional feedback labeling procedures. Regarding RQ2, we conduct thorough experiments demonstrating that PopAlign significantly outperforms existing methods, leading to more comprehensive alignment.
LIME-M: Less Is More for Evaluation of MLLMs
Sep 10, 2024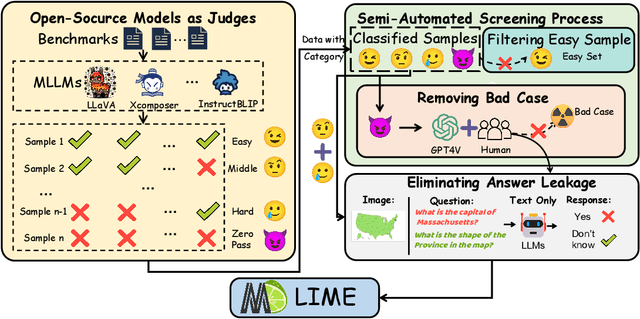
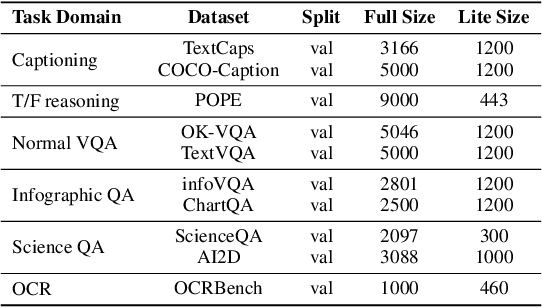
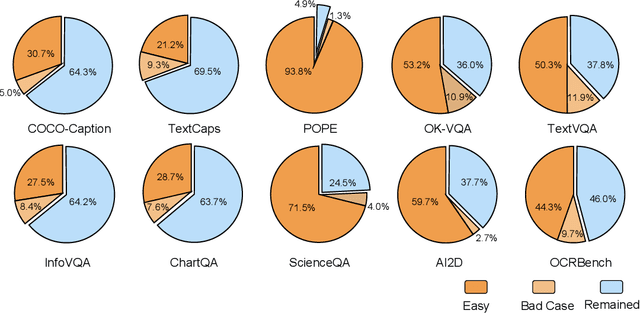
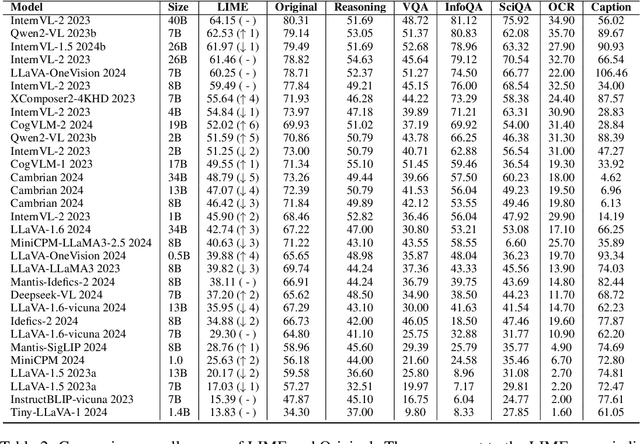
With the remarkable success achieved by Multimodal Large Language Models (MLLMs), numerous benchmarks have been designed to assess MLLMs' ability to guide their development in image perception tasks (e.g., image captioning and visual question answering). However, the existence of numerous benchmarks results in a substantial computational burden when evaluating model performance across all of them. Moreover, these benchmarks contain many overly simple problems or challenging samples, which do not effectively differentiate the capabilities among various MLLMs. To address these challenges, we propose a pipeline to process the existing benchmarks, which consists of two modules: (1) Semi-Automated Screening Process and (2) Eliminating Answer Leakage. The Semi-Automated Screening Process filters out samples that cannot distinguish the model's capabilities by synthesizing various MLLMs and manually evaluating them. The Eliminate Answer Leakage module filters samples whose answers can be inferred without images. Finally, we curate the LIME-M: Less Is More for Evaluation of Multimodal LLMs, a lightweight Multimodal benchmark that can more effectively evaluate the performance of different models. Our experiments demonstrate that: LIME-M can better distinguish the performance of different MLLMs with fewer samples (24% of the original) and reduced time (23% of the original); LIME-M eliminates answer leakage, focusing mainly on the information within images; The current automatic metric (i.e., CIDEr) is insufficient for evaluating MLLMs' capabilities in captioning. Moreover, removing the caption task score when calculating the overall score provides a more accurate reflection of model performance differences. All our codes and data are released at https://github.com/kangreen0210/LIME-M.
MMRA: A Benchmark for Evaluating Multi-Granularity and Multi-Image Relational Association Capabilities in Large Visual Language Models
Aug 06, 2024



Given the remarkable success that large visual language models (LVLMs) have achieved in image perception tasks, the endeavor to make LVLMs perceive the world like humans is drawing increasing attention. Current multi-modal benchmarks primarily focus on facts or specific topic-related knowledge contained within individual images. However, they often overlook the associative relations between multiple images, which require the identification and analysis of similarities among entities or content present in different images. Therefore, we propose the multi-image relation association task and a meticulously curated Multi-granularity Multi-image Relational Association (MMRA) benchmark, comprising 1,024 samples. In order to systematically and comprehensively evaluate current LVLMs, we establish an associational relation system among images that contain 11 subtasks (e.g, UsageSimilarity, SubEvent) at two granularity levels (i.e., image and entity) according to the relations in ConceptNet. Our experiments reveal that on the MMRA benchmark, current multi-image LVLMs exhibit distinct advantages and disadvantages across various subtasks. Notably, fine-grained, entity-level multi-image perception tasks pose a greater challenge for LVLMs compared to image-level tasks. Moreover, LVLMs perform poorly on spatial-related tasks, indicating that LVLMs still have limited spatial awareness. Additionally, our findings indicate that while LVLMs demonstrate a strong capability to perceive image details, enhancing their ability to associate information across multiple images hinges on improving the reasoning capabilities of their language model component. Moreover, we explored the ability of LVLMs to perceive image sequences within the context of our multi-image association task. Our experiments show that the majority of current LVLMs do not adequately model image sequences during the pre-training process.
MMRA: A Benchmark for Multi-granularity Multi-image Relational Association
Jul 24, 2024Given the remarkable success that large visual language models (LVLMs) have achieved in image perception tasks, the endeavor to make LVMLs perceive the world like humans is drawing increasing attention. Current multi-modal benchmarks mainly focus on the objective fact or certain topic related potential knowledge within a image, but overlook the associative relations between multiple images. Therefore, we define a multi-image relation association task, and meticulously curate \textbf{MMRA} benchmark, a \textbf{M}ulti-granularity \textbf{M}ulti-image \textbf{R}elational \textbf{A}ssociation benchmark, consisted of \textbf{1026} samples. In order to systematically and comprehensively evaluate mainstream LVLMs, we establish an associational relation system among images that contain \textbf{11 subtasks} (e.g, UsageSimilarity, SubEvent, etc.) at two granularity levels (i.e., "\textbf{image}" and "\textbf{entity}") according to the relations in ConceptNet. Our experiments demonstrate that, on our MMRA benchmark, current mainstream LVLMs all have their own advantages and disadvantages across different subtasks. It is worth noting that, at the entity level, the performance of all models is worse than that of them at the image level, indicating that the fine-grained multi-image perception task is still challenging for LVLMs. The tasks related to spatial perception are relatively difficult for LVLMs to handle. Furthermore, we find that LVMLs exhibit a good ability to perceive image details, and the key to enhancing their multi-image association capability is to strengthen the reasoning ability of their language model component. All our codes and data are released at htt\url{https://github.com/Wusiwei0410/MMRA}.
MDPE: A Multimodal Deception Dataset with Personality and Emotional Characteristics
Jul 17, 2024


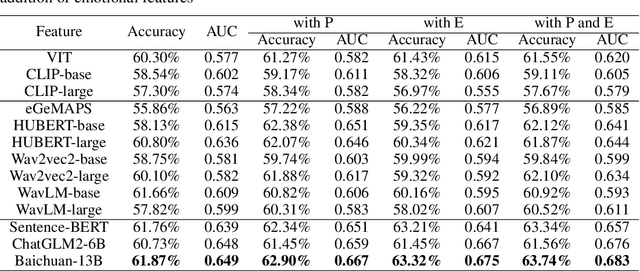
Deception detection has garnered increasing attention in recent years due to the significant growth of digital media and heightened ethical and security concerns. It has been extensively studied using multimodal methods, including video, audio, and text. In addition, individual differences in deception production and detection are believed to play a crucial role.Although some studies have utilized individual information such as personality traits to enhance the performance of deception detection, current systems remain limited, partly due to a lack of sufficient datasets for evaluating performance. To address this issue, we introduce a multimodal deception dataset MDPE. Besides deception features, this dataset also includes individual differences information in personality and emotional expression characteristics. It can explore the impact of individual differences on deception behavior. It comprises over 104 hours of deception and emotional videos from 193 subjects. Furthermore, we conducted numerous experiments to provide valuable insights for future deception detection research. MDPE not only supports deception detection, but also provides conditions for tasks such as personality recognition and emotion recognition, and can even study the relationships between them. We believe that MDPE will become a valuable resource for promoting research in the field of affective computing.
MetaDesigner: Advancing Artistic Typography through AI-Driven, User-Centric, and Multilingual WordArt Synthesis
Jun 28, 2024
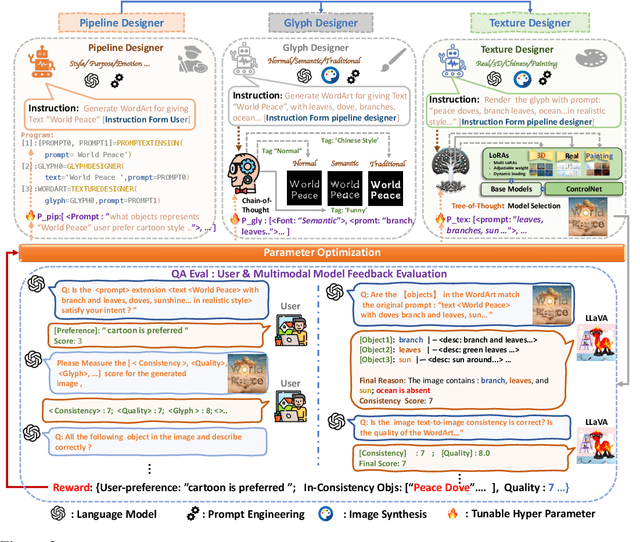
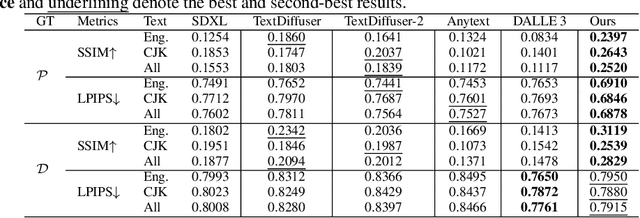
MetaDesigner revolutionizes artistic typography synthesis by leveraging the strengths of Large Language Models (LLMs) to drive a design paradigm centered around user engagement. At the core of this framework lies a multi-agent system comprising the Pipeline, Glyph, and Texture agents, which collectively enable the creation of customized WordArt, ranging from semantic enhancements to the imposition of complex textures. MetaDesigner incorporates a comprehensive feedback mechanism that harnesses insights from multimodal models and user evaluations to refine and enhance the design process iteratively. Through this feedback loop, the system adeptly tunes hyperparameters to align with user-defined stylistic and thematic preferences, generating WordArt that not only meets but exceeds user expectations of visual appeal and contextual relevance. Empirical validations highlight MetaDesigner's capability to effectively serve diverse WordArt applications, consistently producing aesthetically appealing and context-sensitive results.
PIN: A Knowledge-Intensive Dataset for Paired and Interleaved Multimodal Documents
Jun 20, 2024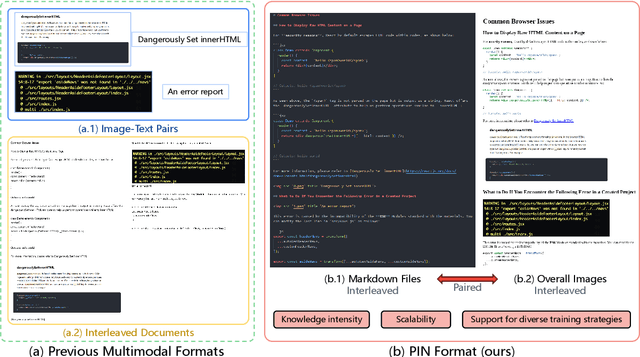


Recent advancements in Large Multimodal Models (LMMs) have leveraged extensive multimodal datasets to enhance capabilities in complex knowledge-driven tasks. However, persistent challenges in perceptual and reasoning errors limit their efficacy, particularly in interpreting intricate visual data and deducing multimodal relationships. Addressing these issues, we introduce a novel dataset format, PIN (Paired and INterleaved multimodal documents), designed to significantly improve both the depth and breadth of multimodal training. The PIN format is built on three foundational principles: knowledge intensity, scalability, and support for diverse training modalities. This innovative format combines markdown files and comprehensive images to enrich training data with a dense knowledge structure and versatile training strategies. We present PIN-14M, an open-source dataset comprising 14 million samples derived from a diverse range of Chinese and English sources, tailored to include complex web and scientific content. This dataset is constructed meticulously to ensure data quality and ethical integrity, aiming to facilitate advanced training strategies and improve model robustness against common multimodal training pitfalls. Our initial results, forming the basis of this technical report, suggest significant potential for the PIN format in refining LMM performance, with plans for future expansions and detailed evaluations of its impact on model capabilities.
SciMMIR: Benchmarking Scientific Multi-modal Information Retrieval
Jan 24, 2024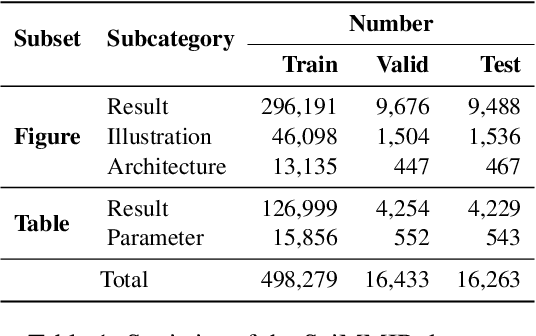
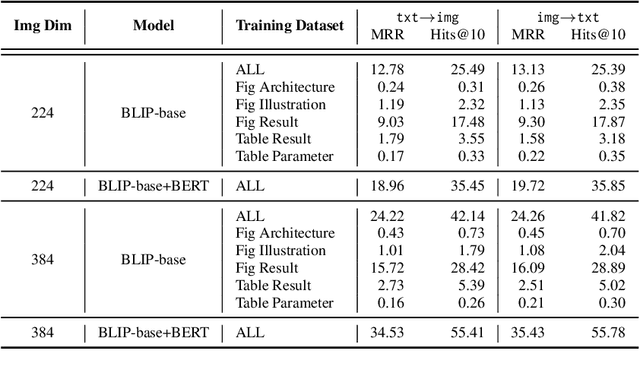
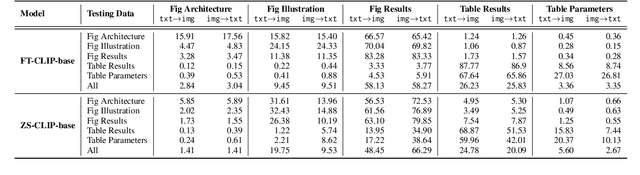
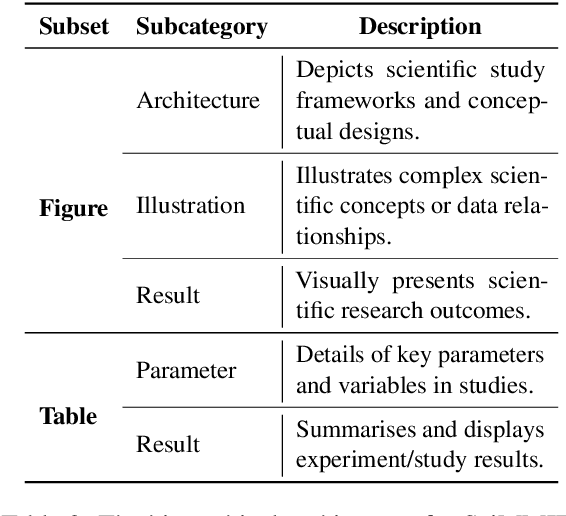
Multi-modal information retrieval (MMIR) is a rapidly evolving field, where significant progress, particularly in image-text pairing, has been made through advanced representation learning and cross-modality alignment research. However, current benchmarks for evaluating MMIR performance in image-text pairing within the scientific domain show a notable gap, where chart and table images described in scholarly language usually do not play a significant role. To bridge this gap, we develop a specialised scientific MMIR (SciMMIR) benchmark by leveraging open-access paper collections to extract data relevant to the scientific domain. This benchmark comprises 530K meticulously curated image-text pairs, extracted from figures and tables with detailed captions in scientific documents. We further annotate the image-text pairs with two-level subset-subcategory hierarchy annotations to facilitate a more comprehensive evaluation of the baselines. We conducted zero-shot and fine-tuning evaluations on prominent multi-modal image-captioning and visual language models, such as CLIP and BLIP. Our analysis offers critical insights for MMIR in the scientific domain, including the impact of pre-training and fine-tuning settings and the influence of the visual and textual encoders. All our data and checkpoints are publicly available at https://github.com/Wusiwei0410/SciMMIR.
CMMMU: A Chinese Massive Multi-discipline Multimodal Understanding Benchmark
Jan 22, 2024As the capabilities of large multimodal models (LMMs) continue to advance, evaluating the performance of LMMs emerges as an increasing need. Additionally, there is an even larger gap in evaluating the advanced knowledge and reasoning abilities of LMMs in non-English contexts such as Chinese. We introduce CMMMU, a new Chinese Massive Multi-discipline Multimodal Understanding benchmark designed to evaluate LMMs on tasks demanding college-level subject knowledge and deliberate reasoning in a Chinese context. CMMMU is inspired by and strictly follows the annotation and analysis pattern of MMMU. CMMMU includes 12k manually collected multimodal questions from college exams, quizzes, and textbooks, covering six core disciplines: Art & Design, Business, Science, Health & Medicine, Humanities & Social Science, and Tech & Engineering, like its companion, MMMU. These questions span 30 subjects and comprise 39 highly heterogeneous image types, such as charts, diagrams, maps, tables, music sheets, and chemical structures. CMMMU focuses on complex perception and reasoning with domain-specific knowledge in the Chinese context. We evaluate 11 open-source LLMs and one proprietary GPT-4V(ision). Even GPT-4V only achieves accuracies of 42%, indicating a large space for improvement. CMMMU will boost the community to build the next-generation LMMs towards expert artificial intelligence and promote the democratization of LMMs by providing diverse language contexts.