 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalogical Structure, Minimal Contextual Cues and Contrastive Distractors: Input Design for Sample-Efficient Linguistic Rule Induction
Nov 13, 2025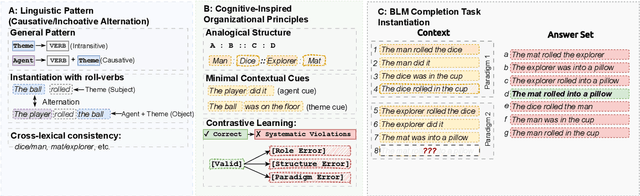
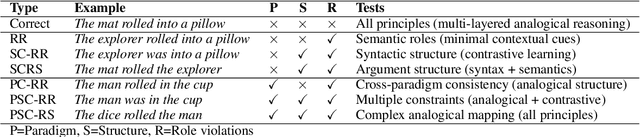

Large language models achieve strong performance through training on vast datasets. Can analogical paradigm organization enable lightweight models to match this performance with minimal data? We develop a computational approach implementing three cognitive-inspired principles: analogical structure, contrastive learning, and minimal contextual cues. We test this approach with structured completion tasks where models identify correct sentence completions from analogical patterns with contrastive alternatives. Training lightweight models (BERT+CNN, $0.5M$ parameters) on only one hundred structured examples of English causative/inchoative alternations achieves $F1=0.95$, outperforming zero-shot \texttt{GPT-o3} ($F1=0.87$). Ablation studies confirm that analogical organization and contrastive structure improve performance, consistently surpassing randomly shuffled baselines across architectures. Cross-phenomenon validation using unspecified object alternations replicates these efficiency gains, confirming approach robustness. Our results show that analogical paradigm organization enables competitive linguistic rule learning with orders of magnitude less data than conventional approaches require.
Graceful Forgetting in Generative Language Models
May 26, 2025Recently, the pretrain-finetune paradigm has become a cornerstone in various deep learning areas. While in general the pre-trained model would promote both effectiveness and efficiency of downstream tasks fine-tuning, studies have shown that not all knowledge acquired during pre-training is beneficial. Some of the knowledge may actually bring detrimental effects to the fine-tuning tasks, which is also known as negative transfer. To address this problem, graceful forgetting has emerged as a promising approach. The core principle of graceful forgetting is to enhance the learning plasticity of the target task by selectively discarding irrelevant knowledge. However, this approach remains underexplored in the context of generative language models, and it is often challenging to migrate existing forgetting algorithms to these models due to architecture incompatibility. To bridge this gap, in this paper we propose a novel framework, Learning With Forgetting (LWF), to achieve graceful forgetting in generative language models. With Fisher Information Matrix weighting the intended parameter updates, LWF computes forgetting confidence to evaluate self-generated knowledge regarding the forgetting task, and consequently, knowledge with high confidence is periodically unlearned during fine-tuning. Our experiments demonstrate that, although thoroughly uncovering the mechanisms of knowledge interaction remains challenging in pre-trained language models, applying graceful forgetting can contribute to enhanced fine-tuning performance.
J1: Exploring Simple Test-Time Scaling for LLM-as-a-Judge
May 17, 2025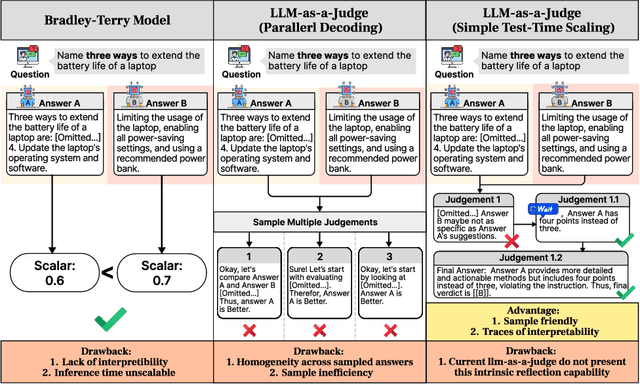
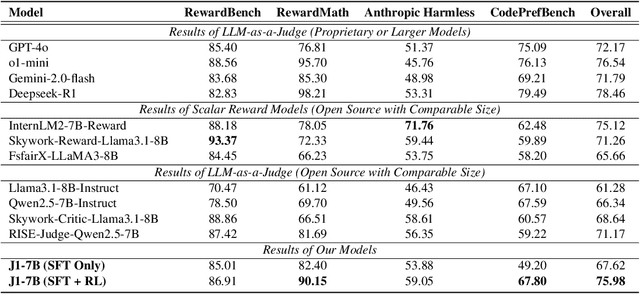
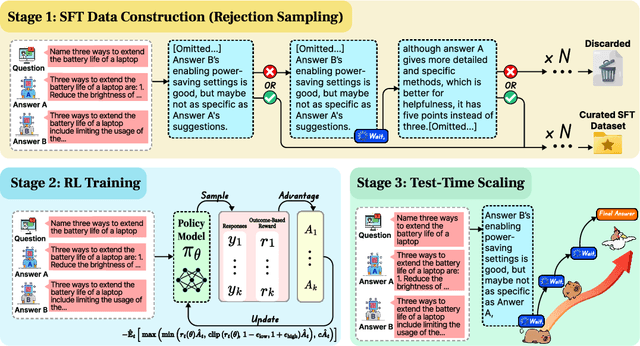
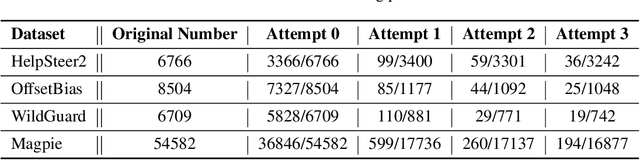
The current focus of AI research is shifting from emphasizing model training towards enhancing evaluation quality, a transition that is crucial for driving further advancements in AI systems. Traditional evaluation methods typically rely on reward models assigning scalar preference scores to outputs. Although effective, such approaches lack interpretability, leaving users often uncertain about why a reward model rates a particular response as high or low. The advent of LLM-as-a-Judge provides a more scalable and interpretable method of supervision, offering insights into the decision-making process. Moreover, with the emergence of large reasoning models, which consume more tokens for deeper thinking and answer refinement, scaling test-time computation in the LLM-as-a-Judge paradigm presents an avenue for further boosting performance and providing more interpretability through reasoning traces. In this paper, we introduce $\textbf{J1-7B}$, which is first supervised fine-tuned on reflection-enhanced datasets collected via rejection-sampling and subsequently trained using Reinforcement Learning (RL) with verifiable rewards. At inference time, we apply Simple Test-Time Scaling (STTS) strategies for additional performance improvement. Experimental results demonstrate that $\textbf{J1-7B}$ surpasses the previous state-of-the-art LLM-as-a-Judge by $ \textbf{4.8}$\% and exhibits a $ \textbf{5.1}$\% stronger scaling trend under STTS. Additionally, we present three key findings: (1) Existing LLM-as-a-Judge does not inherently exhibit such scaling trend. (2) Model simply fine-tuned on reflection-enhanced datasets continues to demonstrate similarly weak scaling behavior. (3) Significant scaling trend emerges primarily during the RL phase, suggesting that effective STTS capability is acquired predominantly through RL training.
Foundation Cures Personalization: Recovering Facial Personalized Models' Prompt Consistency
Nov 22, 2024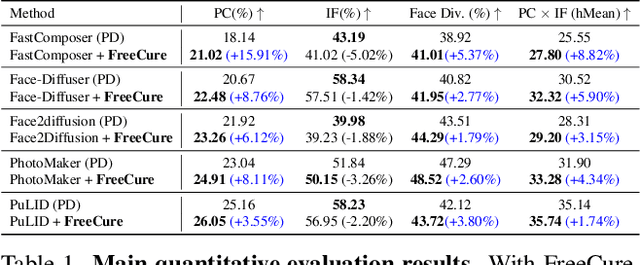



Facial personalization represents a crucial downstream task in the domain of text-to-image generation. To preserve identity fidelity while ensuring alignment with user-defined prompts, current mainstream frameworks for facial personalization predominantly employ identity embedding mechanisms to associate identity information with textual embeddings. However, our experiments show that identity embeddings compromise the effectiveness of other tokens within the prompt, thereby hindering high prompt consistency, particularly when prompts involve multiple facial attributes. Moreover, previous works overlook the fact that their corresponding foundation models hold great potential to generate faces aligning to prompts well and can be easily leveraged to cure these ill-aligned attributes in personalized models. Building upon these insights, we propose FreeCure, a training-free framework that harnesses the intrinsic knowledge from the foundation models themselves to improve the prompt consistency of personalization models. First, by extracting cross-attention and semantic maps from the denoising process of foundation models, we identify easily localized attributes (e.g., hair, accessories, etc). Second, we enhance multiple attributes in the outputs of personalization models through a novel noise-blending strategy coupled with an inversion-based process. Our approach offers several advantages: it eliminates the need for training; it effectively facilitates the enhancement for a wide array of facial attributes in a non-intrusive manner; and it can be seamlessly integrated into existing popular personalization models. FreeCure has demonstrated significant improvements in prompt consistency across a diverse set of state-of-the-art facial personalization models while maintaining the integrity of original identity fidelity.
Exploring Italian sentence embeddings properties through multi-tasking
Sep 10, 2024We investigate to what degree existing LLMs encode abstract linguistic information in Italian in a multi-task setting. We exploit curated synthetic data on a large scale -- several Blackbird Language Matrices (BLMs) problems in Italian -- and use them to study how sentence representations built using pre-trained language models encode specific syntactic and semantic information. We use a two-level architecture to model separately a compression of the sentence embeddings into a representation that contains relevant information for a task, and a BLM task. We then investigate whether we can obtain compressed sentence representations that encode syntactic and semantic information relevant to several BLM tasks. While we expected that the sentence structure -- in terms of sequence of phrases/chunks -- and chunk properties could be shared across tasks, performance and error analysis show that the clues for the different tasks are encoded in different manners in the sentence embeddings, suggesting that abstract linguistic notions such as constituents or thematic roles does not seem to be present in the pretrained sentence embeddings.
Exploring syntactic information in sentence embeddings through multilingual subject-verb agreement
Sep 10, 2024In this paper, our goal is to investigate to what degree multilingual pretrained language models capture cross-linguistically valid abstract linguistic representations. We take the approach of developing curated synthetic data on a large scale, with specific properties, and using them to study sentence representations built using pretrained language models. We use a new multiple-choice task and datasets, Blackbird Language Matrices (BLMs), to focus on a specific grammatical structural phenomenon -- subject-verb agreement across a variety of sentence structures -- in several languages. Finding a solution to this task requires a system detecting complex linguistic patterns and paradigms in text representations. Using a two-level architecture that solves the problem in two steps -- detect syntactic objects and their properties in individual sentences, and find patterns across an input sequence of sentences -- we show that despite having been trained on multilingual texts in a consistent manner, multilingual pretrained language models have language-specific differences, and syntactic structure is not shared, even across closely related languages.
AgentMonitor: A Plug-and-Play Framework for Predictive and Secure Multi-Agent Systems
Aug 27, 2024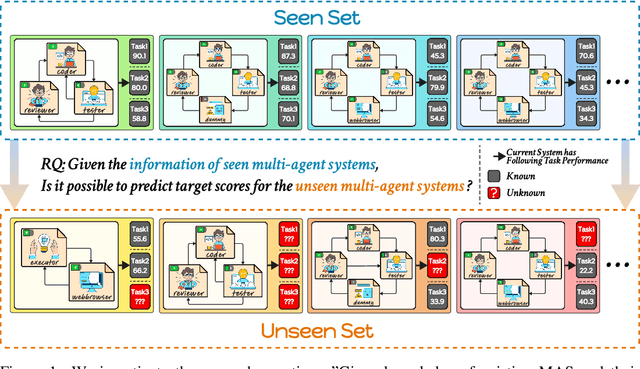
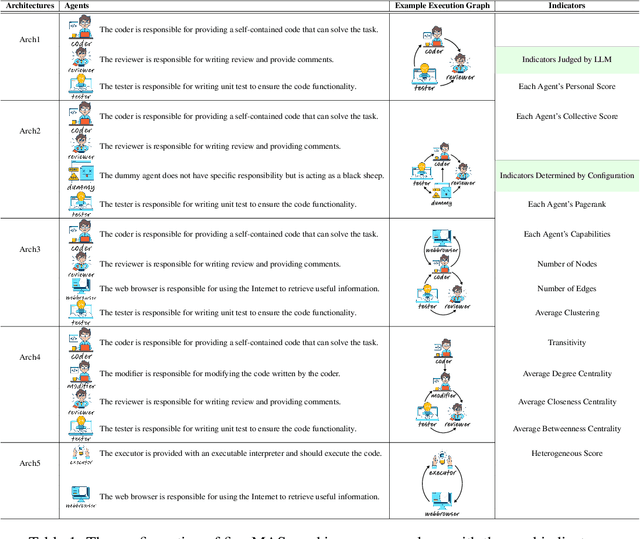
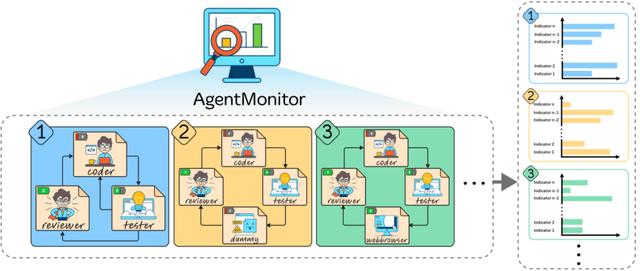
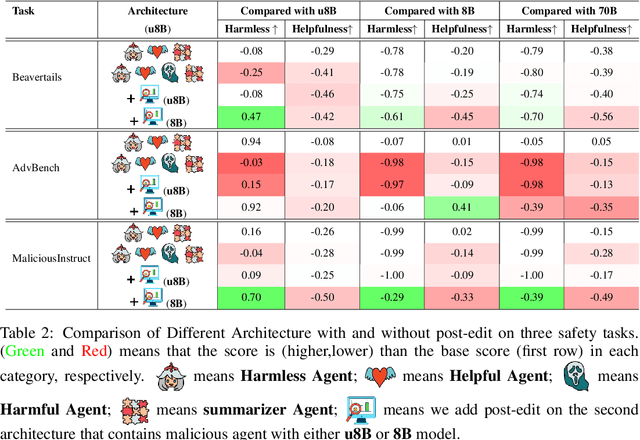
The rapid advancement of large language models (LLMs) has led to the rise of LLM-based agents. Recent research shows that multi-agent systems (MAS), where each agent plays a specific role, can outperform individual LLMs. However, configuring an MAS for a task remains challenging, with performance only observable post-execution. Inspired by scaling laws in LLM development, we investigate whether MAS performance can be predicted beforehand. We introduce AgentMonitor, a framework that integrates at the agent level to capture inputs and outputs, transforming them into statistics for training a regression model to predict task performance. Additionally, it can further apply real-time corrections to address security risks posed by malicious agents, mitigating negative impacts and enhancing MAS security. Experiments demonstrate that an XGBoost model achieves a Spearman correlation of 0.89 in-domain and 0.58 in more challenging scenarios. Furthermore, using AgentMonitor reduces harmful content by 6.2% and increases helpful content by 1.8% on average, enhancing safety and reliability. Code is available at \url{https://github.com/chanchimin/AgentMonitor}.
Importance Weighting Can Help Large Language Models Self-Improve
Aug 19, 2024



Large language models (LLMs) have shown remarkable capability in numerous tasks and applications. However, fine-tuning LLMs using high-quality datasets under external supervision remains prohibitively expensive. In response, LLM self-improvement approaches have been vibrantly developed recently. The typical paradigm of LLM self-improvement involves training LLM on self-generated data, part of which may be detrimental and should be filtered out due to the unstable data quality. While current works primarily employs filtering strategies based on answer correctness, in this paper, we demonstrate that filtering out correct but with high distribution shift extent (DSE) samples could also benefit the results of self-improvement. Given that the actual sample distribution is usually inaccessible, we propose a new metric called DS weight to approximate DSE, inspired by the Importance Weighting methods. Consequently, we integrate DS weight with self-consistency to comprehensively filter the self-generated samples and fine-tune the language model. Experiments show that with only a tiny valid set (up to 5\% size of the training set) to compute DS weight, our approach can notably promote the reasoning ability of current LLM self-improvement methods. The resulting performance is on par with methods that rely on external supervision from pre-trained reward models.
PIN: A Knowledge-Intensive Dataset for Paired and Interleaved Multimodal Documents
Jun 20, 2024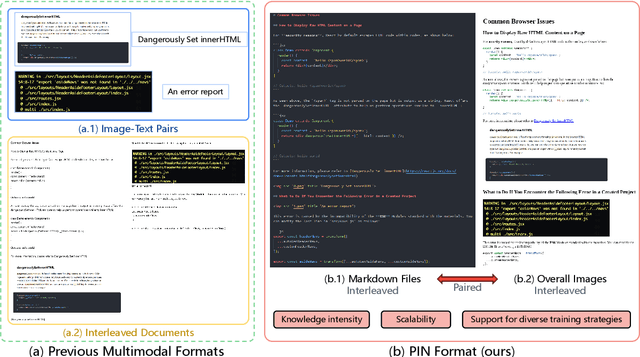


Recent advancements in Large Multimodal Models (LMMs) have leveraged extensive multimodal datasets to enhance capabilities in complex knowledge-driven tasks. However, persistent challenges in perceptual and reasoning errors limit their efficacy, particularly in interpreting intricate visual data and deducing multimodal relationships. Addressing these issues, we introduce a novel dataset format, PIN (Paired and INterleaved multimodal documents), designed to significantly improve both the depth and breadth of multimodal training. The PIN format is built on three foundational principles: knowledge intensity, scalability, and support for diverse training modalities. This innovative format combines markdown files and comprehensive images to enrich training data with a dense knowledge structure and versatile training strategies. We present PIN-14M, an open-source dataset comprising 14 million samples derived from a diverse range of Chinese and English sources, tailored to include complex web and scientific content. This dataset is constructed meticulously to ensure data quality and ethical integrity, aiming to facilitate advanced training strategies and improve model robustness against common multimodal training pitfalls. Our initial results, forming the basis of this technical report, suggest significant potential for the PIN format in refining LMM performance, with plans for future expansions and detailed evaluations of its impact on model capabilities.