 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWindowed Fourier Propagator: A Frequency-Local Neural Operator for Wave Equations in Inhomogeneous Media
Mar 15, 2026Wave equations are fundamental to describing a vast array of physical phenomena, yet their simulation in inhomogeneous media poses a computational challenge due to the highly oscillatory nature of the solutions. To overcome the high costs of traditional solvers, we propose the Windowed Fourier Propagator (WFP), a novel neural operator that efficiently learns the solution operator. The WFP's design is rooted in the physical principle of frequency locality, where wave energy scatters primarily to adjacent frequencies. By learning a set of compact, localized propagators, each mapping an input frequency to a small window of outputs, our method avoids the complexity of dense interaction models and achieves computational efficiency. Another key feature is the explicit preservation of superposition, which enables remarkable generalization from simple training data (e.g., plane waves) to arbitrary, complex wave states. We demonstrate that the WFP provides an explainable, efficient and accurate framework for data-driven wave modeling in complex media.
Graceful Forgetting in Generative Language Models
May 26, 2025Recently, the pretrain-finetune paradigm has become a cornerstone in various deep learning areas. While in general the pre-trained model would promote both effectiveness and efficiency of downstream tasks fine-tuning, studies have shown that not all knowledge acquired during pre-training is beneficial. Some of the knowledge may actually bring detrimental effects to the fine-tuning tasks, which is also known as negative transfer. To address this problem, graceful forgetting has emerged as a promising approach. The core principle of graceful forgetting is to enhance the learning plasticity of the target task by selectively discarding irrelevant knowledge. However, this approach remains underexplored in the context of generative language models, and it is often challenging to migrate existing forgetting algorithms to these models due to architecture incompatibility. To bridge this gap, in this paper we propose a novel framework, Learning With Forgetting (LWF), to achieve graceful forgetting in generative language models. With Fisher Information Matrix weighting the intended parameter updates, LWF computes forgetting confidence to evaluate self-generated knowledge regarding the forgetting task, and consequently, knowledge with high confidence is periodically unlearned during fine-tuning. Our experiments demonstrate that, although thoroughly uncovering the mechanisms of knowledge interaction remains challenging in pre-trained language models, applying graceful forgetting can contribute to enhanced fine-tuning performance.
Foundation Cures Personalization: Recovering Facial Personalized Models' Prompt Consistency
Nov 22, 2024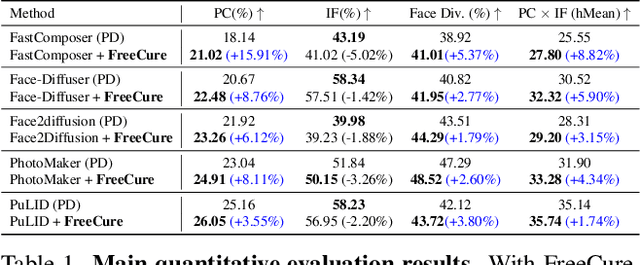



Facial personalization represents a crucial downstream task in the domain of text-to-image generation. To preserve identity fidelity while ensuring alignment with user-defined prompts, current mainstream frameworks for facial personalization predominantly employ identity embedding mechanisms to associate identity information with textual embeddings. However, our experiments show that identity embeddings compromise the effectiveness of other tokens within the prompt, thereby hindering high prompt consistency, particularly when prompts involve multiple facial attributes. Moreover, previous works overlook the fact that their corresponding foundation models hold great potential to generate faces aligning to prompts well and can be easily leveraged to cure these ill-aligned attributes in personalized models. Building upon these insights, we propose FreeCure, a training-free framework that harnesses the intrinsic knowledge from the foundation models themselves to improve the prompt consistency of personalization models. First, by extracting cross-attention and semantic maps from the denoising process of foundation models, we identify easily localized attributes (e.g., hair, accessories, etc). Second, we enhance multiple attributes in the outputs of personalization models through a novel noise-blending strategy coupled with an inversion-based process. Our approach offers several advantages: it eliminates the need for training; it effectively facilitates the enhancement for a wide array of facial attributes in a non-intrusive manner; and it can be seamlessly integrated into existing popular personalization models. FreeCure has demonstrated significant improvements in prompt consistency across a diverse set of state-of-the-art facial personalization models while maintaining the integrity of original identity fidelity.
TEQ: Trainable Equivalent Transformation for Quantization of LLMs
Oct 17, 2023
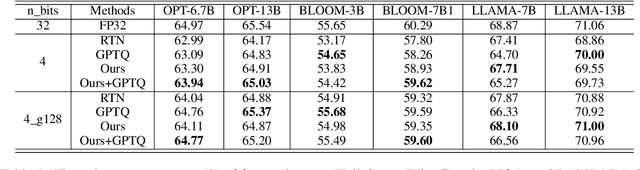
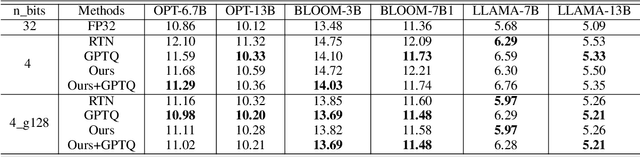

As large language models (LLMs) become more prevalent, there is a growing need for new and improved quantization methods that can meet the computationalast layer demands of these modern architectures while maintaining the accuracy. In this paper, we present TEQ, a trainable equivalent transformation that preserves the FP32 precision of the model output while taking advantage of low-precision quantization, especially 3 and 4 bits weight-only quantization. The training process is lightweight, requiring only 1K steps and fewer than 0.1 percent of the original model's trainable parameters. Furthermore, the transformation does not add any computational overhead during inference. Our results are on-par with the state-of-the-art (SOTA) methods on typical LLMs. Our approach can be combined with other methods to achieve even better performance. The code is available at https://github.com/intel/neural-compressor.
Optimize Weight Rounding via Signed Gradient Descent for the Quantization of LLMs
Sep 28, 2023



Large Language Models (LLMs) have proven their exceptional capabilities in performing language-related tasks. However, their deployment poses significant challenges due to their considerable memory and storage requirements. In response to this issue, weight-only quantization, particularly 3 and 4-bit weight-only quantization, has emerged as one of the most viable solutions. As the number of bits decreases, the quantization grid broadens, thus emphasizing the importance of up and down rounding. While previous studies have demonstrated that fine-tuning up and down rounding with the addition of perturbations can enhance accuracy in some scenarios, our study is driven by the precise and limited boundary of these perturbations, where only the threshold for altering the rounding value is of significance. Consequently, we propose a concise and highly effective approach for optimizing the weight rounding task. Our method, named SignRound, involves lightweight block-wise tuning using signed gradient descent, enabling us to achieve outstanding results within 400 steps. SignRound competes impressively against recent methods without introducing additional inference overhead. The source code will be publicly available at \url{https://github.com/intel/neural-compressor} soon.
Uncertainty-Aware Cross-Modal Transfer Network for Sketch-Based 3D Shape Retrieval
Aug 11, 2023In recent years, sketch-based 3D shape retrieval has attracted growing attention. While many previous studies have focused on cross-modal matching between hand-drawn sketches and 3D shapes, the critical issue of how to handle low-quality and noisy samples in sketch data has been largely neglected. This paper presents an uncertainty-aware cross-modal transfer network (UACTN) that addresses this issue. UACTN decouples the representation learning of sketches and 3D shapes into two separate tasks: classification-based sketch uncertainty learning and 3D shape feature transfer. We first introduce an end-to-end classification-based approach that simultaneously learns sketch features and uncertainty, allowing uncertainty to prevent overfitting noisy sketches by assigning different levels of importance to clean and noisy sketches. Then, 3D shape features are mapped into the pre-learned sketch embedding space for feature alignment. Extensive experiments and ablation studies on two benchmarks demonstrate the superiority of our proposed method compared to state-of-the-art methods.
Few-Shot Font Generation by Learning Fine-Grained Local Styles
May 23, 2022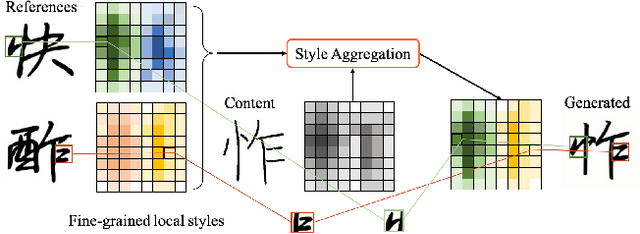
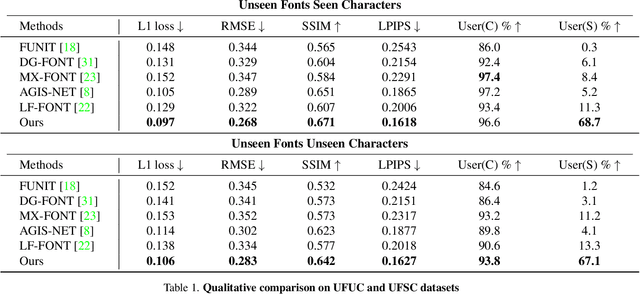
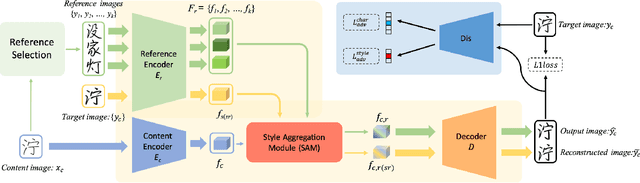
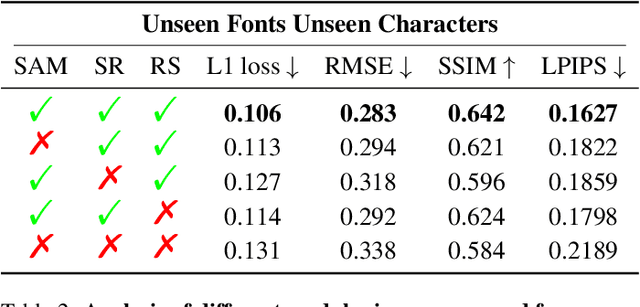
Few-shot font generation (FFG), which aims to generate a new font with a few examples, is gaining increasing attention due to the significant reduction in labor cost. A typical FFG pipeline considers characters in a standard font library as content glyphs and transfers them to a new target font by extracting style information from the reference glyphs. Most existing solutions explicitly disentangle content and style of reference glyphs globally or component-wisely. However, the style of glyphs mainly lies in the local details, i.e. the styles of radicals, components, and strokes together depict the style of a glyph. Therefore, even a single character can contain different styles distributed over spatial locations. In this paper, we propose a new font generation approach by learning 1) the fine-grained local styles from references, and 2) the spatial correspondence between the content and reference glyphs. Therefore, each spatial location in the content glyph can be assigned with the right fine-grained style. To this end, we adopt cross-attention over the representation of the content glyphs as the queries and the representations of the reference glyphs as the keys and values. Instead of explicitly disentangling global or component-wise modeling, the cross-attention mechanism can attend to the right local styles in the reference glyphs and aggregate the reference styles into a fine-grained style representation for the given content glyphs. The experiments show that the proposed method outperforms the state-of-the-art methods in FFG. In particular, the user studies also demonstrate the style consistency of our approach significantly outperforms previous methods.