 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTEQ: Trainable Equivalent Transformation for Quantization of LLMs
Oct 17, 2023
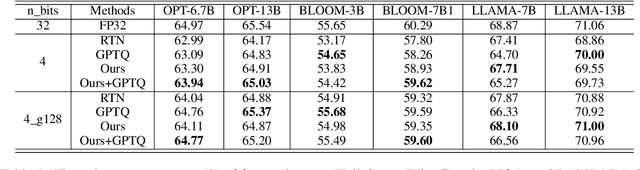
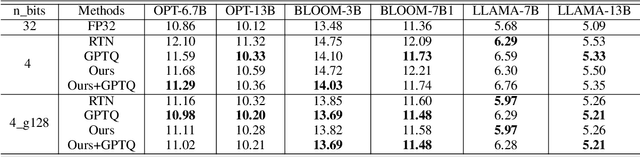

As large language models (LLMs) become more prevalent, there is a growing need for new and improved quantization methods that can meet the computationalast layer demands of these modern architectures while maintaining the accuracy. In this paper, we present TEQ, a trainable equivalent transformation that preserves the FP32 precision of the model output while taking advantage of low-precision quantization, especially 3 and 4 bits weight-only quantization. The training process is lightweight, requiring only 1K steps and fewer than 0.1 percent of the original model's trainable parameters. Furthermore, the transformation does not add any computational overhead during inference. Our results are on-par with the state-of-the-art (SOTA) methods on typical LLMs. Our approach can be combined with other methods to achieve even better performance. The code is available at https://github.com/intel/neural-compressor.
Optimize Weight Rounding via Signed Gradient Descent for the Quantization of LLMs
Sep 28, 2023



Large Language Models (LLMs) have proven their exceptional capabilities in performing language-related tasks. However, their deployment poses significant challenges due to their considerable memory and storage requirements. In response to this issue, weight-only quantization, particularly 3 and 4-bit weight-only quantization, has emerged as one of the most viable solutions. As the number of bits decreases, the quantization grid broadens, thus emphasizing the importance of up and down rounding. While previous studies have demonstrated that fine-tuning up and down rounding with the addition of perturbations can enhance accuracy in some scenarios, our study is driven by the precise and limited boundary of these perturbations, where only the threshold for altering the rounding value is of significance. Consequently, we propose a concise and highly effective approach for optimizing the weight rounding task. Our method, named SignRound, involves lightweight block-wise tuning using signed gradient descent, enabling us to achieve outstanding results within 400 steps. SignRound competes impressively against recent methods without introducing additional inference overhead. The source code will be publicly available at \url{https://github.com/intel/neural-compressor} soon.