 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashOverlap: Minimizing Tail Latency in Communication Overlap for Distributed LLM Training
Apr 27, 2026The rapid growth in the size of large language models has necessitated the partitioning of computational workloads across accelerators such as GPUs, TPUs, and NPUs. However, these parallelization strategies incur substantial data communication overhead significantly hindering computational efficiency. While communication-computation overlap presents a promising direction, existing data slicing based solutions suffer from tail latency. To overcome this limitation, this research introduces a novel communication-computation overlap technique to eliminate this tail latency in state of the art overlap methods for distributed LLM training. The aim of this technique is to effectively mitigate communication bottleneck of tensor parallelism and data parallelism for distributed training and inference. In particular, we propose a novel method termed Flash-Overlap that replaces conventional collective operations of reduce-scatter and all-gather with decomposed peer-to-peer (P2P) communication and schedules partitioned computations to enable fine-grained overlap. Our method provides an exact algorithm for reducing communication overhead that eliminates tail latency. Moreover, it presents a versatile solution compatible with data-parallel training and various tensor-level parallelism strategies, including TPSP and UP. Experimental evaluations demonstrate that our technique consistently achieves lower latency, superior Model FLOPS Utilization (MFU), and high throughput.
Let the Agent Steer: Closed-Loop Ranking Optimization via Influence Exchange
Mar 31, 2026Recommendation ranking is fundamentally an influence allocation problem: a sorting formula distributes ranking influence among competing factors, and the business outcome depends on finding the optimal "exchange rates" among them. However, offline proxy metrics systematically misjudge how influence reallocation translates to online impact, with asymmetric bias across metrics that a single calibration factor cannot correct. We present Sortify, the first fully autonomous LLM-driven ranking optimization agent deployed in a large-scale production recommendation system. The agent reframes ranking optimization as continuous influence exchange, closing the full loop from diagnosis to parameter deployment without human intervention. It addresses structural problems through three mechanisms: (1) a dual-channel framework grounded in Savage's Subjective Expected Utility (SEU) that decouples offline-online transfer correction (Belief channel) from constraint penalty adjustment (Preference channel); (2) an LLM meta-controller operating on framework-level parameters rather than low-level search variables; (3) a persistent Memory DB with 7 relational tables for cross-round learning. Its core metric, Influence Share, provides a decomposable measure where all factor contributions sum to exactly 100%. Sortify has been deployed across two markets. In Country A, the agent pushed GMV from -3.6% to +9.2% within 7 rounds with peak orders reaching +12.5%. In Country B, a cold-start deployment achieved +4.15% GMV/UU and +3.58% Ads Revenue in a 7-day A/B test, leading to full production rollout.
Data-driven Progressive Discovery of Physical Laws
Mar 14, 2026Symbolic regression is a powerful tool for knowledge discovery, enabling the extraction of interpretable mathematical expressions directly from data. However, conventional symbolic discovery typically follows an end-to-end, "one-step" process, which often generates lengthy and physically meaningless expressions when dealing with real physical systems, leading to poor model generalization. This limitation fundamentally stems from its deviation from the basic path of scientific discovery: physical laws do not exist in a single form but follow a hierarchical and progressive pattern from simplicity to complexity. Motivated by this principle, we propose Chain of Symbolic Regression (CoSR), a novel framework that models the discovery of physical laws as a chain of symbolic knowledge. This knowledge chain is formed by progressively combining multiple knowledge units with clear physical meanings along a specific logic, ultimately enabling the precise discovery of the underlying physical laws from data. CoSR fully recapitulates the progressive discovery path from Kepler's third law to the law of universal gravitation in classical mechanics, and is applied to three types of problems: turbulent Rayleigh-Benard convection, viscous flows in a circular pipe, and laser-metal interaction, demonstrating its ability to improve classical scaling theories. Finally, CoSR showcases its capability to discover new knowledge in the complex engineering problem of aerodynamic coefficients scaling for different aircraft.
Distributed Hybrid Parallelism for Large Language Models: Comparative Study and System Design Guide
Feb 09, 2026With the rapid growth of large language models (LLMs), a wide range of methods have been developed to distribute computation and memory across hardware devices for efficient training and inference. While existing surveys provide descriptive overviews of these techniques, systematic analysis of their benefits and trade offs and how such insights can inform principled methodology for designing optimal distributed systems remain limited. This paper offers a comprehensive review of collective operations and distributed parallel strategies, complemented by mathematical formulations to deepen theoretical understanding. We further examine hybrid parallelization designs, emphasizing communication computation overlap across different stages of model deployment, including both training and inference. Recent advances in automated search for optimal hybrid parallelization strategies using cost models are also discussed. Moreover, we present case studies with mainstream architecture categories to reveal empirical insights to guide researchers and practitioners in parallelism strategy selection. Finally, we highlight open challenges and limitations of current LLM training paradigms and outline promising directions for the next generation of large scale model development.
Neural Clothing Tryer: Customized Virtual Try-On via Semantic Enhancement and Controlling Diffusion Model
Jan 30, 2026This work aims to address a novel Customized Virtual Try-ON (Cu-VTON) task, enabling the superimposition of a specified garment onto a model that can be customized in terms of appearance, posture, and additional attributes. Compared with traditional VTON task, it enables users to tailor digital avatars to their individual preferences, thereby enhancing the virtual fitting experience with greater flexibility and engagement. To address this task, we introduce a Neural Clothing Tryer (NCT) framework, which exploits the advanced diffusion models equipped with semantic enhancement and controlling modules to better preserve semantic characterization and textural details of the garment and meanwhile facilitating the flexible editing of the model's postures and appearances. Specifically, NCT introduces a semantic-enhanced module to take semantic descriptions of garments and utilizes a visual-language encoder to learn aligned features across modalities. The aligned features are served as condition input to the diffusion model to enhance the preservation of the garment's semantics. Then, a semantic controlling module is designed to take the garment image, tailored posture image, and semantic description as input to maintain garment details while simultaneously editing model postures, expressions, and various attributes. Extensive experiments on the open available benchmark demonstrate the superior performance of the proposed NCT framework.
Structure-constrained Language-informed Diffusion Model for Unpaired Low-dose Computed Tomography Angiography Reconstruction
Jan 28, 2026The application of iodinated contrast media (ICM) improves the sensitivity and specificity of computed tomography (CT) for a wide range of clinical indications. However, overdose of ICM can cause problems such as kidney damage and life-threatening allergic reactions. Deep learning methods can generate CT images of normal-dose ICM from low-dose ICM, reducing the required dose while maintaining diagnostic power. However, existing methods are difficult to realize accurate enhancement with incompletely paired images, mainly because of the limited ability of the model to recognize specific structures. To overcome this limitation, we propose a Structure-constrained Language-informed Diffusion Model (SLDM), a unified medical generation model that integrates structural synergy and spatial intelligence. First, the structural prior information of the image is effectively extracted to constrain the model inference process, thus ensuring structural consistency in the enhancement process. Subsequently, semantic supervision strategy with spatial intelligence is introduced, which integrates the functions of visual perception and spatial reasoning, thus prompting the model to achieve accurate enhancement. Finally, the subtraction angiography enhancement module is applied, which serves to improve the contrast of the ICM agent region to suitable interval for observation. Qualitative analysis of visual comparison and quantitative results of several metrics demonstrate the effectiveness of our method in angiographic reconstruction for low-dose contrast medium CT angiography.
A universal linearized subspace refinement framework for neural networks
Jan 20, 2026Neural networks are predominantly trained using gradient-based methods, yet in many applications their final predictions remain far from the accuracy attainable within the model's expressive capacity. We introduce Linearized Subspace Refinement (LSR), a general and architecture-agnostic framework that exploits the Jacobian-induced linear residual model at a fixed trained network state. By solving a reduced direct least-squares problem within this subspace, LSR computes a subspace-optimal solution of the linearized residual model, yielding a refined linear predictor with substantially improved accuracy over standard gradient-trained solutions, without modifying network architectures, loss formulations, or training procedures. Across supervised function approximation, data-driven operator learning, and physics-informed operator fine-tuning, we show that gradient-based training often fails to access this attainable accuracy, even when local linearization yields a convex problem. This observation indicates that loss-induced numerical ill-conditioning, rather than nonconvexity or model expressivity, can constitute a dominant practical bottleneck. In contrast, one-shot LSR systematically exposes accuracy levels not fully exploited by gradient-based training, frequently achieving order-of-magnitude error reductions. For operator-constrained problems with composite loss structures, we further introduce Iterative LSR, which alternates one-shot LSR with supervised nonlinear alignment, transforming ill-conditioned residual minimization into numerically benign fitting steps and yielding accelerated convergence and improved accuracy. By bridging nonlinear neural representations with reduced-order linear solvers at fixed linearization points, LSR provides a numerically grounded and broadly applicable refinement framework for supervised learning, operator learning, and scientific computing.
FLOP-Efficient Training: Early Stopping Based on Test-Time Compute Awareness
Jan 04, 2026Scaling training compute, measured in FLOPs, has long been shown to improve the accuracy of large language models, yet training remains resource-intensive. Prior work shows that increasing test-time compute (TTC)-for example through iterative sampling-can allow smaller models to rival or surpass much larger ones at lower overall cost. We introduce TTC-aware training, where an intermediate checkpoint and a corresponding TTC configuration can together match or exceed the accuracy of a fully trained model while requiring substantially fewer training FLOPs. Building on this insight, we propose an early stopping algorithm that jointly selects a checkpoint and TTC configuration to minimize training compute without sacrificing accuracy. To make this practical, we develop an efficient TTC evaluation method that avoids exhaustive search, and we formalize a break-even bound that identifies when increased inference compute compensates for reduced training compute. Experiments demonstrate up to 92\% reductions in training FLOPs while maintaining and sometimes remarkably improving accuracy. These results highlight a new perspective for balancing training and inference compute in model development, enabling faster deployment cycles and more frequent model refreshes. Codes will be publicly released.
Bayesian Mixture of Experts For Large Language Models
Nov 12, 2025We present Bayesian Mixture of Experts (Bayesian-MoE), a post-hoc uncertainty estimation framework for fine-tuned large language models (LLMs) based on Mixture-of-Experts architectures. Our method applies a structured Laplace approximation to the second linear layer of each expert, enabling calibrated uncertainty estimation without modifying the original training procedure or introducing new parameters. Unlike prior approaches, which apply Bayesian inference to added adapter modules, Bayesian-MoE directly targets the expert pathways already present in MoE models, leveraging their modular design for tractable block-wise posterior estimation. We use Kronecker-factored low-rank approximations to model curvature and derive scalable estimates of predictive uncertainty and marginal likelihood. Experiments on common-sense reasoning benchmarks with Qwen1.5-MoE and DeepSeek-MoE demonstrate that Bayesian-MoE improves both expected calibration error (ECE) and negative log-likelihood (NLL) over baselines, confirming its effectiveness for reliable downstream decision-making.
Rethinking Schema Linking: A Context-Aware Bidirectional Retrieval Approach for Text-to-SQL
Oct 16, 2025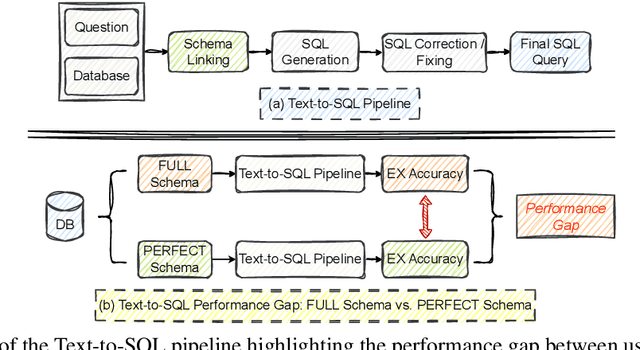
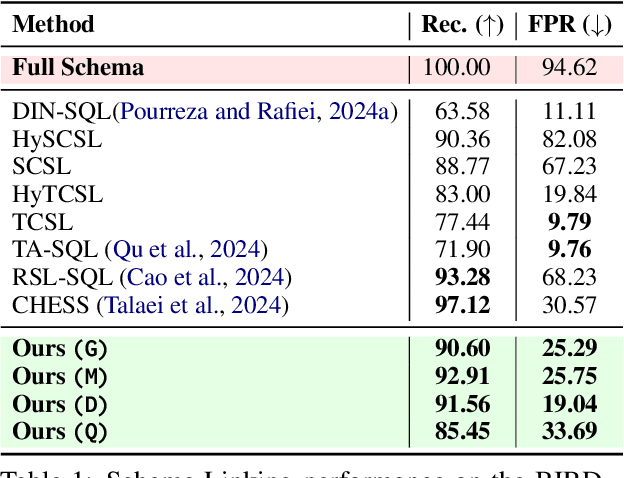
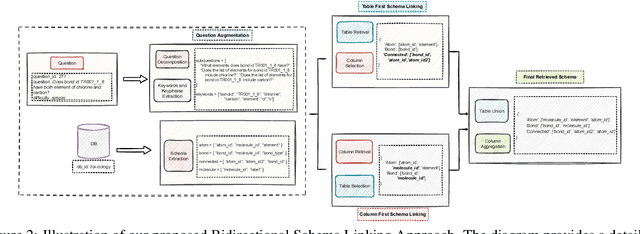
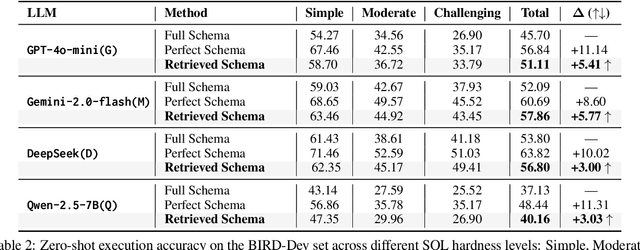
Schema linking -- the process of aligning natural language questions with database schema elements -- is a critical yet underexplored component of Text-to-SQL systems. While recent methods have focused primarily on improving SQL generation, they often neglect the retrieval of relevant schema elements, which can lead to hallucinations and execution failures. In this work, we propose a context-aware bidirectional schema retrieval framework that treats schema linking as a standalone problem. Our approach combines two complementary strategies: table-first retrieval followed by column selection, and column-first retrieval followed by table selection. It is further augmented with techniques such as question decomposition, keyword extraction, and keyphrase extraction. Through comprehensive evaluations on challenging benchmarks such as BIRD and Spider, we demonstrate that our method significantly improves schema recall while reducing false positives. Moreover, SQL generation using our retrieved schema consistently outperforms full-schema baselines and closely approaches oracle performance, all without requiring query refinement. Notably, our method narrows the performance gap between full and perfect schema settings by 50\%. Our findings highlight schema linking as a powerful lever for enhancing Text-to-SQL accuracy and efficiency.