 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Horizon Plan Execution in Large Tool Spaces through Entropy-Guided Branching
Apr 13, 2026Large Language Models (LLMs) have significantly advanced tool-augmented agents, enabling autonomous reasoning via API interactions. However, executing multi-step tasks within massive tool libraries remains challenging due to two critical bottlenecks: (1) the absence of rigorous, plan-level evaluation frameworks and (2) the computational demand of exploring vast decision spaces stemming from large toolsets and long-horizon planning. To bridge these gaps, we first introduce SLATE (Synthetic Large-scale API Toolkit for E-commerce), a large-scale context-aware benchmark designed for the automated assessment of tool-integrated agents. Unlike static metrics, SLATE accommodates diverse yet functionally valid execution trajectories, revealing that current agents struggle with self-correction and search efficiency. Motivated by these findings, we next propose Entropy-Guided Branching (EGB), an uncertainty-aware search algorithm that dynamically expands decision branches where predictive entropy is high. EGB optimizes the exploration-exploitation trade-off, significantly enhancing both task success rates and computational efficiency. Extensive experiments on SLATE demonstrate that our dual contribution provides a robust foundation for developing reliable and scalable LLM agents in tool-rich environments.
Grasp Synthesis Matching From Rigid To Soft Robot Grippers Using Conditional Flow Matching
Feb 19, 2026A representation gap exists between grasp synthesis for rigid and soft grippers. Anygrasp [1] and many other grasp synthesis methods are designed for rigid parallel grippers, and adapting them to soft grippers often fails to capture their unique compliant behaviors, resulting in data-intensive and inaccurate models. To bridge this gap, this paper proposes a novel framework to map grasp poses from a rigid gripper model to a soft Fin-ray gripper. We utilize Conditional Flow Matching (CFM), a generative model, to learn this complex transformation. Our methodology includes a data collection pipeline to generate paired rigid-soft grasp poses. A U-Net autoencoder conditions the CFM model on the object's geometry from a depth image, allowing it to learn a continuous mapping from an initial Anygrasp pose to a stable Fin-ray gripper pose. We validate our approach on a 7-DOF robot, demonstrating that our CFM-generated poses achieve a higher overall success rate for seen and unseen objects (34% and 46% respectively) compared to the baseline rigid poses (6% and 25% respectively) when executed by the soft gripper. The model shows significant improvements, particularly for cylindrical (50% and 100% success for seen and unseen objects) and spherical objects (25% and 31% success for seen and unseen objects), and successfully generalizes to unseen objects. This work presents CFM as a data-efficient and effective method for transferring grasp strategies, offering a scalable methodology for other soft robotic systems.
Enhancing Learned Knowledge in LoRA Adapters Through Efficient Contrastive Decoding on Ascend NPUs
May 20, 2025Huawei Cloud users leverage LoRA (Low-Rank Adaptation) as an efficient and scalable method to fine-tune and customize large language models (LLMs) for application-specific needs. However, tasks that require complex reasoning or deep contextual understanding are often hindered by biases or interference from the base model when using typical decoding methods like greedy or beam search. These biases can lead to generic or task-agnostic responses from the base model instead of leveraging the LoRA-specific adaptations. In this paper, we introduce Contrastive LoRA Decoding (CoLD), a novel decoding framework designed to maximize the use of task-specific knowledge in LoRA-adapted models, resulting in better downstream performance. CoLD uses contrastive decoding by scoring candidate tokens based on the divergence between the probability distributions of a LoRA-adapted expert model and the corresponding base model. This approach prioritizes tokens that better align with the LoRA's learned representations, enhancing performance for specialized tasks. While effective, a naive implementation of CoLD is computationally expensive because each decoding step requires evaluating multiple token candidates across both models. To address this, we developed an optimized kernel for Huawei's Ascend NPU. CoLD achieves up to a 5.54% increase in task accuracy while reducing end-to-end latency by 28% compared to greedy decoding. This work provides practical and efficient decoding strategies for fine-tuned LLMs in resource-constrained environments and has broad implications for applied data science in both cloud and on-premises settings.
LossLens: Diagnostics for Machine Learning through Loss Landscape Visual Analytics
Dec 17, 2024



Modern machine learning often relies on optimizing a neural network's parameters using a loss function to learn complex features. Beyond training, examining the loss function with respect to a network's parameters (i.e., as a loss landscape) can reveal insights into the architecture and learning process. While the local structure of the loss landscape surrounding an individual solution can be characterized using a variety of approaches, the global structure of a loss landscape, which includes potentially many local minima corresponding to different solutions, remains far more difficult to conceptualize and visualize. To address this difficulty, we introduce LossLens, a visual analytics framework that explores loss landscapes at multiple scales. LossLens integrates metrics from global and local scales into a comprehensive visual representation, enhancing model diagnostics. We demonstrate LossLens through two case studies: visualizing how residual connections influence a ResNet-20, and visualizing how physical parameters influence a physics-informed neural network (PINN) solving a simple convection problem.
SoGraB: A Visual Method for Soft Grasping Benchmarking and Evaluation
Nov 28, 2024Recent years have seen soft robotic grippers gain increasing attention due to their ability to robustly grasp soft and fragile objects. However, a commonly available standardised evaluation protocol has not yet been developed to assess the performance of varying soft robotic gripper designs. This work introduces a novel protocol, the Soft Grasping Benchmarking and Evaluation (SoGraB) method, to evaluate grasping quality, which quantifies object deformation by using the Density-Aware Chamfer Distance (DCD) between point clouds of soft objects before and after grasping. We validated our protocol in extensive experiments, which involved ranking three Fin-Ray gripper designs with a subset of the EGAD object dataset. The protocol appropriately ranked grippers based on object deformation information, validating the method's ability to select soft grippers for complex grasping tasks and benchmark them for comparison against future designs.
DexGrip: Multi-modal Soft Gripper with Dexterous Grasping and In-hand Manipulation Capacity
Nov 26, 2024



The ability of robotic grippers to not only grasp but also re-position and re-orient objects in-hand is crucial for achieving versatile, general-purpose manipulation. While recent advances in soft robotic grasping has greatly improved grasp quality and stability, their manipulation capabilities remain under-explored. This paper presents the DexGrip, a multi-modal soft robotic gripper for in-hand grasping, re-orientation and manipulation. DexGrip features a 3 Degrees of Freedom (DoFs) active suction palm and 3 active (rotating) grasping surfaces, enabling soft, stable, and dexterous grasping and manipulation without ever needing to re-grasp an object. Uniquely, these features enable complete 360 degree rotation in all three principal axes. We experimentally demonstrate these capabilities across a diverse set of objects and tasks. DexGrip successfully grasped, re-positioned, and re-oriented objects with widely varying stiffnesses, sizes, weights, and surface textures; and effectively manipulated objects that presented significant challenges for existing robotic grippers.
Visualizing Loss Functions as Topological Landscape Profiles
Nov 19, 2024



In machine learning, a loss function measures the difference between model predictions and ground-truth (or target) values. For neural network models, visualizing how this loss changes as model parameters are varied can provide insights into the local structure of the so-called loss landscape (e.g., smoothness) as well as global properties of the underlying model (e.g., generalization performance). While various methods for visualizing the loss landscape have been proposed, many approaches limit sampling to just one or two directions, ignoring potentially relevant information in this extremely high-dimensional space. This paper introduces a new representation based on topological data analysis that enables the visualization of higher-dimensional loss landscapes. After describing this new topological landscape profile representation, we show how the shape of loss landscapes can reveal new details about model performance and learning dynamics, highlighting several use cases, including image segmentation (e.g., UNet) and scientific machine learning (e.g., physics-informed neural networks). Through these examples, we provide new insights into how loss landscapes vary across distinct hyperparameter spaces: we find that the topology of the loss landscape is simpler for better-performing models; and we observe greater variation in the shape of loss landscapes near transitions from low to high model performance.
Enhancing Skin Lesion Diagnosis with Ensemble Learning
Sep 06, 2024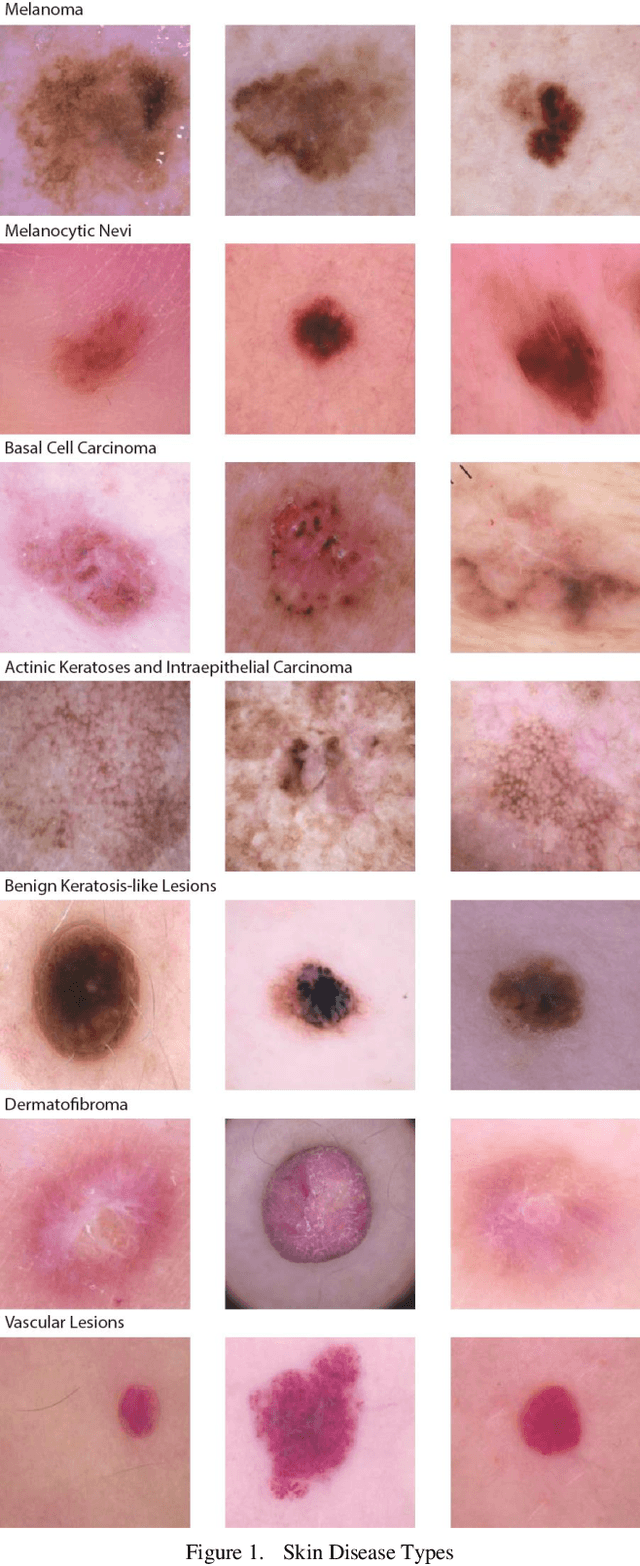
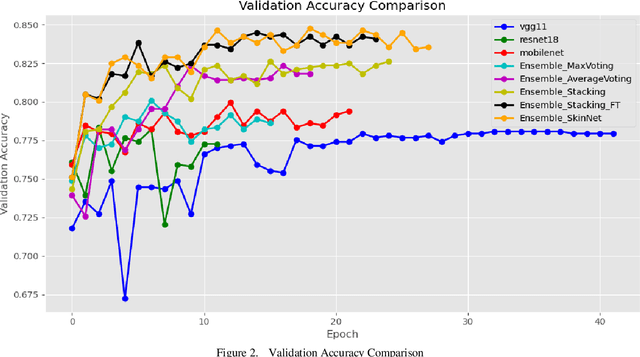
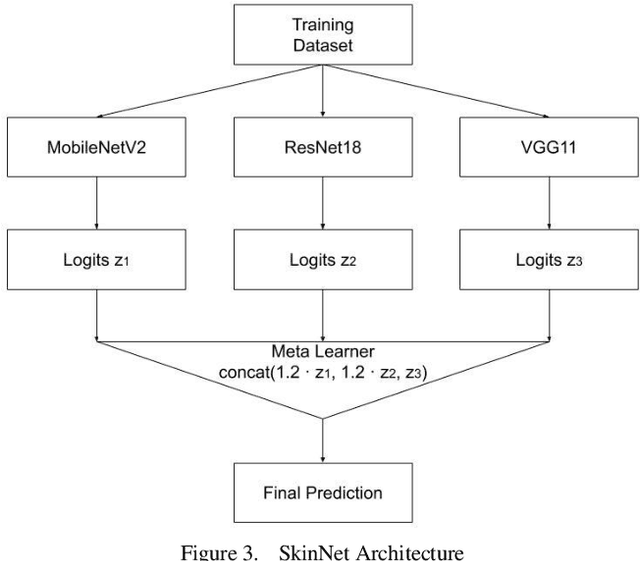
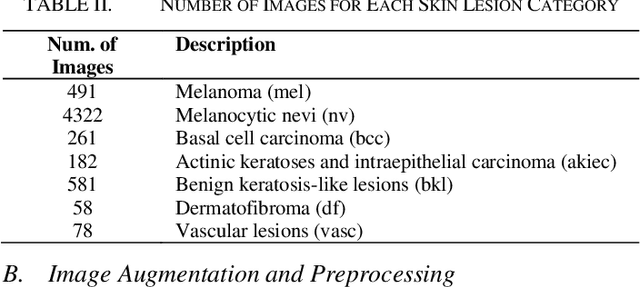
Skin lesions are an increasingly significant medical concern, varying widely in severity from benign to cancerous. Accurate diagnosis is essential for ensuring timely and appropriate treatment. This study examines the implementation of deep learning methods to assist in the diagnosis of skin lesions using the HAM10000 dataset, which contains seven distinct types of lesions. First, we evaluated three pre-trained models: MobileNetV2, ResNet18, and VGG11, achieving accuracies of 0.798, 0.802, and 0.805, respectively. To further enhance classification accuracy, we developed ensemble models employing max voting, average voting, and stacking, resulting in accuracies of 0.803, 0.82, and 0.83. Building on the best-performing ensemble learning model, stacking, we developed our proposed model, SkinNet, which incorporates a customized architecture and fine-tuning, achieving an accuracy of 0.867 and an AUC of 0.96. This substantial improvement over individual models demonstrates the effectiveness of ensemble learning in improving skin lesion classification.
PoliPrompt: A High-Performance Cost-Effective LLM-Based Text Classification Framework for Political Science
Sep 02, 2024



Recent advancements in large language models (LLMs) have opened new avenues for enhancing text classification efficiency in political science, surpassing traditional machine learning methods that often require extensive feature engineering, human labeling, and task-specific training. However, their effectiveness in achieving high classification accuracy remains questionable. This paper introduces a three-stage in-context learning approach that leverages LLMs to improve classification accuracy while minimizing experimental costs. Our method incorporates automatic enhanced prompt generation, adaptive exemplar selection, and a consensus mechanism that resolves discrepancies between two weaker LLMs, refined by an advanced LLM. We validate our approach using datasets from the BBC news reports, Kavanaugh Supreme Court confirmation, and 2018 election campaign ads. The results show significant improvements in classification F1 score (+0.36 for zero-shot classification) with manageable economic costs (-78% compared with human labeling), demonstrating that our method effectively addresses the limitations of traditional machine learning while offering a scalable and reliable solution for text analysis in political science.
ChaosMining: A Benchmark to Evaluate Post-Hoc Local Attribution Methods in Low SNR Environments
Jun 17, 2024



In this study, we examine the efficacy of post-hoc local attribution methods in identifying features with predictive power from irrelevant ones in domains characterized by a low signal-to-noise ratio (SNR), a common scenario in real-world machine learning applications. We developed synthetic datasets encompassing symbolic functional, image, and audio data, incorporating a benchmark on the {\it (Model \(\times\) Attribution\(\times\) Noise Condition)} triplet. By rigorously testing various classic models trained from scratch, we gained valuable insights into the performance of these attribution methods in multiple conditions. Based on these findings, we introduce a novel extension to the notable recursive feature elimination (RFE) algorithm, enhancing its applicability for neural networks. Our experiments highlight its strengths in prediction and feature selection, alongside limitations in scalability. Further details and additional minor findings are included in the appendix, with extensive discussions. The codes and resources are available at \href{https://github.com/geshijoker/ChaosMining/}{URL}.