 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoGraB: A Visual Method for Soft Grasping Benchmarking and Evaluation
Nov 28, 2024Recent years have seen soft robotic grippers gain increasing attention due to their ability to robustly grasp soft and fragile objects. However, a commonly available standardised evaluation protocol has not yet been developed to assess the performance of varying soft robotic gripper designs. This work introduces a novel protocol, the Soft Grasping Benchmarking and Evaluation (SoGraB) method, to evaluate grasping quality, which quantifies object deformation by using the Density-Aware Chamfer Distance (DCD) between point clouds of soft objects before and after grasping. We validated our protocol in extensive experiments, which involved ranking three Fin-Ray gripper designs with a subset of the EGAD object dataset. The protocol appropriately ranked grippers based on object deformation information, validating the method's ability to select soft grippers for complex grasping tasks and benchmark them for comparison against future designs.
Exploratory Models of Human-AI Teams: Leveraging Human Digital Twins to Investigate Trust Development
Nov 01, 2024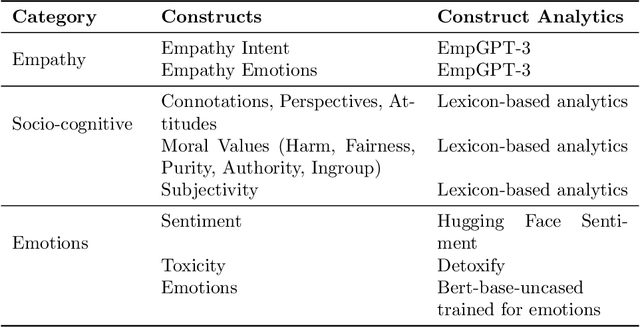
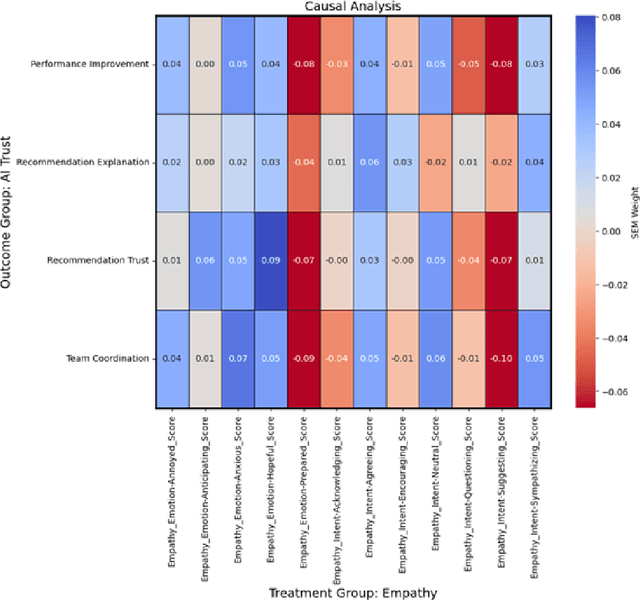
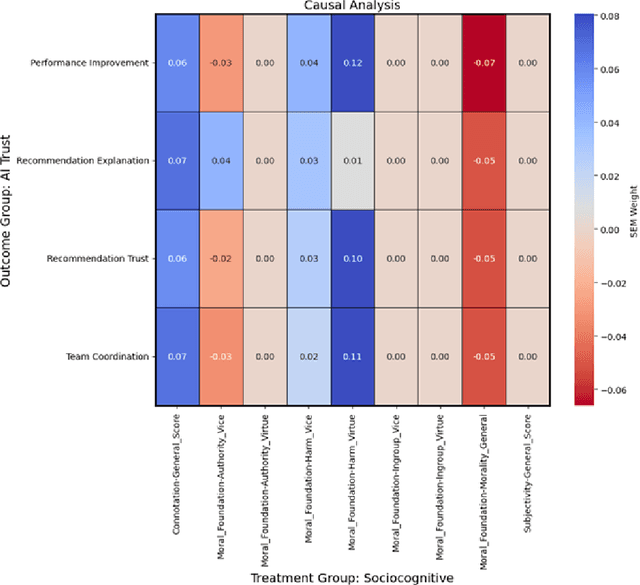
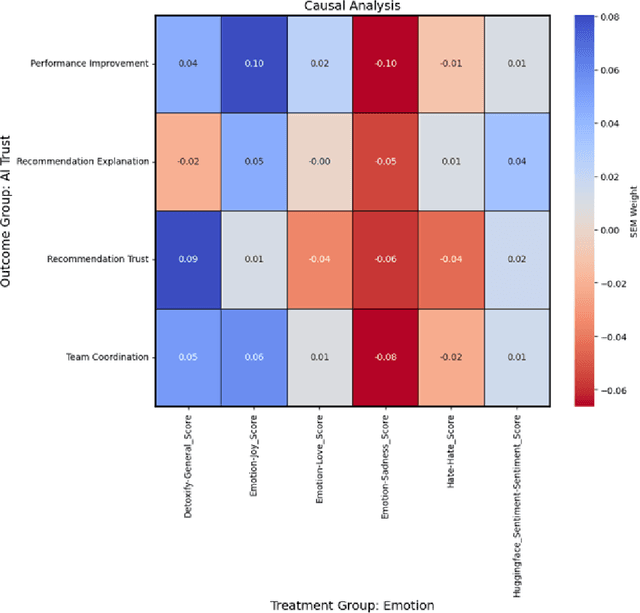
As human-agent teaming (HAT) research continues to grow, computational methods for modeling HAT behaviors and measuring HAT effectiveness also continue to develop. One rising method involves the use of human digital twins (HDT) to approximate human behaviors and socio-emotional-cognitive reactions to AI-driven agent team members. In this paper, we address three research questions relating to the use of digital twins for modeling trust in HATs. First, to address the question of how we can appropriately model and operationalize HAT trust through HDT HAT experiments, we conducted causal analytics of team communication data to understand the impact of empathy, socio-cognitive, and emotional constructs on trust formation. Additionally, we reflect on the current state of the HAT trust science to discuss characteristics of HAT trust that must be replicable by a HDT such as individual differences in trust tendencies, emergent trust patterns, and appropriate measurement of these characteristics over time. Second, to address the question of how valid measures of HDT trust are for approximating human trust in HATs, we discuss the properties of HDT trust: self-report measures, interaction-based measures, and compliance type behavioral measures. Additionally, we share results of preliminary simulations comparing different LLM models for generating HDT communications and analyze their ability to replicate human-like trust dynamics. Third, to address how HAT experimental manipulations will extend to human digital twin studies, we share experimental design focusing on propensity to trust for HDTs vs. transparency and competency-based trust for AI agents.
A Scalable and Extensible Approach to Benchmarking NL2Code for 18 Programming Languages
Aug 19, 2022
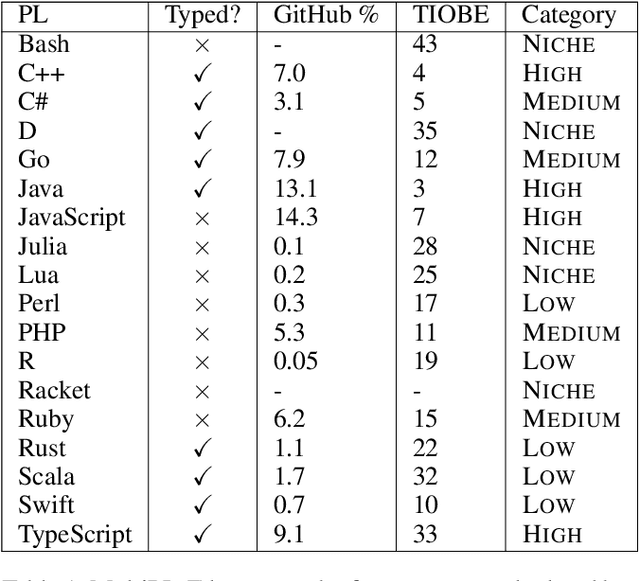

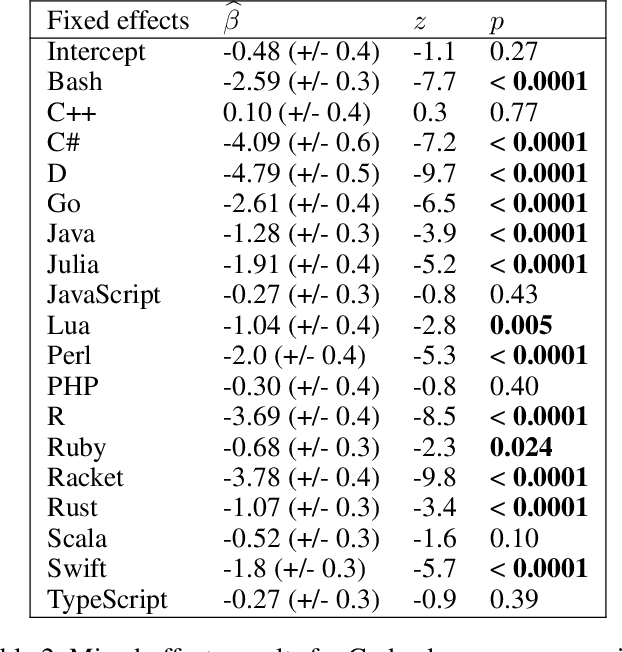
Large language models have demonstrated the ability to condition on and generate both natural language and programming language text. Such models open up the possibility of multi-language code generation: could code generation models generalize knowledge from one language to another? Although contemporary code generation models can generate semantically correct Python code, little is known about their abilities with other languages. We facilitate the exploration of this topic by proposing MultiPL-E, the first multi-language parallel benchmark for natural-language-to-code-generation. MultiPL-E extends the HumanEval benchmark (Chen et al, 2021) to support 18 more programming languages, encompassing a range of programming paradigms and popularity. We evaluate two state-of-the-art code generation models on MultiPL-E: Codex and InCoder. We find that on several languages, Codex matches and even exceeds its performance on Python. The range of programming languages represented in MultiPL-E allow us to explore the impact of language frequency and language features on model performance. Finally, the MultiPL-E approach of compiling code generation benchmarks to new programming languages is both scalable and extensible. We describe a general approach for easily adding support for new benchmarks and languages to MultiPL-E.