 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploratory Models of Human-AI Teams: Leveraging Human Digital Twins to Investigate Trust Development
Nov 01, 2024
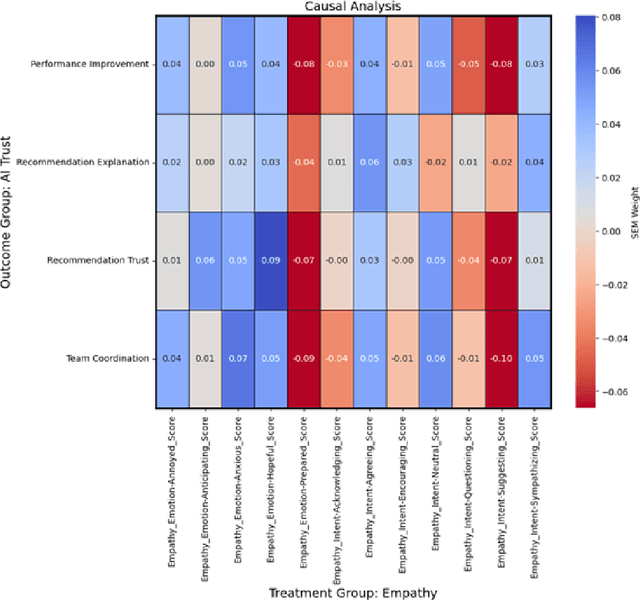
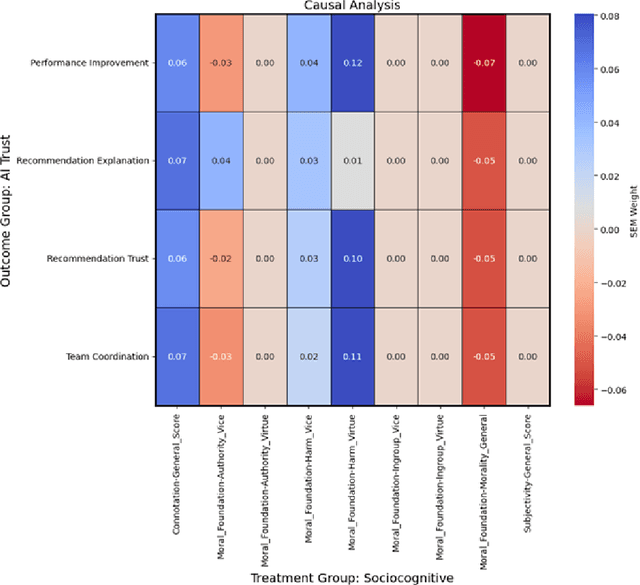
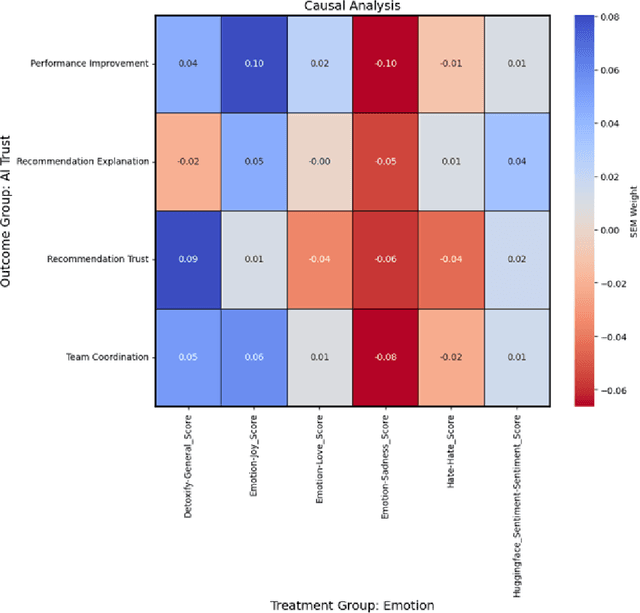
As human-agent teaming (HAT) research continues to grow, computational methods for modeling HAT behaviors and measuring HAT effectiveness also continue to develop. One rising method involves the use of human digital twins (HDT) to approximate human behaviors and socio-emotional-cognitive reactions to AI-driven agent team members. In this paper, we address three research questions relating to the use of digital twins for modeling trust in HATs. First, to address the question of how we can appropriately model and operationalize HAT trust through HDT HAT experiments, we conducted causal analytics of team communication data to understand the impact of empathy, socio-cognitive, and emotional constructs on trust formation. Additionally, we reflect on the current state of the HAT trust science to discuss characteristics of HAT trust that must be replicable by a HDT such as individual differences in trust tendencies, emergent trust patterns, and appropriate measurement of these characteristics over time. Second, to address the question of how valid measures of HDT trust are for approximating human trust in HATs, we discuss the properties of HDT trust: self-report measures, interaction-based measures, and compliance type behavioral measures. Additionally, we share results of preliminary simulations comparing different LLM models for generating HDT communications and analyze their ability to replicate human-like trust dynamics. Third, to address how HAT experimental manipulations will extend to human digital twin studies, we share experimental design focusing on propensity to trust for HDTs vs. transparency and competency-based trust for AI agents.
Modeling Information Narrative Detection and Evolution on Telegram during the Russia-Ukraine War
Sep 12, 2024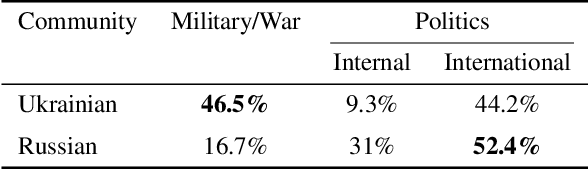
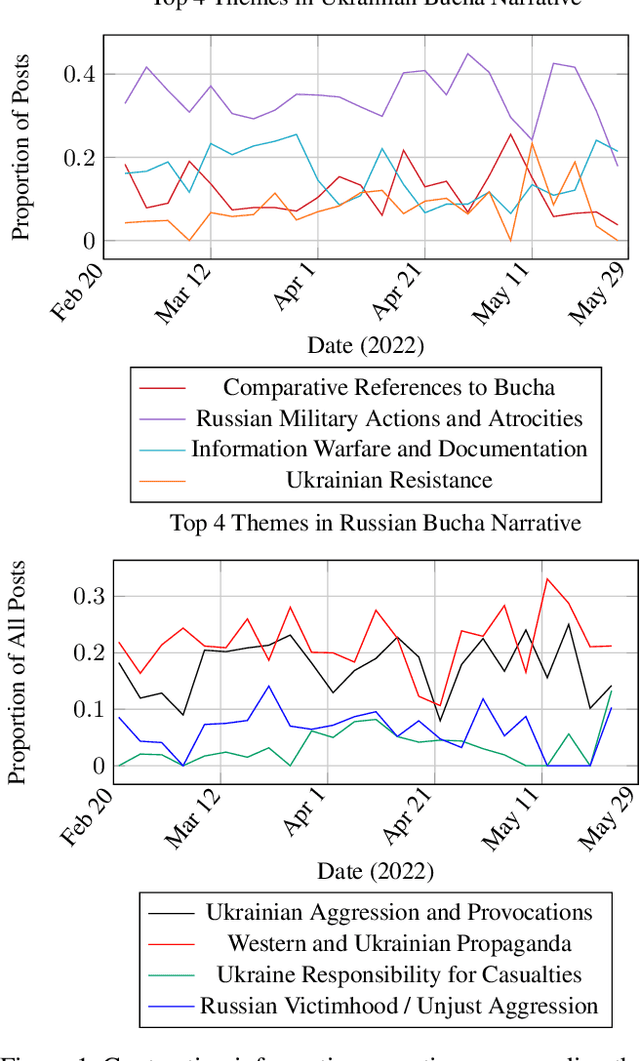
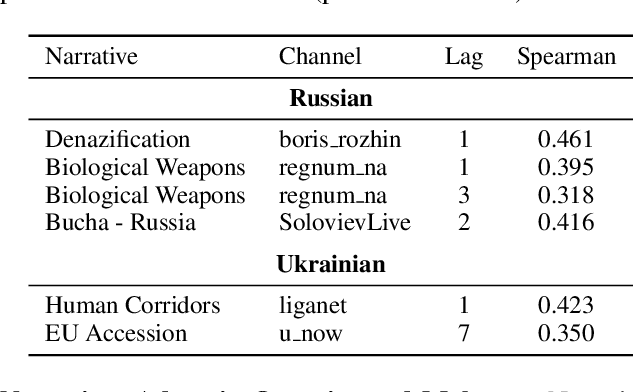
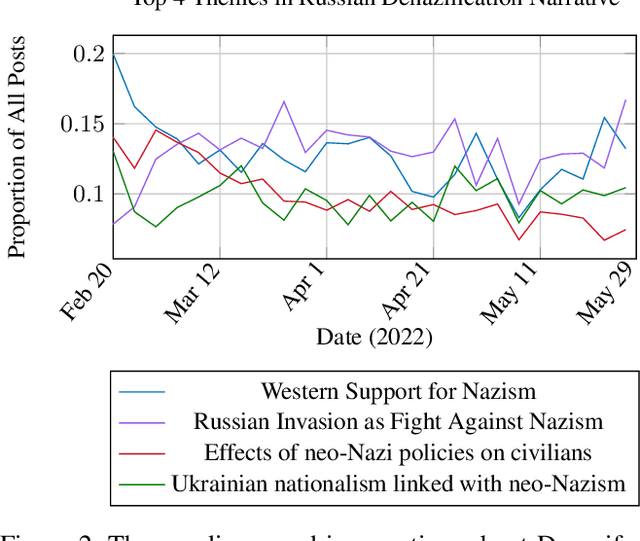
Following the Russian Federation's full-scale invasion of Ukraine in February 2022, a multitude of information narratives emerged within both pro-Russian and pro-Ukrainian communities online. As the conflict progresses, so too do the information narratives, constantly adapting and influencing local and global community perceptions and attitudes. This dynamic nature of the evolving information environment (IE) underscores a critical need to fully discern how narratives evolve and affect online communities. Existing research, however, often fails to capture information narrative evolution, overlooking both the fluid nature of narratives and the internal mechanisms that drive their evolution. Recognizing this, we introduce a novel approach designed to both model narrative evolution and uncover the underlying mechanisms driving them. In this work we perform a comparative discourse analysis across communities on Telegram covering the initial three months following the invasion. First, we uncover substantial disparities in narratives and perceptions between pro-Russian and pro-Ukrainian communities. Then, we probe deeper into prevalent narratives of each group, identifying key themes and examining the underlying mechanisms fueling their evolution. Finally, we explore influences and factors that may shape the development and spread of narratives.
Towards Safer Online Spaces: Simulating and Assessing Intervention Strategies for Eating Disorder Discussions
Sep 06, 2024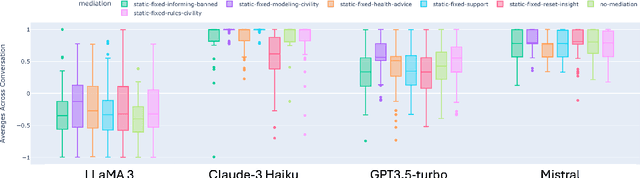

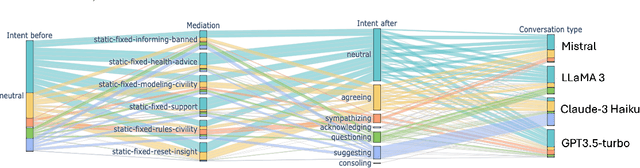
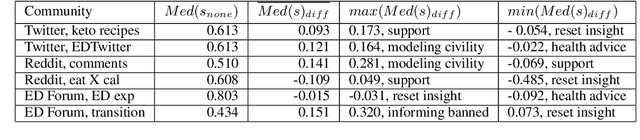
Eating disorders are complex mental health conditions that affect millions of people around the world. Effective interventions on social media platforms are crucial, yet testing strategies in situ can be risky. We present a novel LLM-driven experimental testbed for simulating and assessing intervention strategies in ED-related discussions. Our framework generates synthetic conversations across multiple platforms, models, and ED-related topics, allowing for controlled experimentation with diverse intervention approaches. We analyze the impact of various intervention strategies on conversation dynamics across four dimensions: intervention type, generative model, social media platform, and ED-related community/topic. We employ cognitive domain analysis metrics, including sentiment, emotions, etc., to evaluate the effectiveness of interventions. Our findings reveal that civility-focused interventions consistently improve positive sentiment and emotional tone across all dimensions, while insight-resetting approaches tend to increase negative emotions. We also uncover significant biases in LLM-generated conversations, with cognitive metrics varying notably between models (Claude-3 Haiku $>$ Mistral $>$ GPT-3.5-turbo $>$ LLaMA3) and even between versions of the same model. These variations highlight the importance of model selection in simulating realistic discussions related to ED. Our work provides valuable information on the complex dynamics of ED-related discussions and the effectiveness of various intervention strategies.
"Im not Racist but": Discovering Bias in the Internal Knowledge of Large Language Models
Oct 13, 2023Large language models (LLMs) have garnered significant attention for their remarkable performance in a continuously expanding set of natural language processing tasks. However, these models have been shown to harbor inherent societal biases, or stereotypes, which can adversely affect their performance in their many downstream applications. In this paper, we introduce a novel, purely prompt-based approach to uncover hidden stereotypes within any arbitrary LLM. Our approach dynamically generates a knowledge representation of internal stereotypes, enabling the identification of biases encoded within the LLM's internal knowledge. By illuminating the biases present in LLMs and offering a systematic methodology for their analysis, our work contributes to advancing transparency and promoting fairness in natural language processing systems.