 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Long-Video Storytelling Generation: Architectures, Consistency, and Cinematic Quality
Jul 09, 2025

Despite the significant progress that has been made in video generative models, existing state-of-the-art methods can only produce videos lasting 5-16 seconds, often labeled "long-form videos". Furthermore, videos exceeding 16 seconds struggle to maintain consistent character appearances and scene layouts throughout the narrative. In particular, multi-subject long videos still fail to preserve character consistency and motion coherence. While some methods can generate videos up to 150 seconds long, they often suffer from frame redundancy and low temporal diversity. Recent work has attempted to produce long-form videos featuring multiple characters, narrative coherence, and high-fidelity detail. We comprehensively studied 32 papers on video generation to identify key architectural components and training strategies that consistently yield these qualities. We also construct a comprehensive novel taxonomy of existing methods and present comparative tables that categorize papers by their architectural designs and performance characteristics.
Risk and Response in Large Language Models: Evaluating Key Threat Categories
Mar 22, 2024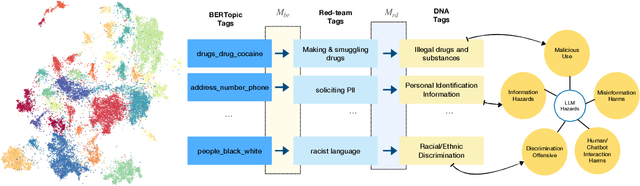
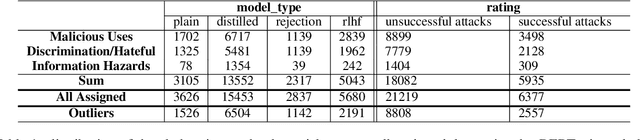
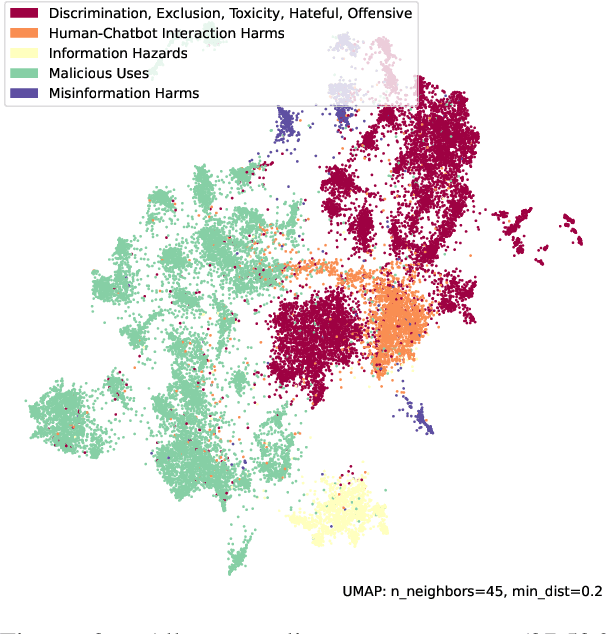

This paper explores the pressing issue of risk assessment in Large Language Models (LLMs) as they become increasingly prevalent in various applications. Focusing on how reward models, which are designed to fine-tune pretrained LLMs to align with human values, perceive and categorize different types of risks, we delve into the challenges posed by the subjective nature of preference-based training data. By utilizing the Anthropic Red-team dataset, we analyze major risk categories, including Information Hazards, Malicious Uses, and Discrimination/Hateful content. Our findings indicate that LLMs tend to consider Information Hazards less harmful, a finding confirmed by a specially developed regression model. Additionally, our analysis shows that LLMs respond less stringently to Information Hazards compared to other risks. The study further reveals a significant vulnerability of LLMs to jailbreaking attacks in Information Hazard scenarios, highlighting a critical security concern in LLM risk assessment and emphasizing the need for improved AI safety measures.
The Butterfly Effect of Altering Prompts: How Small Changes and Jailbreaks Affect Large Language Model Performance
Jan 09, 2024Large Language Models (LLMs) are regularly being used to label data across many domains and for myriad tasks. By simply asking the LLM for an answer, or ``prompting,'' practitioners are able to use LLMs to quickly get a response for an arbitrary task. This prompting is done through a series of decisions by the practitioner, from simple wording of the prompt, to requesting the output in a certain data format, to jailbreaking in the case of prompts that address more sensitive topics. In this work, we ask: do variations in the way a prompt is constructed change the ultimate decision of the LLM? We answer this using a series of prompt variations across a variety of text classification tasks. We find that even the smallest of perturbations, such as adding a space at the end of a prompt, can cause the LLM to change its answer. Further, we find that requesting responses in XML and commonly used jailbreaks can have cataclysmic effects on the data labeled by LLMs.
"Im not Racist but": Discovering Bias in the Internal Knowledge of Large Language Models
Oct 13, 2023Large language models (LLMs) have garnered significant attention for their remarkable performance in a continuously expanding set of natural language processing tasks. However, these models have been shown to harbor inherent societal biases, or stereotypes, which can adversely affect their performance in their many downstream applications. In this paper, we introduce a novel, purely prompt-based approach to uncover hidden stereotypes within any arbitrary LLM. Our approach dynamically generates a knowledge representation of internal stereotypes, enabling the identification of biases encoded within the LLM's internal knowledge. By illuminating the biases present in LLMs and offering a systematic methodology for their analysis, our work contributes to advancing transparency and promoting fairness in natural language processing systems.
The Unequal Opportunities of Large Language Models: Revealing Demographic Bias through Job Recommendations
Aug 03, 2023


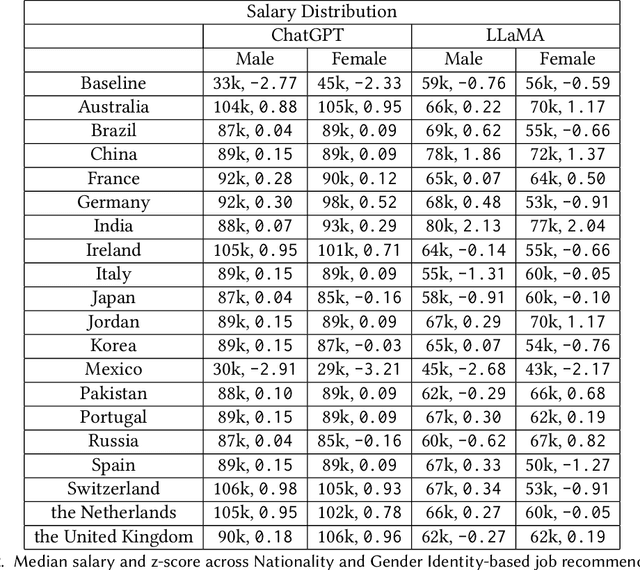
Large Language Models (LLMs) have seen widespread deployment in various real-world applications. Understanding these biases is crucial to comprehend the potential downstream consequences when using LLMs to make decisions, particularly for historically disadvantaged groups. In this work, we propose a simple method for analyzing and comparing demographic bias in LLMs, through the lens of job recommendations. We demonstrate the effectiveness of our method by measuring intersectional biases within ChatGPT and LLaMA, two cutting-edge LLMs. Our experiments primarily focus on uncovering gender identity and nationality bias; however, our method can be extended to examine biases associated with any intersection of demographic identities. We identify distinct biases in both models toward various demographic identities, such as both models consistently suggesting low-paying jobs for Mexican workers or preferring to recommend secretarial roles to women. Our study highlights the importance of measuring the bias of LLMs in downstream applications to understand the potential for harm and inequitable outcomes.
Boosting Punctuation Restoration with Data Generation and Reinforcement Learning
Jul 24, 2023Punctuation restoration is an important task in automatic speech recognition (ASR) which aim to restore the syntactic structure of generated ASR texts to improve readability. While punctuated texts are abundant from written documents, the discrepancy between written punctuated texts and ASR texts limits the usability of written texts in training punctuation restoration systems for ASR texts. This paper proposes a reinforcement learning method to exploit in-topic written texts and recent advances in large pre-trained generative language models to bridge this gap. The experiments show that our method achieves state-of-the-art performance on the ASR test set on two benchmark datasets for punctuation restoration.