 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Prompting With Episodic Memory
Aug 14, 2024Prompt optimization is essential for enhancing the performance of Large Language Models (LLMs) in a range of Natural Language Processing (NLP) tasks, particularly in scenarios of few-shot learning where training examples are incorporated directly into the prompt. Despite the growing interest in optimizing prompts with few-shot examples, existing methods for prompt optimization are often resource-intensive or perform inadequately. In this work, we propose PrOmpting with Episodic Memory (POEM), a novel prompt optimization technique that is simple, efficient, and demonstrates strong generalization capabilities. We approach prompt optimization as a Reinforcement Learning (RL) challenge, using episodic memory to archive combinations of input data, permutations of few-shot examples, and the rewards observed during training. In the testing phase, we optimize the sequence of examples for each test query by selecting the sequence that yields the highest total rewards from the top-k most similar training examples in the episodic memory. Our results show that POEM outperforms recent techniques like TEMPERA and RLPrompt by over 5.3% in various text classification tasks. Furthermore, our approach adapts well to broader language understanding tasks, consistently outperforming conventional heuristic methods for ordering examples.
Multi-Reference Preference Optimization for Large Language Models
May 26, 2024



How can Large Language Models (LLMs) be aligned with human intentions and values? A typical solution is to gather human preference on model outputs and finetune the LLMs accordingly while ensuring that updates do not deviate too far from a reference model. Recent approaches, such as direct preference optimization (DPO), have eliminated the need for unstable and sluggish reinforcement learning optimization by introducing close-formed supervised losses. However, a significant limitation of the current approach is its design for a single reference model only, neglecting to leverage the collective power of numerous pretrained LLMs. To overcome this limitation, we introduce a novel closed-form formulation for direct preference optimization using multiple reference models. The resulting algorithm, Multi-Reference Preference Optimization (MRPO), leverages broader prior knowledge from diverse reference models, substantially enhancing preference learning capabilities compared to the single-reference DPO. Our experiments demonstrate that LLMs finetuned with MRPO generalize better in various preference data, regardless of data scarcity or abundance. Furthermore, MRPO effectively finetunes LLMs to exhibit superior performance in several downstream natural language processing tasks such as GSM8K and TruthfulQA.
Fine-tuning CLIP Text Encoders with Two-step Paraphrasing
Feb 23, 2024



Contrastive language-image pre-training (CLIP) models have demonstrated considerable success across various vision-language tasks, such as text-to-image retrieval, where the model is required to effectively process natural language input to produce an accurate visual output. However, current models still face limitations in dealing with linguistic variations in input queries, such as paraphrases, making it challenging to handle a broad range of user queries in real-world applications. In this study, we introduce a straightforward fine-tuning approach to enhance the representations of CLIP models for paraphrases. Our approach involves a two-step paraphrase generation process, where we automatically create two categories of paraphrases from web-scale image captions by leveraging large language models. Subsequently, we fine-tune the CLIP text encoder using these generated paraphrases while freezing the image encoder. Our resulting model, which we call ParaCLIP, exhibits significant improvements over baseline CLIP models across various tasks, including paraphrased retrieval (with rank similarity scores improved by up to 2.0% and 5.6%), Visual Genome Relation and Attribution, as well as seven semantic textual similarity tasks.
Multi-Modal Video Topic Segmentation with Dual-Contrastive Domain Adaptation
Nov 30, 2023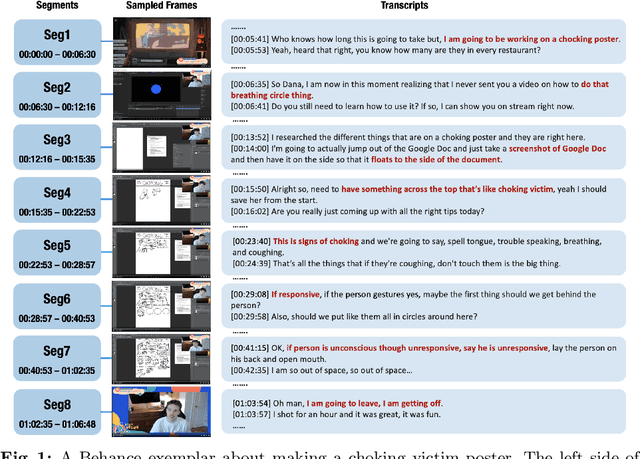
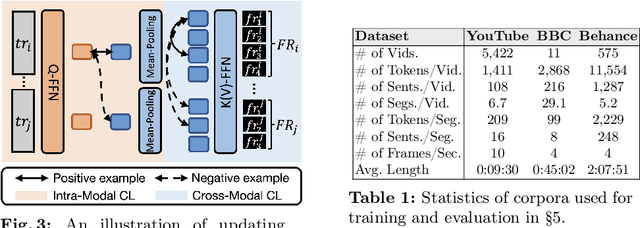
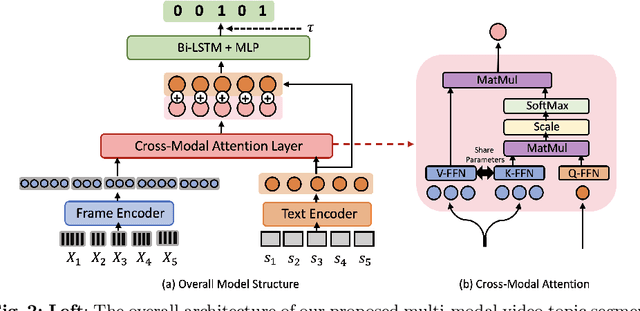
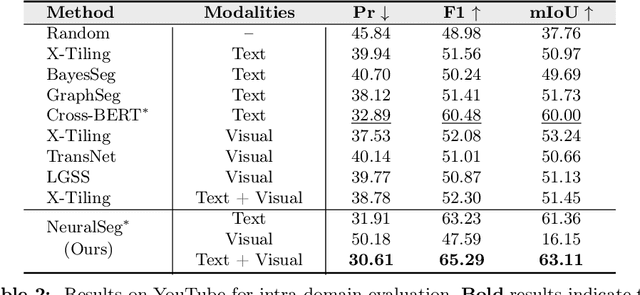
Video topic segmentation unveils the coarse-grained semantic structure underlying videos and is essential for other video understanding tasks. Given the recent surge in multi-modal, relying solely on a single modality is arguably insufficient. On the other hand, prior solutions for similar tasks like video scene/shot segmentation cater to short videos with clear visual shifts but falter for long videos with subtle changes, such as livestreams. In this paper, we introduce a multi-modal video topic segmenter that utilizes both video transcripts and frames, bolstered by a cross-modal attention mechanism. Furthermore, we propose a dual-contrastive learning framework adhering to the unsupervised domain adaptation paradigm, enhancing our model's adaptability to longer, more semantically complex videos. Experiments on short and long video corpora demonstrate that our proposed solution, significantly surpasses baseline methods in terms of both accuracy and transferability, in both intra- and cross-domain settings.
Boosting Punctuation Restoration with Data Generation and Reinforcement Learning
Jul 24, 2023Punctuation restoration is an important task in automatic speech recognition (ASR) which aim to restore the syntactic structure of generated ASR texts to improve readability. While punctuated texts are abundant from written documents, the discrepancy between written punctuated texts and ASR texts limits the usability of written texts in training punctuation restoration systems for ASR texts. This paper proposes a reinforcement learning method to exploit in-topic written texts and recent advances in large pre-trained generative language models to bridge this gap. The experiments show that our method achieves state-of-the-art performance on the ASR test set on two benchmark datasets for punctuation restoration.
Generating Adversarial Examples with Task Oriented Multi-Objective Optimization
Apr 26, 2023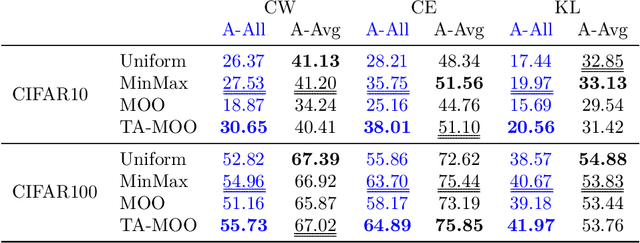
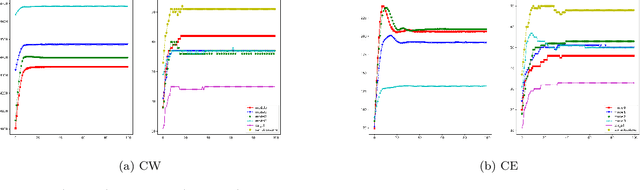
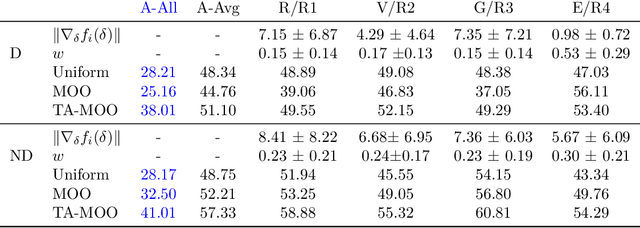

Deep learning models, even the-state-of-the-art ones, are highly vulnerable to adversarial examples. Adversarial training is one of the most efficient methods to improve the model's robustness. The key factor for the success of adversarial training is the capability to generate qualified and divergent adversarial examples which satisfy some objectives/goals (e.g., finding adversarial examples that maximize the model losses for simultaneously attacking multiple models). Therefore, multi-objective optimization (MOO) is a natural tool for adversarial example generation to achieve multiple objectives/goals simultaneously. However, we observe that a naive application of MOO tends to maximize all objectives/goals equally, without caring if an objective/goal has been achieved yet. This leads to useless effort to further improve the goal-achieved tasks, while putting less focus on the goal-unachieved tasks. In this paper, we propose \emph{Task Oriented MOO} to address this issue, in the context where we can explicitly define the goal achievement for a task. Our principle is to only maintain the goal-achieved tasks, while letting the optimizer spend more effort on improving the goal-unachieved tasks. We conduct comprehensive experiments for our Task Oriented MOO on various adversarial example generation schemes. The experimental results firmly demonstrate the merit of our proposed approach. Our code is available at \url{https://github.com/tuananhbui89/TAMOO}.
A Unified Wasserstein Distributional Robustness Framework for Adversarial Training
Feb 27, 2022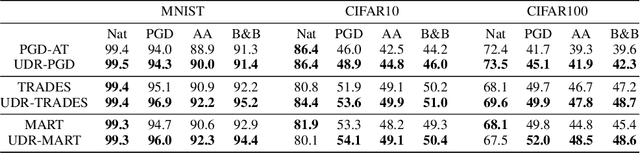
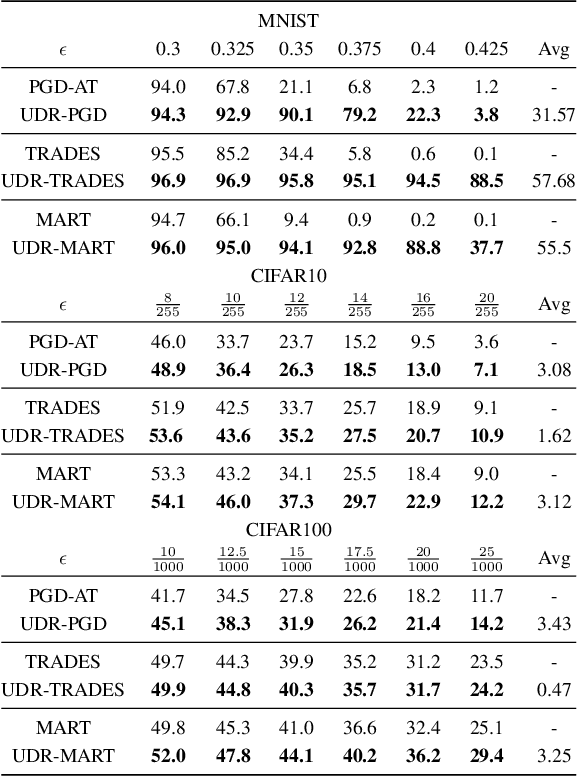
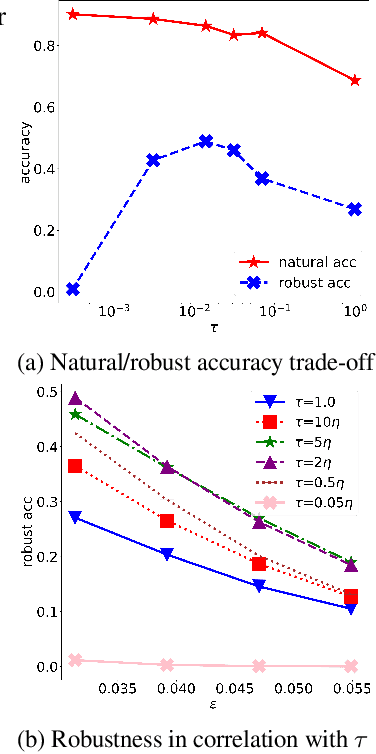
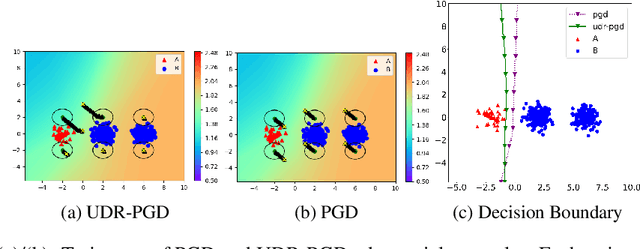
It is well-known that deep neural networks (DNNs) are susceptible to adversarial attacks, exposing a severe fragility of deep learning systems. As the result, adversarial training (AT) method, by incorporating adversarial examples during training, represents a natural and effective approach to strengthen the robustness of a DNN-based classifier. However, most AT-based methods, notably PGD-AT and TRADES, typically seek a pointwise adversary that generates the worst-case adversarial example by independently perturbing each data sample, as a way to "probe" the vulnerability of the classifier. Arguably, there are unexplored benefits in considering such adversarial effects from an entire distribution. To this end, this paper presents a unified framework that connects Wasserstein distributional robustness with current state-of-the-art AT methods. We introduce a new Wasserstein cost function and a new series of risk functions, with which we show that standard AT methods are special cases of their counterparts in our framework. This connection leads to an intuitive relaxation and generalization of existing AT methods and facilitates the development of a new family of distributional robustness AT-based algorithms. Extensive experiments show that our distributional robustness AT algorithms robustify further their standard AT counterparts in various settings.
Calibrating Concepts and Operations: Towards Symbolic Reasoning on Real Images
Oct 01, 2021


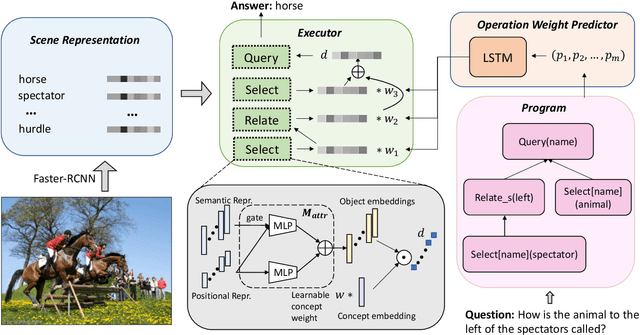
While neural symbolic methods demonstrate impressive performance in visual question answering on synthetic images, their performance suffers on real images. We identify that the long-tail distribution of visual concepts and unequal importance of reasoning steps in real data are the two key obstacles that limit the models' real-world potentials. To address these challenges, we propose a new paradigm, Calibrating Concepts and Operations (CCO), which enables neural symbolic models to capture underlying data characteristics and to reason with hierarchical importance. Specifically, we introduce an executor with learnable concept embedding magnitudes for handling distribution imbalance, and an operation calibrator for highlighting important operations and suppressing redundant ones. Our experiments show CCO substantially boosts the performance of neural symbolic methods on real images. By evaluating models on the real world dataset GQA, CCO helps the neural symbolic method NSCL outperforms its vanilla counterpart by 9.1% (from 47.0% to 56.1%); this result also largely reduces the performance gap between symbolic and non-symbolic methods. Additionally, we create a perturbed test set for better understanding and analyzing model performance on real images. Code is available at https://github.com/Lizw14/CaliCO.git .
Learning to Predict Visual Attributes in the Wild
Jun 17, 2021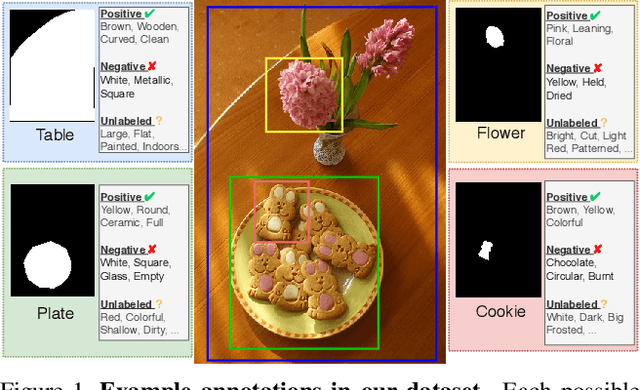

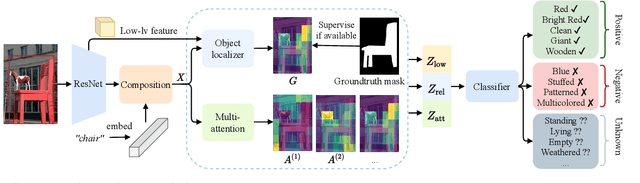
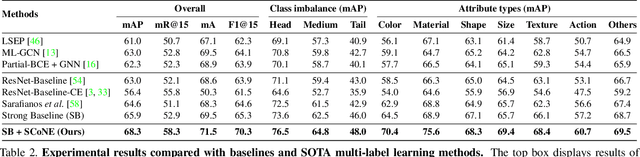
Visual attributes constitute a large portion of information contained in a scene. Objects can be described using a wide variety of attributes which portray their visual appearance (color, texture), geometry (shape, size, posture), and other intrinsic properties (state, action). Existing work is mostly limited to study of attribute prediction in specific domains. In this paper, we introduce a large-scale in-the-wild visual attribute prediction dataset consisting of over 927K attribute annotations for over 260K object instances. Formally, object attribute prediction is a multi-label classification problem where all attributes that apply to an object must be predicted. Our dataset poses significant challenges to existing methods due to large number of attributes, label sparsity, data imbalance, and object occlusion. To this end, we propose several techniques that systematically tackle these challenges, including a base model that utilizes both low- and high-level CNN features with multi-hop attention, reweighting and resampling techniques, a novel negative label expansion scheme, and a novel supervised attribute-aware contrastive learning algorithm. Using these techniques, we achieve near 3.7 mAP and 5.7 overall F1 points improvement over the current state of the art. Further details about the VAW dataset can be found at http://vawdataset.com/.
Explain by Evidence: An Explainable Memory-based Neural Network for Question Answering
Nov 05, 2020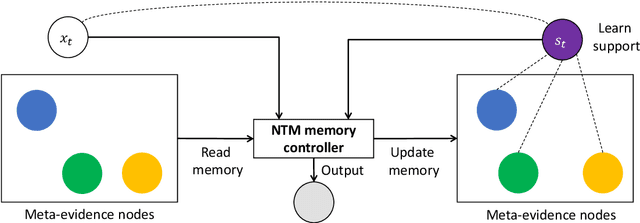
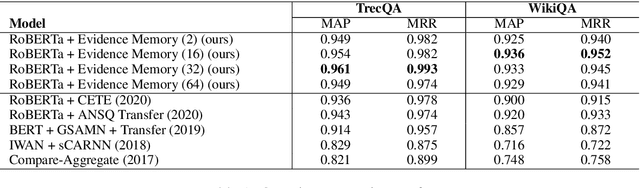

Interpretability and explainability of deep neural networks are challenging due to their scale, complexity, and the agreeable notions on which the explaining process rests. Previous work, in particular, has focused on representing internal components of neural networks through human-friendly visuals and concepts. On the other hand, in real life, when making a decision, human tends to rely on similar situations and/or associations in the past. Hence arguably, a promising approach to make the model transparent is to design it in a way such that the model explicitly connects the current sample with the seen ones, and bases its decision on these samples. Grounded on that principle, we propose in this paper an explainable, evidence-based memory network architecture, which learns to summarize the dataset and extract supporting evidences to make its decision. Our model achieves state-of-the-art performance on two popular question answering datasets (i.e. TrecQA and WikiQA). Via further analysis, we show that this model can reliably trace the errors it has made in the validation step to the training instances that might have caused these errors. We believe that this error-tracing capability provides significant benefit in improving dataset quality in many applications.