 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHear Both Sides: Efficient Multi-Agent Debate via Diversity-Aware Message Retention
Mar 21, 2026Multi-Agent Debate has emerged as a promising framework for improving the reasoning quality of large language models through iterative inter-agent communication. However, broadcasting all agent messages at every round introduces noise and redundancy that can degrade debate quality and waste computational resources. Current approaches rely on uncertainty estimation to filter low-confidence responses before broadcasting, but this approach is unreliable due to miscalibrated confidence scores and sensitivity to threshold selection. To address this, we propose Diversity-Aware Retention (DAR), a lightweight debate framework that, at each debate round, selects the subset of agent responses that maximally disagree with each other and with the majority vote before broadcasting. Through an explicit index-based retention mechanism, DAR preserves the original messages without modification, ensuring that retained disagreements remain authentic. Experiments on diverse reasoning and question answering benchmarks demonstrate that our selective message propagation consistently improves debate performance, particularly as the number of agents scales, where noise accumulation is most severe. Our results highlight that what agents hear is as important as what agents say in multi-agent reasoning systems.
Spectral Text Fusion: A Frequency-Aware Approach to Multimodal Time-Series Forecasting
Feb 03, 2026Multimodal time series forecasting is crucial in real-world applications, where decisions depend on both numerical data and contextual signals. The core challenge is to effectively combine temporal numerical patterns with the context embedded in other modalities, such as text. While most existing methods align textual features with time-series patterns one step at a time, they neglect the multiscale temporal influences of contextual information such as time-series cycles and dynamic shifts. This mismatch between local alignment and global textual context can be addressed by spectral decomposition, which separates time series into frequency components capturing both short-term changes and long-term trends. In this paper, we propose SpecTF, a simple yet effective framework that integrates the effect of textual data on time series in the frequency domain. Our method extracts textual embeddings, projects them into the frequency domain, and fuses them with the time series' spectral components using a lightweight cross-attention mechanism. This adaptively reweights frequency bands based on textual relevance before mapping the results back to the temporal domain for predictions. Experimental results demonstrate that SpecTF significantly outperforms state-of-the-art models across diverse multi-modal time series datasets while utilizing considerably fewer parameters. Code is available at https://github.com/hiepnh137/SpecTF.
Rethinking Deep Alignment Through The Lens Of Incomplete Learning
Nov 15, 2025Large language models exhibit systematic vulnerabilities to adversarial attacks despite extensive safety alignment. We provide a mechanistic analysis revealing that position-dependent gradient weakening during autoregressive training creates signal decay, leading to incomplete safety learning where safety training fails to transform model preferences in later response regions fully. We introduce base-favored tokens -- vocabulary elements where base models assign higher probability than aligned models -- as computational indicators of incomplete safety learning and develop a targeted completion method that addresses undertrained regions through adaptive penalties and hybrid teacher distillation. Experimental evaluation across Llama and Qwen model families demonstrates dramatic improvements in adversarial robustness, with 48--98% reductions in attack success rates while preserving general capabilities. These results establish both a mechanistic understanding and practical solutions for fundamental limitations in safety alignment methodologies.
Uncertainty-Guided Checkpoint Selection for Reinforcement Finetuning of Large Language Models
Nov 13, 2025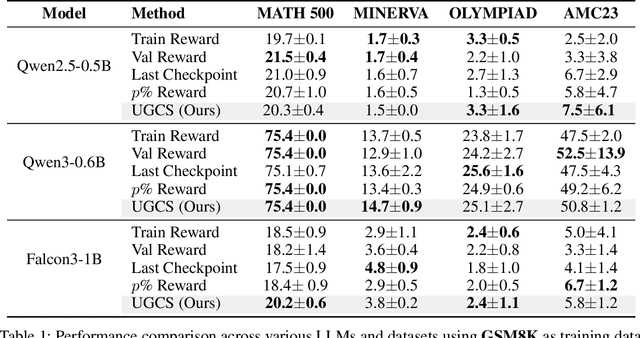
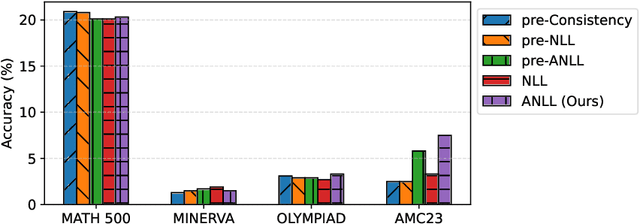
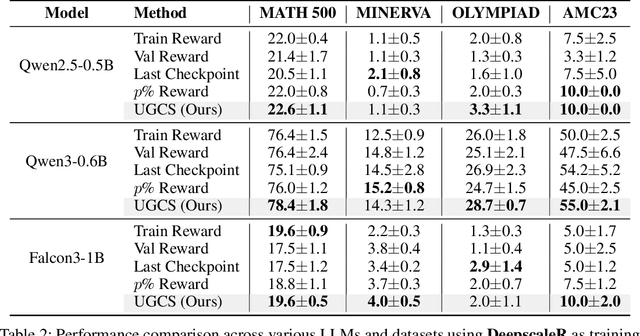
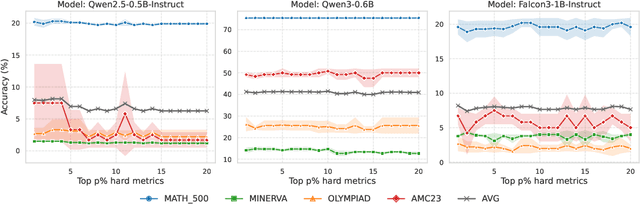
Reinforcement learning (RL) finetuning is crucial to aligning large language models (LLMs), but the process is notoriously unstable and exhibits high variance across model checkpoints. In practice, selecting the best checkpoint is challenging: evaluating checkpoints on the validation set during training is computationally expensive and requires a good validation set, while relying on the final checkpoint provides no guarantee of good performance. We introduce an uncertainty-guided approach for checkpoint selection (UGCS) that avoids these pitfalls. Our method identifies hard question-answer pairs using per-sample uncertainty and ranks checkpoints by how well they handle these challenging cases. By averaging the rewards of the top-uncertain samples over a short training window, our method produces a stable and discriminative signal without additional forward passes or significant computation overhead. Experiments across three datasets and three LLMs demonstrate that it consistently identifies checkpoints with stronger generalization, outperforming traditional strategies such as relying on training or validation performance. These results highlight that models solving their hardest tasks with low uncertainty are the most reliable overall.
Task Allocation for Autonomous Machines using Computational Intelligence and Deep Reinforcement Learning
Aug 28, 2025Enabling multiple autonomous machines to perform reliably requires the development of efficient cooperative control algorithms. This paper presents a survey of algorithms that have been developed for controlling and coordinating autonomous machines in complex environments. We especially focus on task allocation methods using computational intelligence (CI) and deep reinforcement learning (RL). The advantages and disadvantages of the surveyed methods are analysed thoroughly. We also propose and discuss in detail various future research directions that shed light on how to improve existing algorithms or create new methods to enhance the employability and performance of autonomous machines in real-world applications. The findings indicate that CI and deep RL methods provide viable approaches to addressing complex task allocation problems in dynamic and uncertain environments. The recent development of deep RL has greatly contributed to the literature on controlling and coordinating autonomous machines, and it has become a growing trend in this area. It is envisaged that this paper will provide researchers and engineers with a comprehensive overview of progress in machine learning research related to autonomous machines. It also highlights underexplored areas, identifies emerging methodologies, and suggests new avenues for exploration in future research within this domain.
A Survey on Vietnamese Document Analysis and Recognition: Challenges and Future Directions
Jun 05, 2025Vietnamese document analysis and recognition (DAR) is a crucial field with applications in digitization, information retrieval, and automation. Despite advancements in OCR and NLP, Vietnamese text recognition faces unique challenges due to its complex diacritics, tonal variations, and lack of large-scale annotated datasets. Traditional OCR methods often struggle with real-world document variations, while deep learning approaches have shown promise but remain limited by data scarcity and generalization issues. Recently, large language models (LLMs) and vision-language models have demonstrated remarkable improvements in text recognition and document understanding, offering a new direction for Vietnamese DAR. However, challenges such as domain adaptation, multimodal learning, and computational efficiency persist. This survey provide a comprehensive review of existing techniques in Vietnamese document recognition, highlights key limitations, and explores how LLMs can revolutionize the field. We discuss future research directions, including dataset development, model optimization, and the integration of multimodal approaches for improved document intelligence. By addressing these gaps, we aim to foster advancements in Vietnamese DAR and encourage community-driven solutions.
Localizing Before Answering: A Hallucination Evaluation Benchmark for Grounded Medical Multimodal LLMs
May 05, 2025Medical Large Multi-modal Models (LMMs) have demonstrated remarkable capabilities in medical data interpretation. However, these models frequently generate hallucinations contradicting source evidence, particularly due to inadequate localization reasoning. This work reveals a critical limitation in current medical LMMs: instead of analyzing relevant pathological regions, they often rely on linguistic patterns or attend to irrelevant image areas when responding to disease-related queries. To address this, we introduce HEAL-MedVQA (Hallucination Evaluation via Localization MedVQA), a comprehensive benchmark designed to evaluate LMMs' localization abilities and hallucination robustness. HEAL-MedVQA features (i) two innovative evaluation protocols to assess visual and textual shortcut learning, and (ii) a dataset of 67K VQA pairs, with doctor-annotated anatomical segmentation masks for pathological regions. To improve visual reasoning, we propose the Localize-before-Answer (LobA) framework, which trains LMMs to localize target regions of interest and self-prompt to emphasize segmented pathological areas, generating grounded and reliable answers. Experimental results demonstrate that our approach significantly outperforms state-of-the-art biomedical LMMs on the challenging HEAL-MedVQA benchmark, advancing robustness in medical VQA.
Reasoning Under 1 Billion: Memory-Augmented Reinforcement Learning for Large Language Models
Apr 03, 2025Recent advances in fine-tuning large language models (LLMs) with reinforcement learning (RL) have shown promising improvements in complex reasoning tasks, particularly when paired with chain-of-thought (CoT) prompting. However, these successes have been largely demonstrated on large-scale models with billions of parameters, where a strong pretraining foundation ensures effective initial exploration. In contrast, RL remains challenging for tiny LLMs with 1 billion parameters or fewer because they lack the necessary pretraining strength to explore effectively, often leading to suboptimal reasoning patterns. This work introduces a novel intrinsic motivation approach that leverages episodic memory to address this challenge, improving tiny LLMs in CoT reasoning tasks. Inspired by human memory-driven learning, our method leverages successful reasoning patterns stored in memory while allowing for controlled exploration to generate novel responses. Intrinsic rewards are computed efficiently using a kNN-based episodic memory, allowing the model to discover new reasoning strategies while quickly adapting to effective past solutions. Experiments on fine-tuning GSM8K and AI-MO datasets demonstrate that our approach significantly enhances smaller LLMs' sample efficiency and generalization capability, making RL-based reasoning improvements more accessible in low-resource settings.
MP-PINN: A Multi-Phase Physics-Informed Neural Network for Epidemic Forecasting
Nov 11, 2024Forecasting temporal processes such as virus spreading in epidemics often requires more than just observed time-series data, especially at the beginning of a wave when data is limited. Traditional methods employ mechanistic models like the SIR family, which make strong assumptions about the underlying spreading process, often represented as a small set of compact differential equations. Data-driven methods such as deep neural networks make no such assumptions and can capture the generative process in more detail, but fail in long-term forecasting due to data limitations. We propose a new hybrid method called MP-PINN (Multi-Phase Physics-Informed Neural Network) to overcome the limitations of these two major approaches. MP-PINN instils the spreading mechanism into a neural network, enabling the mechanism to update in phases over time, reflecting the dynamics of the epidemics due to policy interventions. Experiments on COVID-19 waves demonstrate that MP-PINN achieves superior performance over pure data-driven or model-driven approaches for both short-term and long-term forecasting.
Stable Hadamard Memory: Revitalizing Memory-Augmented Agents for Reinforcement Learning
Oct 14, 2024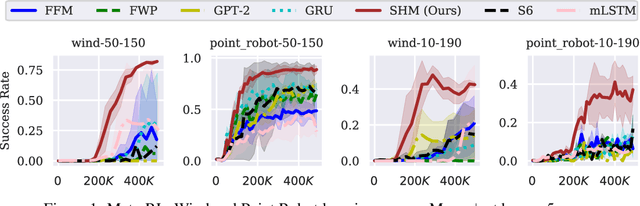
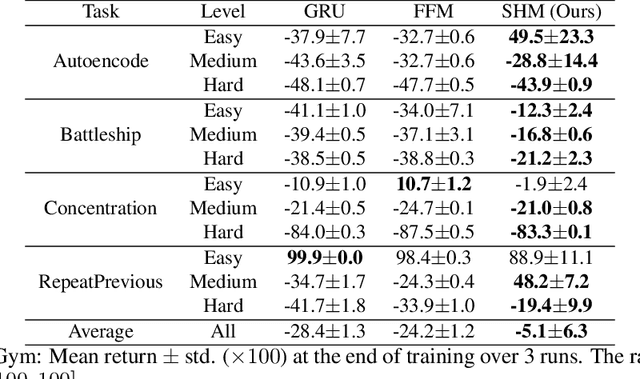
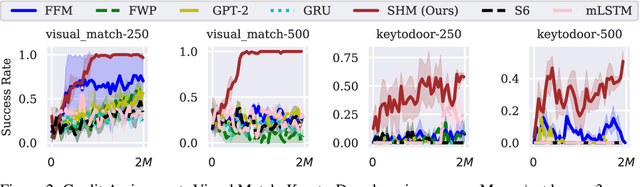

Effective decision-making in partially observable environments demands robust memory management. Despite their success in supervised learning, current deep-learning memory models struggle in reinforcement learning environments that are partially observable and long-term. They fail to efficiently capture relevant past information, adapt flexibly to changing observations, and maintain stable updates over long episodes. We theoretically analyze the limitations of existing memory models within a unified framework and introduce the Stable Hadamard Memory, a novel memory model for reinforcement learning agents. Our model dynamically adjusts memory by erasing no longer needed experiences and reinforcing crucial ones computationally efficiently. To this end, we leverage the Hadamard product for calibrating and updating memory, specifically designed to enhance memory capacity while mitigating numerical and learning challenges. Our approach significantly outperforms state-of-the-art memory-based methods on challenging partially observable benchmarks, such as meta-reinforcement learning, long-horizon credit assignment, and POPGym, demonstrating superior performance in handling long-term and evolving contexts.