 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGDA-YOLO11: Amodal Instance Segmentation for Occlusion-Robust Robotic Fruit Harvesting
Feb 27, 2026Occlusion remains a critical challenge in robotic fruit harvesting, as undetected or inaccurately localised fruits often results in substantial crop losses. To mitigate this issue, we propose a harvesting framework using a new amodal segmentation model, GDA-YOLO11, which incorporates architectural improvements and an updated asymmetric mask loss. The proposed model is trained on a modified version of a public citrus dataset and evaluated on both the base dataset and occlusion-sensitive subsets with varying occlusion levels. Within the framework, full fruit masks, including invisible regions, are inferred by GDA-YOLO11, and picking points are subsequently estimated using the Euclidean distance transform. These points are then projected into 3D coordinates for robotic harvesting execution. Experiments were conducted using real citrus fruits in a controlled environment simulating occlusion scenarios. Notably, to the best of our knowledge, this study provides the first practical demonstration of amodal instance segmentation in robotic fruit harvesting. GDA-YOLO11 achieves a precision of 0.844, recall of 0.846, mAP@50 of 0.914, and mAP@50:95 of 0.636, outperforming YOLO11n by 5.1%, 1.3%, and 1.0% in precision, mAP@50, and mAP@50:95, respectively. The framework attains harvesting success rates of 92.59%, 85.18%, 48.14%, and 22.22% at zero to high occlusion levels, improving success by 3.5% under medium and high occlusion. These findings demonstrate that GDA-YOLO11 enhances occlusion robust segmentation and streamlines perception-to-action integration, paving the way for more reliable autonomous systems in agriculture.
Seeing the Trees for the Forest: Rethinking Weakly-Supervised Medical Visual Grounding
May 21, 2025Visual grounding (VG) is the capability to identify the specific regions in an image associated with a particular text description. In medical imaging, VG enhances interpretability by highlighting relevant pathological features corresponding to textual descriptions, improving model transparency and trustworthiness for wider adoption of deep learning models in clinical practice. Current models struggle to associate textual descriptions with disease regions due to inefficient attention mechanisms and a lack of fine-grained token representations. In this paper, we empirically demonstrate two key observations. First, current VLMs assign high norms to background tokens, diverting the model's attention from regions of disease. Second, the global tokens used for cross-modal learning are not representative of local disease tokens. This hampers identifying correlations between the text and disease tokens. To address this, we introduce simple, yet effective Disease-Aware Prompting (DAP) process, which uses the explainability map of a VLM to identify the appropriate image features. This simple strategy amplifies disease-relevant regions while suppressing background interference. Without any additional pixel-level annotations, DAP improves visual grounding accuracy by 20.74% compared to state-of-the-art methods across three major chest X-ray datasets.
Localizing Before Answering: A Hallucination Evaluation Benchmark for Grounded Medical Multimodal LLMs
May 05, 2025Medical Large Multi-modal Models (LMMs) have demonstrated remarkable capabilities in medical data interpretation. However, these models frequently generate hallucinations contradicting source evidence, particularly due to inadequate localization reasoning. This work reveals a critical limitation in current medical LMMs: instead of analyzing relevant pathological regions, they often rely on linguistic patterns or attend to irrelevant image areas when responding to disease-related queries. To address this, we introduce HEAL-MedVQA (Hallucination Evaluation via Localization MedVQA), a comprehensive benchmark designed to evaluate LMMs' localization abilities and hallucination robustness. HEAL-MedVQA features (i) two innovative evaluation protocols to assess visual and textual shortcut learning, and (ii) a dataset of 67K VQA pairs, with doctor-annotated anatomical segmentation masks for pathological regions. To improve visual reasoning, we propose the Localize-before-Answer (LobA) framework, which trains LMMs to localize target regions of interest and self-prompt to emphasize segmented pathological areas, generating grounded and reliable answers. Experimental results demonstrate that our approach significantly outperforms state-of-the-art biomedical LMMs on the challenging HEAL-MedVQA benchmark, advancing robustness in medical VQA.
Foundational Models for 3D Point Clouds: A Survey and Outlook
Jan 30, 2025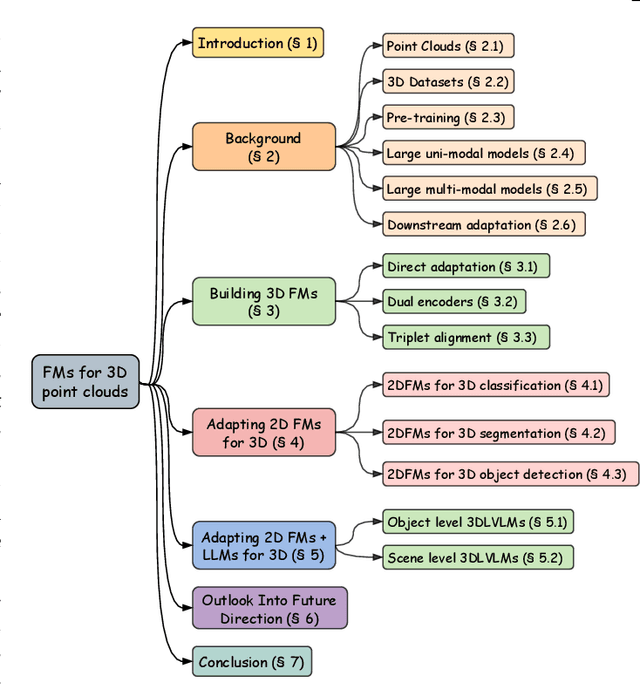
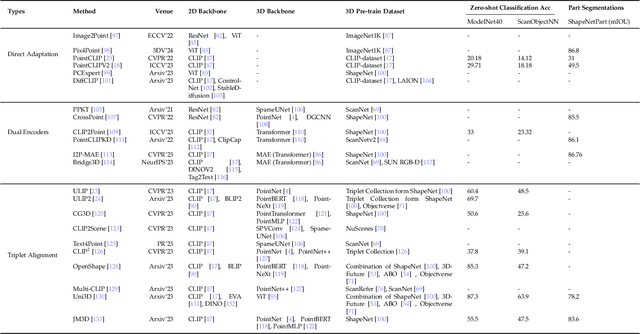
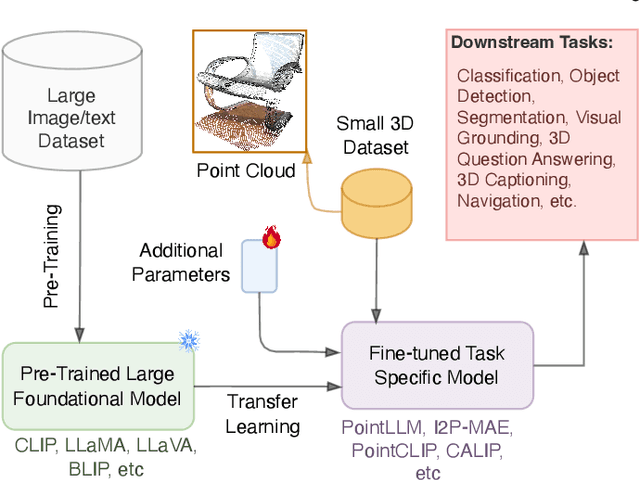

The 3D point cloud representation plays a crucial role in preserving the geometric fidelity of the physical world, enabling more accurate complex 3D environments. While humans naturally comprehend the intricate relationships between objects and variations through a multisensory system, artificial intelligence (AI) systems have yet to fully replicate this capacity. To bridge this gap, it becomes essential to incorporate multiple modalities. Models that can seamlessly integrate and reason across these modalities are known as foundation models (FMs). The development of FMs for 2D modalities, such as images and text, has seen significant progress, driven by the abundant availability of large-scale datasets. However, the 3D domain has lagged due to the scarcity of labelled data and high computational overheads. In response, recent research has begun to explore the potential of applying FMs to 3D tasks, overcoming these challenges by leveraging existing 2D knowledge. Additionally, language, with its capacity for abstract reasoning and description of the environment, offers a promising avenue for enhancing 3D understanding through large pre-trained language models (LLMs). Despite the rapid development and adoption of FMs for 3D vision tasks in recent years, there remains a gap in comprehensive and in-depth literature reviews. This article aims to address this gap by presenting a comprehensive overview of the state-of-the-art methods that utilize FMs for 3D visual understanding. We start by reviewing various strategies employed in the building of various 3D FMs. Then we categorize and summarize use of different FMs for tasks such as perception tasks. Finally, the article offers insights into future directions for research and development in this field. To help reader, we have curated list of relevant papers on the topic: https://github.com/vgthengane/Awesome-FMs-in-3D.
Structural Attention: Rethinking Transformer for Unpaired Medical Image Synthesis
Jun 27, 2024



Unpaired medical image synthesis aims to provide complementary information for an accurate clinical diagnostics, and address challenges in obtaining aligned multi-modal medical scans. Transformer-based models excel in imaging translation tasks thanks to their ability to capture long-range dependencies. Although effective in supervised training settings, their performance falters in unpaired image synthesis, particularly in synthesizing structural details. This paper empirically demonstrates that, lacking strong inductive biases, Transformer can converge to non-optimal solutions in the absence of paired data. To address this, we introduce UNet Structured Transformer (UNest), a novel architecture incorporating structural inductive biases for unpaired medical image synthesis. We leverage the foundational Segment-Anything Model to precisely extract the foreground structure and perform structural attention within the main anatomy. This guides the model to learn key anatomical regions, thus improving structural synthesis under the lack of supervision in unpaired training. Evaluated on two public datasets, spanning three modalities, i.e., MR, CT, and PET, UNest improves recent methods by up to 19.30% across six medical image synthesis tasks. Our code is released at https://github.com/HieuPhan33/MICCAI2024-UNest.
CROVIA: Seeing Drone Scenes from Car Perspective via Cross-View Adaptation
Apr 14, 2023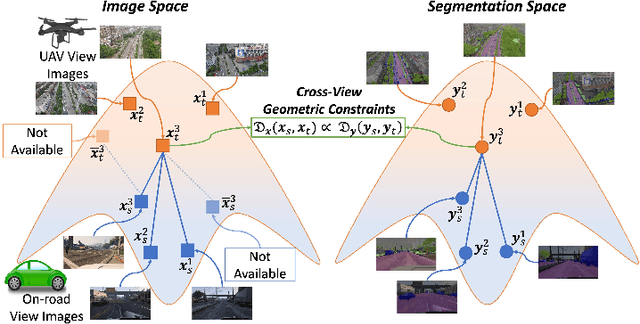

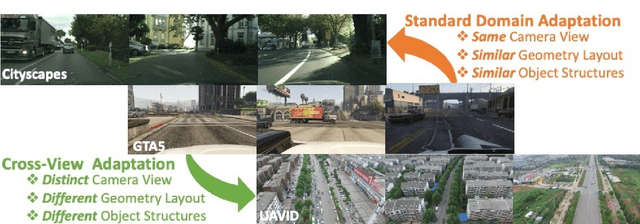

Understanding semantic scene segmentation of urban scenes captured from the Unmanned Aerial Vehicles (UAV) perspective plays a vital role in building a perception model for UAV. With the limitations of large-scale densely labeled data, semantic scene segmentation for UAV views requires a broad understanding of an object from both its top and side views. Adapting from well-annotated autonomous driving data to unlabeled UAV data is challenging due to the cross-view differences between the two data types. Our work proposes a novel Cross-View Adaptation (CROVIA) approach to effectively adapt the knowledge learned from on-road vehicle views to UAV views. First, a novel geometry-based constraint to cross-view adaptation is introduced based on the geometry correlation between views. Second, cross-view correlations from image space are effectively transferred to segmentation space without any requirement of paired on-road and UAV view data via a new Geometry-Constraint Cross-View (GeiCo) loss. Third, the multi-modal bijective networks are introduced to enforce the global structural modeling across views. Experimental results on new cross-view adaptation benchmarks introduced in this work, i.e., SYNTHIA to UAVID and GTA5 to UAVID, show the State-of-the-Art (SOTA) performance of our approach over prior adaptation methods
Multi-Camera Multi-Object Tracking on the Move via Single-Stage Global Association Approach
Nov 17, 2022



The development of autonomous vehicles generates a tremendous demand for a low-cost solution with a complete set of camera sensors capturing the environment around the car. It is essential for object detection and tracking to address these new challenges in multi-camera settings. In order to address these challenges, this work introduces novel Single-Stage Global Association Tracking approaches to associate one or more detection from multi-cameras with tracked objects. These approaches aim to solve fragment-tracking issues caused by inconsistent 3D object detection. Moreover, our models also improve the detection accuracy of the standard vision-based 3D object detectors in the nuScenes detection challenge. The experimental results on the nuScenes dataset demonstrate the benefits of the proposed method by outperforming prior vision-based tracking methods in multi-camera settings.
DirecFormer: A Directed Attention in Transformer Approach to Robust Action Recognition
Mar 19, 2022
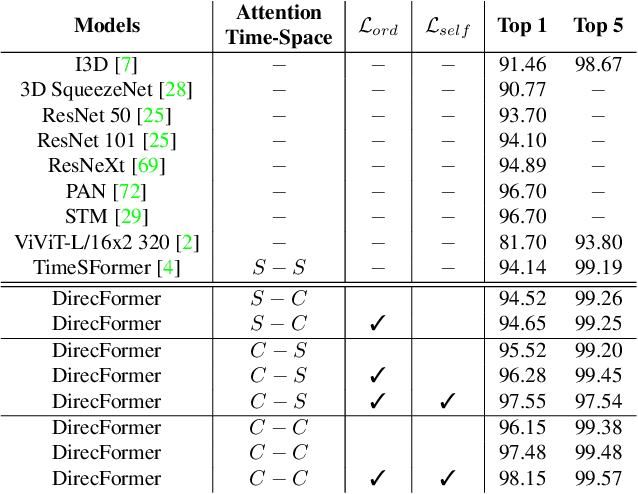

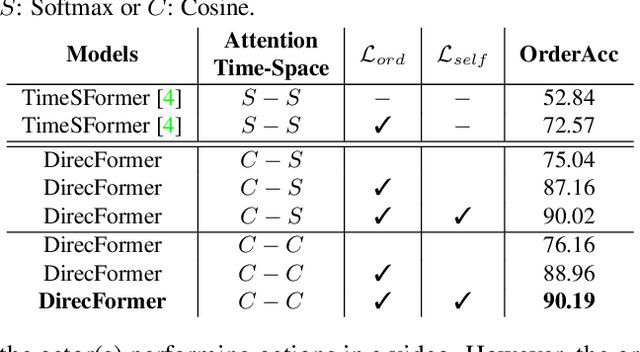
Human action recognition has recently become one of the popular research topics in the computer vision community. Various 3D-CNN based methods have been presented to tackle both the spatial and temporal dimensions in the task of video action recognition with competitive results. However, these methods have suffered some fundamental limitations such as lack of robustness and generalization, e.g., how does the temporal ordering of video frames affect the recognition results? This work presents a novel end-to-end Transformer-based Directed Attention (DirecFormer) framework for robust action recognition. The method takes a simple but novel perspective of Transformer-based approach to understand the right order of sequence actions. Therefore, the contributions of this work are three-fold. Firstly, we introduce the problem of ordered temporal learning issues to the action recognition problem. Secondly, a new Directed Attention mechanism is introduced to understand and provide attentions to human actions in the right order. Thirdly, we introduce the conditional dependency in action sequence modeling that includes orders and classes. The proposed approach consistently achieves the state-of-the-art (SOTA) results compared with the recent action recognition methods, on three standard large-scale benchmarks, i.e. Jester, Kinetics-400 and Something-Something-V2.
BiMaL: Bijective Maximum Likelihood Approach to Domain Adaptation in Semantic Scene Segmentation
Aug 06, 2021
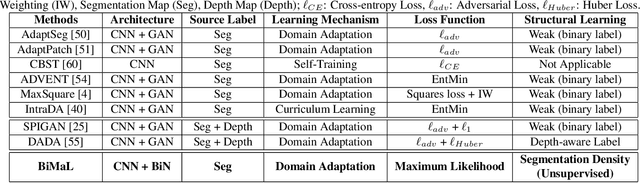
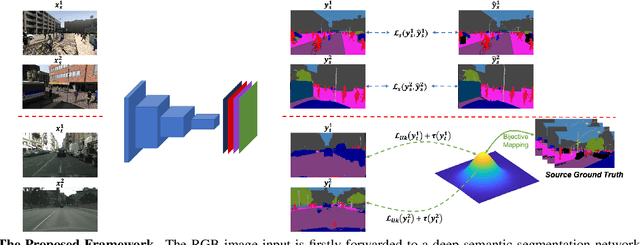
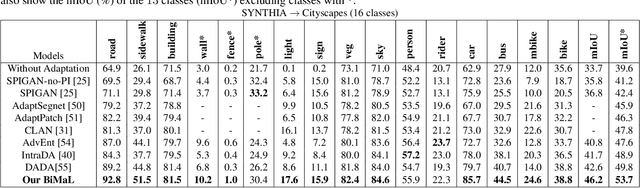
Semantic segmentation aims to predict pixel-level labels. It has become a popular task in various computer vision applications. While fully supervised segmentation methods have achieved high accuracy on large-scale vision datasets, they are unable to generalize on a new test environment or a new domain well. In this work, we first introduce a new Un-aligned Domain Score to measure the efficiency of a learned model on a new target domain in unsupervised manner. Then, we present the new Bijective Maximum Likelihood(BiMaL) loss that is a generalized form of the Adversarial Entropy Minimization without any assumption about pixel independence. We have evaluated the proposed BiMaL on two domains. The proposed BiMaL approach consistently outperforms the SOTA methods on empirical experiments on "SYNTHIA to Cityscapes", "GTA5 to Cityscapes", and "SYNTHIA to Vistas".