 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$φ$-DPO: Fairness Direct Preference Optimization Approach to Continual Learning in Large Multimodal Models
Feb 26, 2026Fairness in Continual Learning for Large Multimodal Models (LMMs) is an emerging yet underexplored challenge, particularly in the presence of imbalanced data distributions that can lead to biased model updates and suboptimal performance across tasks. While recent continual learning studies have made progress in addressing catastrophic forgetting, the problem of fairness caused the imbalanced data remains largely underexplored. This paper presents a novel Fairness Direct Preference Optimization (FaiDPO or $φ$-DPO) framework for continual learning in LMMs. In particular, we first propose a new continual learning paradigm based on Direct Preference Optimization (DPO) to mitigate catastrophic forgetting by aligning learning with pairwise preference signals. Then, we identify the limitations of conventional DPO in imbalanced data and present a new $φ$-DPO loss that explicitly addresses distributional biases. We provide a comprehensive theoretical analysis demonstrating that our approach addresses both forgetting and data imbalance. Additionally, to enable $φ$-DPO-based continual learning, we construct pairwise preference annotations for existing benchmarks in the context of continual learning. Extensive experiments and ablation studies show the proposed $φ$-DPO achieves State-of-the-Art performance across multiple benchmarks, outperforming prior continual learning methods of LMMs.
BRAIN: Bias-Mitigation Continual Learning Approach to Vision-Brain Understanding
Aug 25, 2025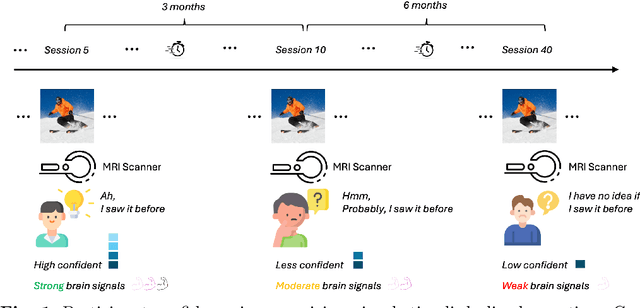
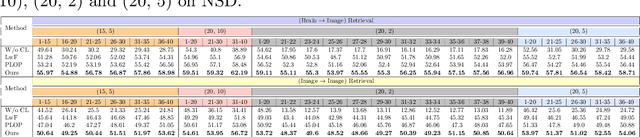
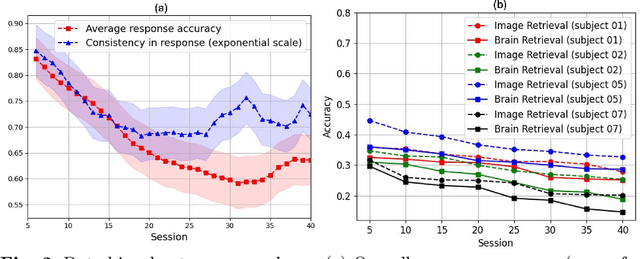
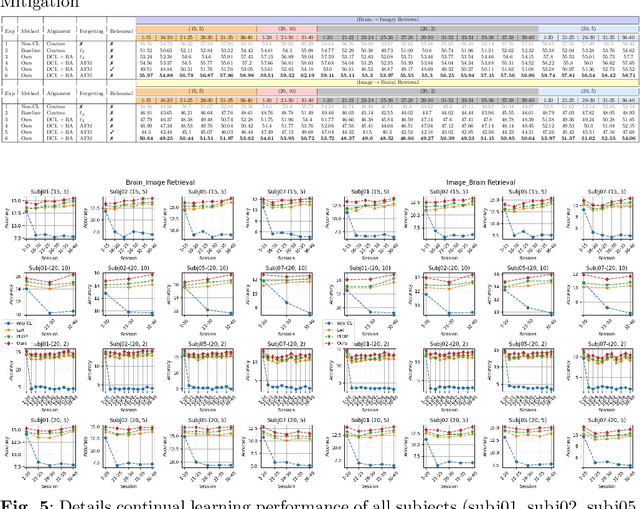
Memory decay makes it harder for the human brain to recognize visual objects and retain details. Consequently, recorded brain signals become weaker, uncertain, and contain poor visual context over time. This paper presents one of the first vision-learning approaches to address this problem. First, we statistically and experimentally demonstrate the existence of inconsistency in brain signals and its impact on the Vision-Brain Understanding (VBU) model. Our findings show that brain signal representations shift over recording sessions, leading to compounding bias, which poses challenges for model learning and degrades performance. Then, we propose a new Bias-Mitigation Continual Learning (BRAIN) approach to address these limitations. In this approach, the model is trained in a continual learning setup and mitigates the growing bias from each learning step. A new loss function named De-bias Contrastive Learning is also introduced to address the bias problem. In addition, to prevent catastrophic forgetting, where the model loses knowledge from previous sessions, the new Angular-based Forgetting Mitigation approach is introduced to preserve learned knowledge in the model. Finally, the empirical experiments demonstrate that our approach achieves State-of-the-Art (SOTA) performance across various benchmarks, surpassing prior and non-continual learning methods.
Directed-Tokens: A Robust Multi-Modality Alignment Approach to Large Language-Vision Models
Aug 19, 2025Large multimodal models (LMMs) have gained impressive performance due to their outstanding capability in various understanding tasks. However, these models still suffer from some fundamental limitations related to robustness and generalization due to the alignment and correlation between visual and textual features. In this paper, we introduce a simple but efficient learning mechanism for improving the robust alignment between visual and textual modalities by solving shuffling problems. In particular, the proposed approach can improve reasoning capability, visual understanding, and cross-modality alignment by introducing two new tasks: reconstructing the image order and the text order into the LMM's pre-training and fine-tuning phases. In addition, we propose a new directed-token approach to capture visual and textual knowledge, enabling the capability to reconstruct the correct order of visual inputs. Then, we introduce a new Image-to-Response Guided loss to further improve the visual understanding of the LMM in its responses. The proposed approach consistently achieves state-of-the-art (SoTA) performance compared with prior LMMs on academic task-oriented and instruction-following LMM benchmarks.
MANGO: Multimodal Attention-based Normalizing Flow Approach to Fusion Learning
Aug 13, 2025Multimodal learning has gained much success in recent years. However, current multimodal fusion methods adopt the attention mechanism of Transformers to implicitly learn the underlying correlation of multimodal features. As a result, the multimodal model cannot capture the essential features of each modality, making it difficult to comprehend complex structures and correlations of multimodal inputs. This paper introduces a novel Multimodal Attention-based Normalizing Flow (MANGO) approach\footnote{The source code of this work will be publicly available.} to developing explicit, interpretable, and tractable multimodal fusion learning. In particular, we propose a new Invertible Cross-Attention (ICA) layer to develop the Normalizing Flow-based Model for multimodal data. To efficiently capture the complex, underlying correlations in multimodal data in our proposed invertible cross-attention layer, we propose three new cross-attention mechanisms: Modality-to-Modality Cross-Attention (MMCA), Inter-Modality Cross-Attention (IMCA), and Learnable Inter-Modality Cross-Attention (LICA). Finally, we introduce a new Multimodal Attention-based Normalizing Flow to enable the scalability of our proposed method to high-dimensional multimodal data. Our experimental results on three different multimodal learning tasks, i.e., semantic segmentation, image-to-image translation, and movie genre classification, have illustrated the state-of-the-art (SoTA) performance of the proposed approach.
BIMA: Bijective Maximum Likelihood Learning Approach to Hallucination Prediction and Mitigation in Large Vision-Language Models
May 30, 2025



Large vision-language models have become widely adopted to advance in various domains. However, developing a trustworthy system with minimal interpretable characteristics of large-scale models presents a significant challenge. One of the most prevalent terms associated with the fallacy functions caused by these systems is hallucination, where the language model generates a response that does not correspond to the visual content. To mitigate this problem, several approaches have been developed, and one prominent direction is to ameliorate the decoding process. In this paper, we propose a new Bijective Maximum Likelihood Learning (BIMA) approach to hallucination mitigation using normalizing flow theories. The proposed BIMA method can efficiently mitigate the hallucination problem in prevailing vision-language models, resulting in significant improvements. Notably, BIMA achieves the average F1 score of 85.06% on POPE benchmark and remarkably reduce CHAIRS and CHAIRI by 7.6% and 2.6%, respectively. To the best of our knowledge, this is one of the first studies that contemplates the bijection means to reduce hallucination induced by large vision-language models.
Towards Robust and Fair Vision Learning in Open-World Environments
Dec 12, 2024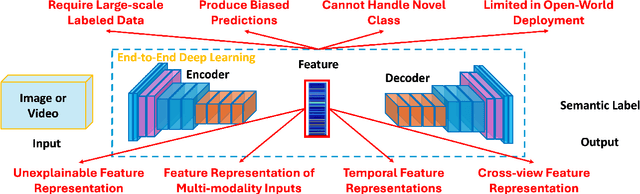


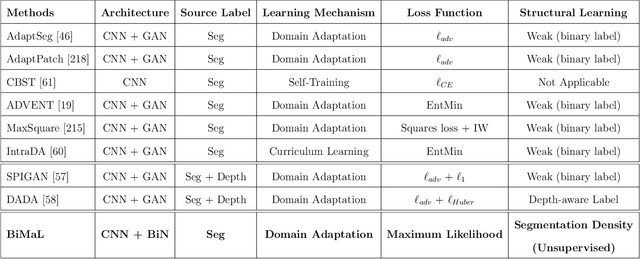
The dissertation presents four key contributions toward fairness and robustness in vision learning. First, to address the problem of large-scale data requirements, the dissertation presents a novel Fairness Domain Adaptation approach derived from two major novel research findings of Bijective Maximum Likelihood and Fairness Adaptation Learning. Second, to enable the capability of open-world modeling of vision learning, this dissertation presents a novel Open-world Fairness Continual Learning Framework. The success of this research direction is the result of two research lines, i.e., Fairness Continual Learning and Open-world Continual Learning. Third, since visual data are often captured from multiple camera views, robust vision learning methods should be capable of modeling invariant features across views. To achieve this desired goal, the research in this thesis will present a novel Geometry-based Cross-view Adaptation framework to learn robust feature representations across views. Finally, with the recent increase in large-scale videos and multimodal data, understanding the feature representations and improving the robustness of large-scale visual foundation models is critical. Therefore, this thesis will present novel Transformer-based approaches to improve the robust feature representations against multimodal and temporal data. Then, a novel Domain Generalization Approach will be presented to improve the robustness of visual foundation models. The research's theoretical analysis and experimental results have shown the effectiveness of the proposed approaches, demonstrating their superior performance compared to prior studies. The contributions in this dissertation have advanced the fairness and robustness of machine vision learning.
EAGLE: Efficient Adaptive Geometry-based Learning in Cross-view Understanding
Jun 03, 2024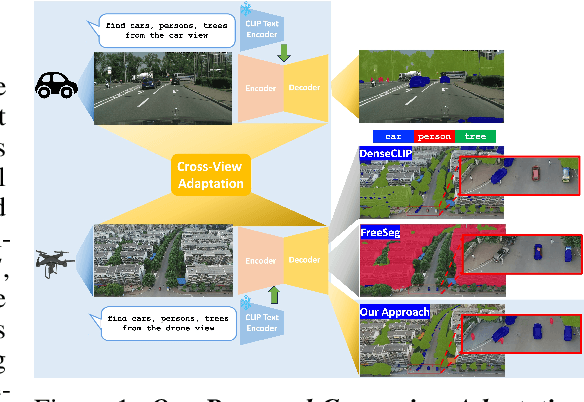
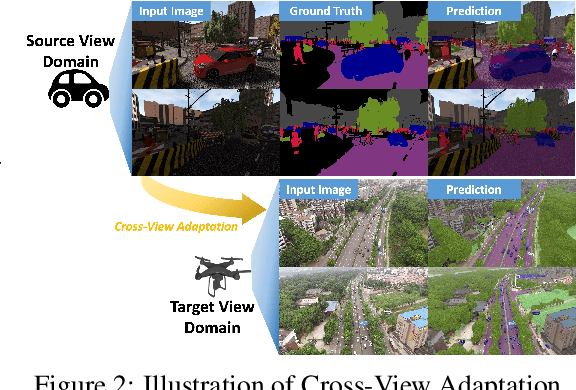
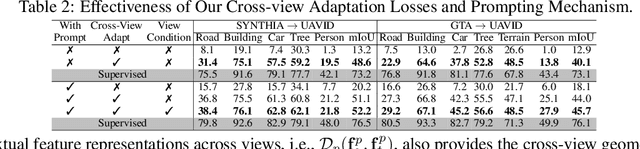
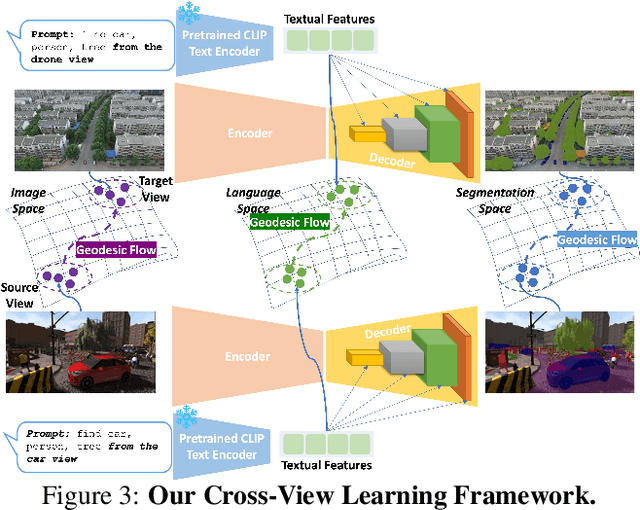
Unsupervised Domain Adaptation has been an efficient approach to transferring the semantic segmentation model across data distributions. Meanwhile, the recent Open-vocabulary Semantic Scene understanding based on large-scale vision language models is effective in open-set settings because it can learn diverse concepts and categories. However, these prior methods fail to generalize across different camera views due to the lack of cross-view geometric modeling. At present, there are limited studies analyzing cross-view learning. To address this problem, we introduce a novel Unsupervised Cross-view Adaptation Learning approach to modeling the geometric structural change across views in Semantic Scene Understanding. First, we introduce a novel Cross-view Geometric Constraint on Unpaired Data to model structural changes in images and segmentation masks across cameras. Second, we present a new Geodesic Flow-based Correlation Metric to efficiently measure the geometric structural changes across camera views. Third, we introduce a novel view-condition prompting mechanism to enhance the view-information modeling of the open-vocabulary segmentation network in cross-view adaptation learning. The experiments on different cross-view adaptation benchmarks have shown the effectiveness of our approach in cross-view modeling, demonstrating that we achieve State-of-the-Art (SOTA) performance compared to prior unsupervised domain adaptation and open-vocabulary semantic segmentation methods.
ED-SAM: An Efficient Diffusion Sampling Approach to Domain Generalization in Vision-Language Foundation Models
Jun 03, 2024The Vision-Language Foundation Model has recently shown outstanding performance in various perception learning tasks. The outstanding performance of the vision-language model mainly relies on large-scale pre-training datasets and different data augmentation techniques. However, the domain generalization problem of the vision-language foundation model needs to be addressed. This problem has limited the generalizability of the vision-language foundation model to unknown data distributions. In this paper, we introduce a new simple but efficient Diffusion Sampling approach to Domain Generalization (ED-SAM) to improve the generalizability of the vision-language foundation model. Our theoretical analysis in this work reveals the critical role and relation of the diffusion model to domain generalization in the vision-language foundation model. Then, based on the insightful analysis, we introduce a new simple yet effective Transport Transformation to diffusion sampling method. It can effectively generate adversarial samples to improve the generalizability of the foundation model against unknown data distributions. The experimental results on different scales of vision-language pre-training datasets, including CC3M, CC12M, and LAION400M, have consistently shown State-of-the-Art performance and scalability of the proposed ED-SAM approach compared to the other recent methods.
Multi-view Action Recognition via Directed Gromov-Wasserstein Discrepancy
May 02, 2024



Action recognition has become one of the popular research topics in computer vision. There are various methods based on Convolutional Networks and self-attention mechanisms as Transformers to solve both spatial and temporal dimensions problems of action recognition tasks that achieve competitive performances. However, these methods lack a guarantee of the correctness of the action subject that the models give attention to, i.e., how to ensure an action recognition model focuses on the proper action subject to make a reasonable action prediction. In this paper, we propose a multi-view attention consistency method that computes the similarity between two attentions from two different views of the action videos using Directed Gromov-Wasserstein Discrepancy. Furthermore, our approach applies the idea of Neural Radiance Field to implicitly render the features from novel views when training on single-view datasets. Therefore, the contributions in this work are three-fold. Firstly, we introduce the multi-view attention consistency to solve the problem of reasonable prediction in action recognition. Secondly, we define a new metric for multi-view consistent attention using Directed Gromov-Wasserstein Discrepancy. Thirdly, we built an action recognition model based on Video Transformers and Neural Radiance Fields. Compared to the recent action recognition methods, the proposed approach achieves state-of-the-art results on three large-scale datasets, i.e., Jester, Something-Something V2, and Kinetics-400.
FALCON: Fairness Learning via Contrastive Attention Approach to Continual Semantic Scene Understanding in Open World
Nov 27, 2023Continual Learning in semantic scene segmentation aims to continually learn new unseen classes in dynamic environments while maintaining previously learned knowledge. Prior studies focused on modeling the catastrophic forgetting and background shift challenges in continual learning. However, fairness, another major challenge that causes unfair predictions leading to low performance among major and minor classes, still needs to be well addressed. In addition, prior methods have yet to model the unknown classes well, thus resulting in producing non-discriminative features among unknown classes. This paper presents a novel Fairness Learning via Contrastive Attention Approach to continual learning in semantic scene understanding. In particular, we first introduce a new Fairness Contrastive Clustering loss to address the problems of catastrophic forgetting and fairness. Then, we propose an attention-based visual grammar approach to effectively model the background shift problem and unknown classes, producing better feature representations for different unknown classes. Through our experiments, our proposed approach achieves State-of-the-Art (SOTA) performance on different continual learning settings of three standard benchmarks, i.e., ADE20K, Cityscapes, and Pascal VOC. It promotes the fairness of the continual semantic segmentation model.