 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenQlaw: An Agentic AI Assistant for Analysis of 2D Quantum Materials
Mar 17, 2026The transition from optical identification of 2D quantum materials to practical device fabrication requires dynamic reasoning beyond the detection accuracy. While recent domain-specific Multimodal Large Language Models (MLLMs) successfully ground visual features using physics-informed reasoning, their outputs are optimized for step-by-step cognitive transparency. This yields verbose candidate enumerations followed by dense reasoning that, while accurate, may induce cognitive overload and lack immediate utility for real-world interaction with researchers. To address this challenge, we introduce OpenQlaw, an agentic orchestration system for analyzing 2D materials. The architecture is built upon NanoBot, a lightweight agentic framework inspired by OpenClaw, and QuPAINT, one of the first Physics-Aware Instruction Multi-modal platforms for Quantum Material Discovery. This allows accessibility to the lab floor via a variety of messaging channels. OpenQlaw allows the core Large Language Model (LLM) agent to orchestrate a domain-expert MLLM,with QuPAINT, as a specialized node, successfully decoupling visual identification from reasoning and deterministic image rendering. By parsing spatial data from the expert, the agent can dynamically process user queries, such as performing scale-aware physical computation or generating isolated visual annotations, and answer in a naturalistic manner. Crucially, the system features a persistent memory that enables the agent to save physical scale ratios (e.g., 1 pixel = 0.25 μm) for area computations and store sample preparation methods for efficacy comparison. The application of an agentic architecture, together with the extension that uses the core agent as an orchestrator for domain-specific experts, transforms isolated inferences into a context-aware assistant capable of accelerating high-throughput device fabrication.
NICO-RAG: Multimodal Hypergraph Retrieval-Augmented Generation for Understanding the Nicotine Public Health Crisis
Mar 02, 2026The nicotine addiction public health crisis continues to be pervasive. In this century alone, the tobacco industry has released and marketed new products in an aggressive effort to lure new and young customers for life. Such innovations and product development, namely flavored nicotine or tobacco such as nicotine pouches, have undone years of anti-tobacco campaign work. Past work is limited both in scope and in its ability to connect large-scale data points. Thus, we introduce the Nicotine Innovation Counter-Offensive (NICO) Dataset to provide public health researchers with over 200,000 multimodal samples, including images and text descriptions, on 55 tobacco and nicotine product brands. In addition, to provide public health researchers with factual connections across a large-scale dataset, we propose NICO-RAG, a retrieval-augmented generation (RAG) framework that can retrieve image features without incurring the high-cost of language models, as well as the added cost of processing image tokens with large-scale datasets such as NICO. At construction time, NICO-RAG organizes image- and text-extracted entities and relations into hypergraphs to produce as factual responses as possible. This joint multimodal knowledge representation enables NICO-RAG to retrieve images for query answering not only by visual similarity but also by the semantic similarity of image descriptions. Experimentals show that without needing to process additional tokens from images for over 100 questions, NICO-RAG performs comparably to the state-of-the-art RAG method adapted for images.
$φ$-DPO: Fairness Direct Preference Optimization Approach to Continual Learning in Large Multimodal Models
Feb 26, 2026Fairness in Continual Learning for Large Multimodal Models (LMMs) is an emerging yet underexplored challenge, particularly in the presence of imbalanced data distributions that can lead to biased model updates and suboptimal performance across tasks. While recent continual learning studies have made progress in addressing catastrophic forgetting, the problem of fairness caused the imbalanced data remains largely underexplored. This paper presents a novel Fairness Direct Preference Optimization (FaiDPO or $φ$-DPO) framework for continual learning in LMMs. In particular, we first propose a new continual learning paradigm based on Direct Preference Optimization (DPO) to mitigate catastrophic forgetting by aligning learning with pairwise preference signals. Then, we identify the limitations of conventional DPO in imbalanced data and present a new $φ$-DPO loss that explicitly addresses distributional biases. We provide a comprehensive theoretical analysis demonstrating that our approach addresses both forgetting and data imbalance. Additionally, to enable $φ$-DPO-based continual learning, we construct pairwise preference annotations for existing benchmarks in the context of continual learning. Extensive experiments and ablation studies show the proposed $φ$-DPO achieves State-of-the-Art performance across multiple benchmarks, outperforming prior continual learning methods of LMMs.
QuPAINT: Physics-Aware Instruction Tuning Approach to Quantum Material Discovery
Feb 19, 2026Characterizing two-dimensional quantum materials from optical microscopy images is challenging due to the subtle layer-dependent contrast, limited labeled data, and significant variation across laboratories and imaging setups. Existing vision models struggle in this domain since they lack physical priors and cannot generalize to new materials or hardware conditions. This work presents a new physics-aware multimodal framework that addresses these limitations from both the data and model perspectives. We first present Synthia, a physics-based synthetic data generator that simulates realistic optical responses of quantum material flakes under thin-film interference. Synthia produces diverse and high-quality samples, helping reduce the dependence on expert manual annotation. We introduce QMat-Instruct, the first large-scale instruction dataset for quantum materials, comprising multimodal, physics-informed question-answer pairs designed to teach Multimodal Large Language Models (MLLMs) to understand the appearance and thickness of flakes. Then, we propose Physics-Aware Instruction Tuning (QuPAINT), a multimodal architecture that incorporates a Physics-Informed Attention module to fuse visual embeddings with optical priors, enabling more robust and discriminative flake representations. Finally, we establish QF-Bench, a comprehensive benchmark spanning multiple materials, substrates, and imaging settings, offering standardized protocols for fair and reproducible evaluation.
BRAIN: Bias-Mitigation Continual Learning Approach to Vision-Brain Understanding
Aug 25, 2025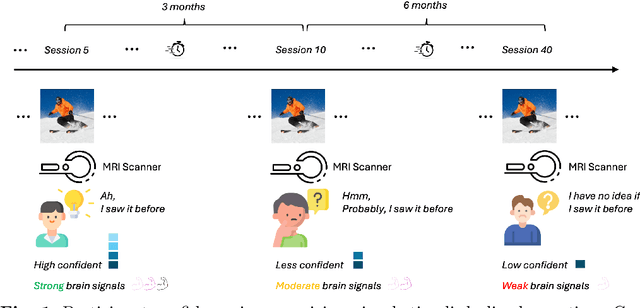
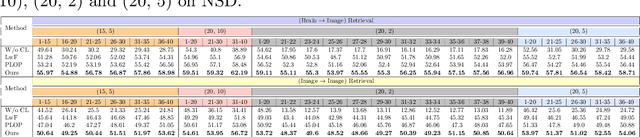
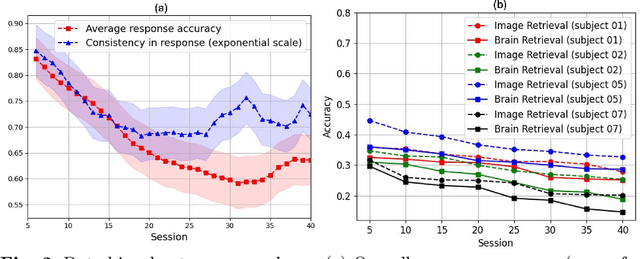
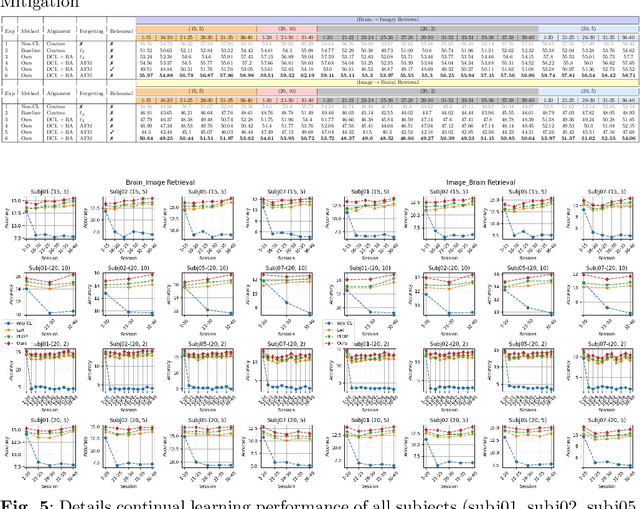
Memory decay makes it harder for the human brain to recognize visual objects and retain details. Consequently, recorded brain signals become weaker, uncertain, and contain poor visual context over time. This paper presents one of the first vision-learning approaches to address this problem. First, we statistically and experimentally demonstrate the existence of inconsistency in brain signals and its impact on the Vision-Brain Understanding (VBU) model. Our findings show that brain signal representations shift over recording sessions, leading to compounding bias, which poses challenges for model learning and degrades performance. Then, we propose a new Bias-Mitigation Continual Learning (BRAIN) approach to address these limitations. In this approach, the model is trained in a continual learning setup and mitigates the growing bias from each learning step. A new loss function named De-bias Contrastive Learning is also introduced to address the bias problem. In addition, to prevent catastrophic forgetting, where the model loses knowledge from previous sessions, the new Angular-based Forgetting Mitigation approach is introduced to preserve learned knowledge in the model. Finally, the empirical experiments demonstrate that our approach achieves State-of-the-Art (SOTA) performance across various benchmarks, surpassing prior and non-continual learning methods.
CLIFF: Continual Learning for Incremental Flake Features in 2D Material Identification
Aug 24, 2025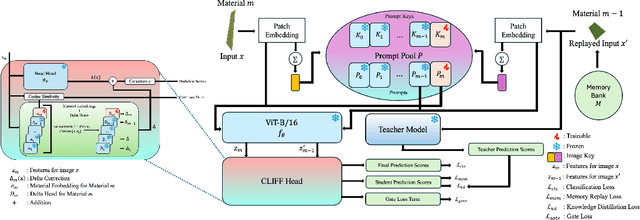
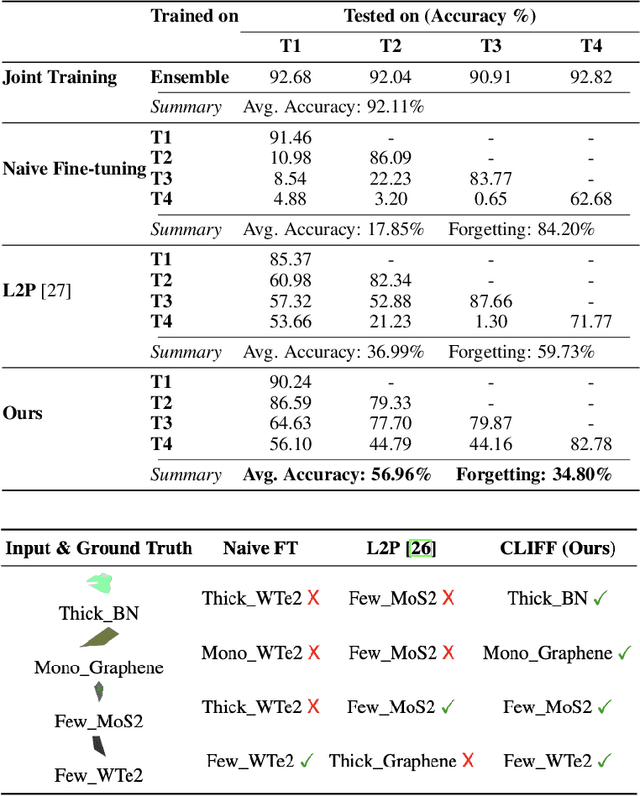
Identifying quantum flakes is crucial for scalable quantum hardware; however, automated layer classification from optical microscopy remains challenging due to substantial appearance shifts across different materials. In this paper, we propose a new Continual-Learning Framework for Flake Layer Classification (CLIFF). To our knowledge, this is the first systematic study of continual learning in the domain of two-dimensional (2D) materials. Our method enables the model to differentiate between materials and their physical and optical properties by freezing a backbone and base head trained on a reference material. For each new material, it learns a material-specific prompt, embedding, and a delta head. A prompt pool and a cosine-similarity gate modulate features and compute material-specific corrections. Additionally, we incorporate memory replay with knowledge distillation. CLIFF achieves competitive accuracy with significantly lower forgetting than naive fine-tuning and a prompt-based baseline.
AGP: A Novel Arabidopsis thaliana Genomics-Phenomics Dataset and its HyperGraph Baseline Benchmarking
Aug 19, 2025
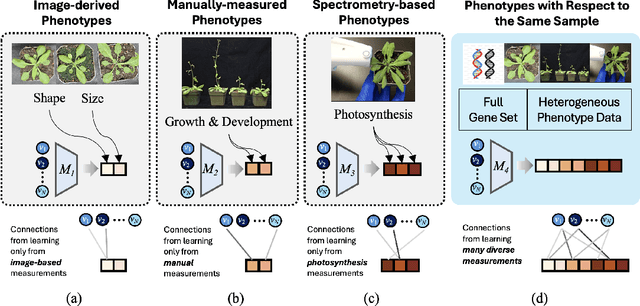
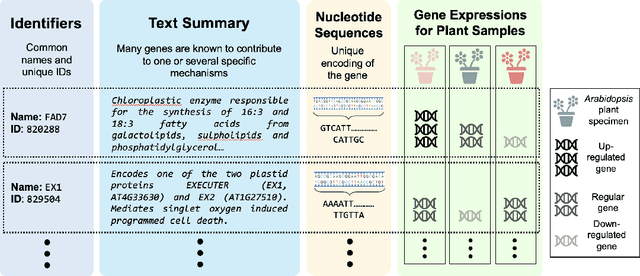

Understanding which genes control which traits in an organism remains one of the central challenges in biology. Despite significant advances in data collection technology, our ability to map genes to traits is still limited. This genome-to-phenome (G2P) challenge spans several problem domains, including plant breeding, and requires models capable of reasoning over high-dimensional, heterogeneous, and biologically structured data. Currently, however, many datasets solely capture genetic information or solely capture phenotype information. Additionally, phenotype data is very heterogeneous, which many datasets do not fully capture. The critical drawback is that these datasets are not integrated, that is, they do not link with each other to describe the same biological specimens. This limits machine learning models' ability to be informed on the various aspects of these specimens, impacting the breadth of correlations learned, and therefore their ability to make more accurate predictions. To address this gap, we present the Arabidopsis Genomics-Phenomics (AGP) Dataset, a curated multi-modal dataset linking gene expression profiles with phenotypic trait measurements in Arabidopsis thaliana, a model organism in plant biology. AGP supports tasks such as phenotype prediction and interpretable graph learning. In addition, we benchmark conventional regression and explanatory baselines, including a biologically-informed hypergraph baseline, to validate gene-trait associations. To the best of our knowledge, this is the first dataset that provides multi-modal gene information and heterogeneous trait or phenotype data for the same Arabidopsis thaliana specimens. With AGP, we aim to foster the research community towards accurately understanding the connection between genotypes and phenotypes using gene information, higher-order gene pairings, and trait data from several sources.
Directed-Tokens: A Robust Multi-Modality Alignment Approach to Large Language-Vision Models
Aug 19, 2025Large multimodal models (LMMs) have gained impressive performance due to their outstanding capability in various understanding tasks. However, these models still suffer from some fundamental limitations related to robustness and generalization due to the alignment and correlation between visual and textual features. In this paper, we introduce a simple but efficient learning mechanism for improving the robust alignment between visual and textual modalities by solving shuffling problems. In particular, the proposed approach can improve reasoning capability, visual understanding, and cross-modality alignment by introducing two new tasks: reconstructing the image order and the text order into the LMM's pre-training and fine-tuning phases. In addition, we propose a new directed-token approach to capture visual and textual knowledge, enabling the capability to reconstruct the correct order of visual inputs. Then, we introduce a new Image-to-Response Guided loss to further improve the visual understanding of the LMM in its responses. The proposed approach consistently achieves state-of-the-art (SoTA) performance compared with prior LMMs on academic task-oriented and instruction-following LMM benchmarks.
MANGO: Multimodal Attention-based Normalizing Flow Approach to Fusion Learning
Aug 13, 2025Multimodal learning has gained much success in recent years. However, current multimodal fusion methods adopt the attention mechanism of Transformers to implicitly learn the underlying correlation of multimodal features. As a result, the multimodal model cannot capture the essential features of each modality, making it difficult to comprehend complex structures and correlations of multimodal inputs. This paper introduces a novel Multimodal Attention-based Normalizing Flow (MANGO) approach\footnote{The source code of this work will be publicly available.} to developing explicit, interpretable, and tractable multimodal fusion learning. In particular, we propose a new Invertible Cross-Attention (ICA) layer to develop the Normalizing Flow-based Model for multimodal data. To efficiently capture the complex, underlying correlations in multimodal data in our proposed invertible cross-attention layer, we propose three new cross-attention mechanisms: Modality-to-Modality Cross-Attention (MMCA), Inter-Modality Cross-Attention (IMCA), and Learnable Inter-Modality Cross-Attention (LICA). Finally, we introduce a new Multimodal Attention-based Normalizing Flow to enable the scalability of our proposed method to high-dimensional multimodal data. Our experimental results on three different multimodal learning tasks, i.e., semantic segmentation, image-to-image translation, and movie genre classification, have illustrated the state-of-the-art (SoTA) performance of the proposed approach.
BIMA: Bijective Maximum Likelihood Learning Approach to Hallucination Prediction and Mitigation in Large Vision-Language Models
May 30, 2025



Large vision-language models have become widely adopted to advance in various domains. However, developing a trustworthy system with minimal interpretable characteristics of large-scale models presents a significant challenge. One of the most prevalent terms associated with the fallacy functions caused by these systems is hallucination, where the language model generates a response that does not correspond to the visual content. To mitigate this problem, several approaches have been developed, and one prominent direction is to ameliorate the decoding process. In this paper, we propose a new Bijective Maximum Likelihood Learning (BIMA) approach to hallucination mitigation using normalizing flow theories. The proposed BIMA method can efficiently mitigate the hallucination problem in prevailing vision-language models, resulting in significant improvements. Notably, BIMA achieves the average F1 score of 85.06% on POPE benchmark and remarkably reduce CHAIRS and CHAIRI by 7.6% and 2.6%, respectively. To the best of our knowledge, this is one of the first studies that contemplates the bijection means to reduce hallucination induced by large vision-language models.