 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAGP: A Novel Arabidopsis thaliana Genomics-Phenomics Dataset and its HyperGraph Baseline Benchmarking
Aug 19, 2025
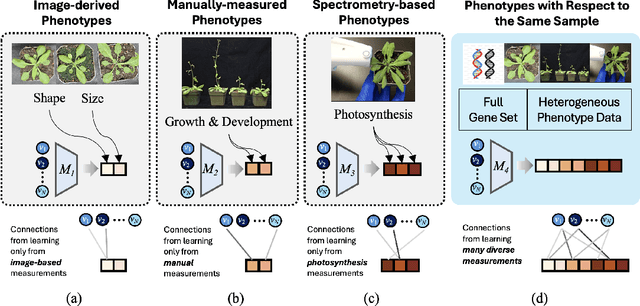
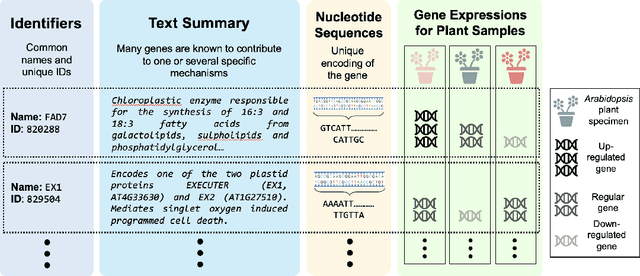

Understanding which genes control which traits in an organism remains one of the central challenges in biology. Despite significant advances in data collection technology, our ability to map genes to traits is still limited. This genome-to-phenome (G2P) challenge spans several problem domains, including plant breeding, and requires models capable of reasoning over high-dimensional, heterogeneous, and biologically structured data. Currently, however, many datasets solely capture genetic information or solely capture phenotype information. Additionally, phenotype data is very heterogeneous, which many datasets do not fully capture. The critical drawback is that these datasets are not integrated, that is, they do not link with each other to describe the same biological specimens. This limits machine learning models' ability to be informed on the various aspects of these specimens, impacting the breadth of correlations learned, and therefore their ability to make more accurate predictions. To address this gap, we present the Arabidopsis Genomics-Phenomics (AGP) Dataset, a curated multi-modal dataset linking gene expression profiles with phenotypic trait measurements in Arabidopsis thaliana, a model organism in plant biology. AGP supports tasks such as phenotype prediction and interpretable graph learning. In addition, we benchmark conventional regression and explanatory baselines, including a biologically-informed hypergraph baseline, to validate gene-trait associations. To the best of our knowledge, this is the first dataset that provides multi-modal gene information and heterogeneous trait or phenotype data for the same Arabidopsis thaliana specimens. With AGP, we aim to foster the research community towards accurately understanding the connection between genotypes and phenotypes using gene information, higher-order gene pairings, and trait data from several sources.
A Novel Dataset for Video-Based Autism Classification Leveraging Extra-Stimulatory Behavior
Sep 06, 2024



Autism Spectrum Disorder (ASD) can affect individuals at varying degrees of intensity, from challenges in overall health, communication, and sensory processing, and this often begins at a young age. Thus, it is critical for medical professionals to be able to accurately diagnose ASD in young children, but doing so is difficult. Deep learning can be responsibly leveraged to improve productivity in addressing this task. The availability of data, however, remains a considerable obstacle. Hence, in this work, we introduce the Video ASD dataset--a dataset that contains video frame convolutional and attention map feature data--to foster further progress in the task of ASD classification. The original videos showcase children reacting to chemo-sensory stimuli, among auditory, touch, and vision This dataset contains the features of the frames spanning 2,467 videos, for a total of approximately 1.4 million frames. Additionally, head pose angles are included to account for head movement noise, as well as full-sentence text labels for the taste and smell videos that describe how the facial expression changes before, immediately after, and long after interaction with the stimuli. In addition to providing features, we also test foundation models on this data to showcase how movement noise affects performance and the need for more data and more complex labels.
Neural Cell Video Synthesis via Optical-Flow Diffusion
Dec 06, 2022



The biomedical imaging world is notorious for working with small amounts of data, frustrating state-of-the-art efforts in the computer vision and deep learning worlds. With large datasets, it is easier to make progress we have seen from the natural image distribution. It is the same with microscopy videos of neuron cells moving in a culture. This problem presents several challenges as it can be difficult to grow and maintain the culture for days, and it is expensive to acquire the materials and equipment. In this work, we explore how to alleviate this data scarcity problem by synthesizing the videos. We, therefore, take the recent work of the video diffusion model to synthesize videos of cells from our training dataset. We then analyze the model's strengths and consistent shortcomings to guide us on improving video generation to be as high-quality as possible. To improve on such a task, we propose modifying the denoising function and adding motion information (dense optical flow) so that the model has more context regarding how video frames transition over time and how each pixel changes over time.