 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Dataset for Video-Based Autism Classification Leveraging Extra-Stimulatory Behavior
Sep 06, 2024



Autism Spectrum Disorder (ASD) can affect individuals at varying degrees of intensity, from challenges in overall health, communication, and sensory processing, and this often begins at a young age. Thus, it is critical for medical professionals to be able to accurately diagnose ASD in young children, but doing so is difficult. Deep learning can be responsibly leveraged to improve productivity in addressing this task. The availability of data, however, remains a considerable obstacle. Hence, in this work, we introduce the Video ASD dataset--a dataset that contains video frame convolutional and attention map feature data--to foster further progress in the task of ASD classification. The original videos showcase children reacting to chemo-sensory stimuli, among auditory, touch, and vision This dataset contains the features of the frames spanning 2,467 videos, for a total of approximately 1.4 million frames. Additionally, head pose angles are included to account for head movement noise, as well as full-sentence text labels for the taste and smell videos that describe how the facial expression changes before, immediately after, and long after interaction with the stimuli. In addition to providing features, we also test foundation models on this data to showcase how movement noise affects performance and the need for more data and more complex labels.
SoGAR: Self-supervised Spatiotemporal Attention-based Social Group Activity Recognition
Apr 27, 2023



This paper introduces a novel approach to Social Group Activity Recognition (SoGAR) using Self-supervised Transformers network that can effectively utilize unlabeled video data. To extract spatio-temporal information, we create local and global views with varying frame rates. Our self-supervised objective ensures that features extracted from contrasting views of the same video are consistent across spatio-temporal domains. Our proposed approach is efficient in using transformer-based encoders for alleviating the weakly supervised setting of group activity recognition. By leveraging the benefits of transformer models, our approach can model long-term relationships along spatio-temporal dimensions. Our proposed SoGAR method achieves state-of-the-art results on three group activity recognition benchmarks, namely JRDB-PAR, NBA, and Volleyball datasets, surpassing the current state-of-the-art in terms of F1-score, MCA, and MPCA metrics.
Micron-BERT: BERT-based Facial Micro-Expression Recognition
Apr 06, 2023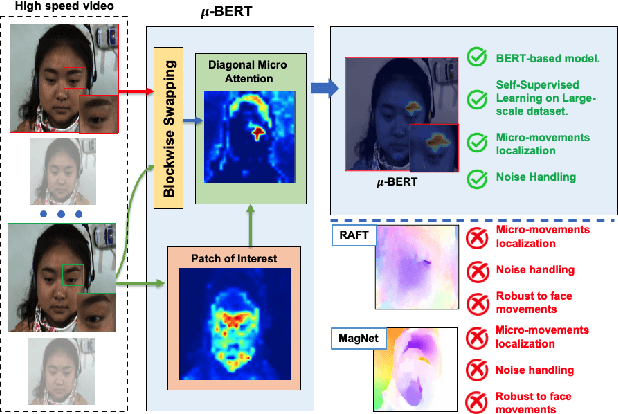



Micro-expression recognition is one of the most challenging topics in affective computing. It aims to recognize tiny facial movements difficult for humans to perceive in a brief period, i.e., 0.25 to 0.5 seconds. Recent advances in pre-training deep Bidirectional Transformers (BERT) have significantly improved self-supervised learning tasks in computer vision. However, the standard BERT in vision problems is designed to learn only from full images or videos, and the architecture cannot accurately detect details of facial micro-expressions. This paper presents Micron-BERT ($\mu$-BERT), a novel approach to facial micro-expression recognition. The proposed method can automatically capture these movements in an unsupervised manner based on two key ideas. First, we employ Diagonal Micro-Attention (DMA) to detect tiny differences between two frames. Second, we introduce a new Patch of Interest (PoI) module to localize and highlight micro-expression interest regions and simultaneously reduce noisy backgrounds and distractions. By incorporating these components into an end-to-end deep network, the proposed $\mu$-BERT significantly outperforms all previous work in various micro-expression tasks. $\mu$-BERT can be trained on a large-scale unlabeled dataset, i.e., up to 8 million images, and achieves high accuracy on new unseen facial micro-expression datasets. Empirical experiments show $\mu$-BERT consistently outperforms state-of-the-art performance on four micro-expression benchmarks, including SAMM, CASME II, SMIC, and CASME3, by significant margins. Code will be available at \url{https://github.com/uark-cviu/Micron-BERT}
DirecFormer: A Directed Attention in Transformer Approach to Robust Action Recognition
Mar 19, 2022
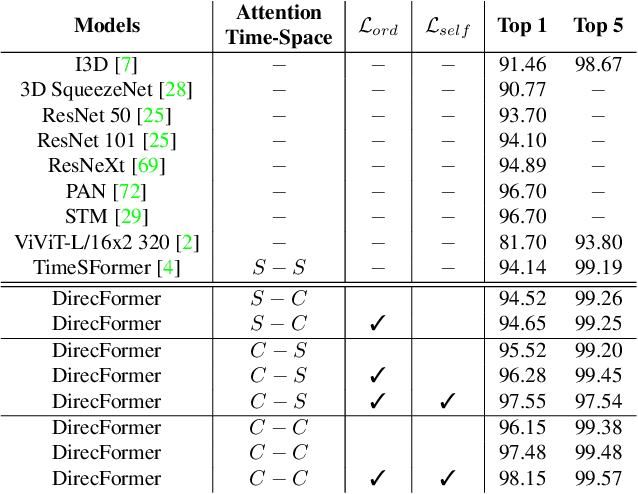

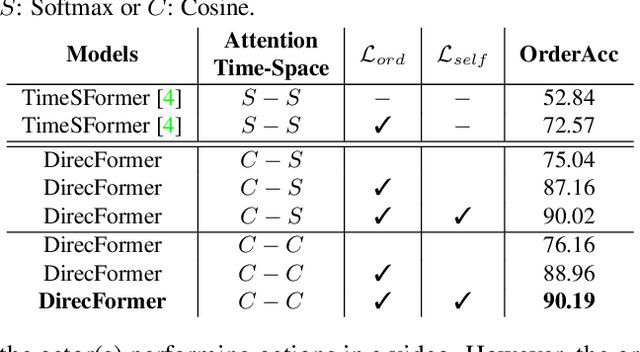
Human action recognition has recently become one of the popular research topics in the computer vision community. Various 3D-CNN based methods have been presented to tackle both the spatial and temporal dimensions in the task of video action recognition with competitive results. However, these methods have suffered some fundamental limitations such as lack of robustness and generalization, e.g., how does the temporal ordering of video frames affect the recognition results? This work presents a novel end-to-end Transformer-based Directed Attention (DirecFormer) framework for robust action recognition. The method takes a simple but novel perspective of Transformer-based approach to understand the right order of sequence actions. Therefore, the contributions of this work are three-fold. Firstly, we introduce the problem of ordered temporal learning issues to the action recognition problem. Secondly, a new Directed Attention mechanism is introduced to understand and provide attentions to human actions in the right order. Thirdly, we introduce the conditional dependency in action sequence modeling that includes orders and classes. The proposed approach consistently achieves the state-of-the-art (SOTA) results compared with the recent action recognition methods, on three standard large-scale benchmarks, i.e. Jester, Kinetics-400 and Something-Something-V2.