 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenQlaw: An Agentic AI Assistant for Analysis of 2D Quantum Materials
Mar 17, 2026The transition from optical identification of 2D quantum materials to practical device fabrication requires dynamic reasoning beyond the detection accuracy. While recent domain-specific Multimodal Large Language Models (MLLMs) successfully ground visual features using physics-informed reasoning, their outputs are optimized for step-by-step cognitive transparency. This yields verbose candidate enumerations followed by dense reasoning that, while accurate, may induce cognitive overload and lack immediate utility for real-world interaction with researchers. To address this challenge, we introduce OpenQlaw, an agentic orchestration system for analyzing 2D materials. The architecture is built upon NanoBot, a lightweight agentic framework inspired by OpenClaw, and QuPAINT, one of the first Physics-Aware Instruction Multi-modal platforms for Quantum Material Discovery. This allows accessibility to the lab floor via a variety of messaging channels. OpenQlaw allows the core Large Language Model (LLM) agent to orchestrate a domain-expert MLLM,with QuPAINT, as a specialized node, successfully decoupling visual identification from reasoning and deterministic image rendering. By parsing spatial data from the expert, the agent can dynamically process user queries, such as performing scale-aware physical computation or generating isolated visual annotations, and answer in a naturalistic manner. Crucially, the system features a persistent memory that enables the agent to save physical scale ratios (e.g., 1 pixel = 0.25 μm) for area computations and store sample preparation methods for efficacy comparison. The application of an agentic architecture, together with the extension that uses the core agent as an orchestrator for domain-specific experts, transforms isolated inferences into a context-aware assistant capable of accelerating high-throughput device fabrication.
QuPAINT: Physics-Aware Instruction Tuning Approach to Quantum Material Discovery
Feb 19, 2026Characterizing two-dimensional quantum materials from optical microscopy images is challenging due to the subtle layer-dependent contrast, limited labeled data, and significant variation across laboratories and imaging setups. Existing vision models struggle in this domain since they lack physical priors and cannot generalize to new materials or hardware conditions. This work presents a new physics-aware multimodal framework that addresses these limitations from both the data and model perspectives. We first present Synthia, a physics-based synthetic data generator that simulates realistic optical responses of quantum material flakes under thin-film interference. Synthia produces diverse and high-quality samples, helping reduce the dependence on expert manual annotation. We introduce QMat-Instruct, the first large-scale instruction dataset for quantum materials, comprising multimodal, physics-informed question-answer pairs designed to teach Multimodal Large Language Models (MLLMs) to understand the appearance and thickness of flakes. Then, we propose Physics-Aware Instruction Tuning (QuPAINT), a multimodal architecture that incorporates a Physics-Informed Attention module to fuse visual embeddings with optical priors, enabling more robust and discriminative flake representations. Finally, we establish QF-Bench, a comprehensive benchmark spanning multiple materials, substrates, and imaging settings, offering standardized protocols for fair and reproducible evaluation.
BRAIN: Bias-Mitigation Continual Learning Approach to Vision-Brain Understanding
Aug 25, 2025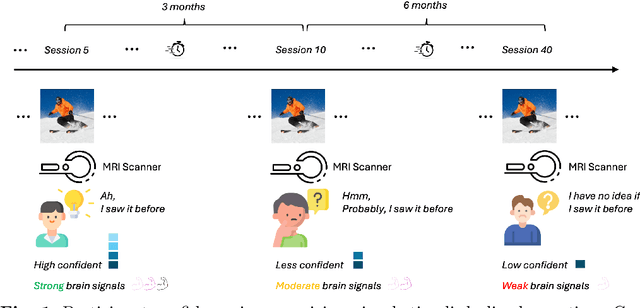
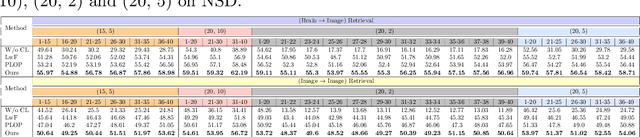
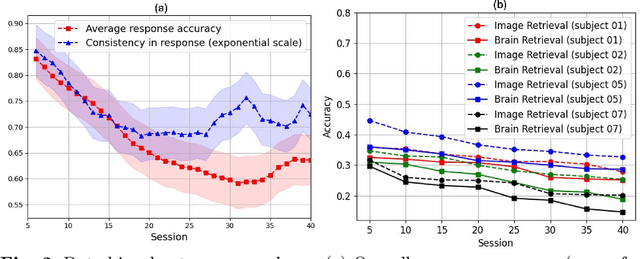
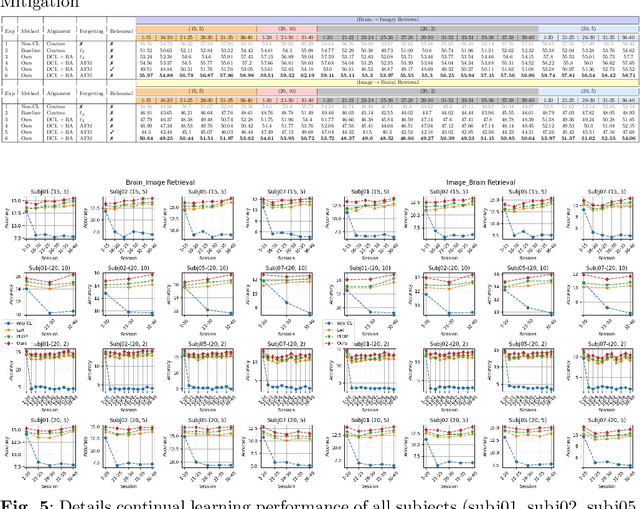
Memory decay makes it harder for the human brain to recognize visual objects and retain details. Consequently, recorded brain signals become weaker, uncertain, and contain poor visual context over time. This paper presents one of the first vision-learning approaches to address this problem. First, we statistically and experimentally demonstrate the existence of inconsistency in brain signals and its impact on the Vision-Brain Understanding (VBU) model. Our findings show that brain signal representations shift over recording sessions, leading to compounding bias, which poses challenges for model learning and degrades performance. Then, we propose a new Bias-Mitigation Continual Learning (BRAIN) approach to address these limitations. In this approach, the model is trained in a continual learning setup and mitigates the growing bias from each learning step. A new loss function named De-bias Contrastive Learning is also introduced to address the bias problem. In addition, to prevent catastrophic forgetting, where the model loses knowledge from previous sessions, the new Angular-based Forgetting Mitigation approach is introduced to preserve learned knowledge in the model. Finally, the empirical experiments demonstrate that our approach achieves State-of-the-Art (SOTA) performance across various benchmarks, surpassing prior and non-continual learning methods.
COBRA: A Continual Learning Approach to Vision-Brain Understanding
Nov 25, 2024



Vision-Brain Understanding (VBU) aims to extract visual information perceived by humans from brain activity recorded through functional Magnetic Resonance Imaging (fMRI). Despite notable advancements in recent years, existing studies in VBU continue to face the challenge of catastrophic forgetting, where models lose knowledge from prior subjects as they adapt to new ones. Addressing continual learning in this field is, therefore, essential. This paper introduces a novel framework called Continual Learning for Vision-Brain (COBRA) to address continual learning in VBU. Our approach includes three novel modules: a Subject Commonality (SC) module, a Prompt-based Subject Specific (PSS) module, and a transformer-based module for fMRI, denoted as MRIFormer module. The SC module captures shared vision-brain patterns across subjects, preserving this knowledge as the model encounters new subjects, thereby reducing the impact of catastrophic forgetting. On the other hand, the PSS module learns unique vision-brain patterns specific to each subject. Finally, the MRIFormer module contains a transformer encoder and decoder that learns the fMRI features for VBU from common and specific patterns. In a continual learning setup, COBRA is trained in new PSS and MRIFormer modules for new subjects, leaving the modules of previous subjects unaffected. As a result, COBRA effectively addresses catastrophic forgetting and achieves state-of-the-art performance in both continual learning and vision-brain reconstruction tasks, surpassing previous methods.
Quantum-Brain: Quantum-Inspired Neural Network Approach to Vision-Brain Understanding
Nov 20, 2024



Vision-brain understanding aims to extract semantic information about brain signals from human perceptions. Existing deep learning methods for vision-brain understanding are usually introduced in a traditional learning paradigm missing the ability to learn the connectivities between brain regions. Meanwhile, the quantum computing theory offers a new paradigm for designing deep learning models. Motivated by the connectivities in the brain signals and the entanglement properties in quantum computing, we propose a novel Quantum-Brain approach, a quantum-inspired neural network, to tackle the vision-brain understanding problem. To compute the connectivity between areas in brain signals, we introduce a new Quantum-Inspired Voxel-Controlling module to learn the impact of a brain voxel on others represented in the Hilbert space. To effectively learn connectivity, a novel Phase-Shifting module is presented to calibrate the value of the brain signals. Finally, we introduce a new Measurement-like Projection module to present the connectivity information from the Hilbert space into the feature space. The proposed approach can learn to find the connectivities between fMRI voxels and enhance the semantic information obtained from human perceptions. Our experimental results on the Natural Scene Dataset benchmarks illustrate the effectiveness of the proposed method with Top-1 accuracies of 95.1% and 95.6% on image and brain retrieval tasks and an Inception score of 95.3% on fMRI-to-image reconstruction task. Our proposed quantum-inspired network brings a potential paradigm to solving the vision-brain problems via the quantum computing theory.
Hierarchical Quantum Control Gates for Functional MRI Understanding
Aug 07, 2024



Quantum computing has emerged as a powerful tool for solving complex problems intractable for classical computers, particularly in popular fields such as cryptography, optimization, and neurocomputing. In this paper, we present a new quantum-based approach named the Hierarchical Quantum Control Gates (HQCG) method for efficient understanding of Functional Magnetic Resonance Imaging (fMRI) data. This approach includes two novel modules: the Local Quantum Control Gate (LQCG) and the Global Quantum Control Gate (GQCG), which are designed to extract local and global features of fMRI signals, respectively. Our method operates end-to-end on a quantum machine, leveraging quantum mechanics to learn patterns within extremely high-dimensional fMRI signals, such as 30,000 samples which is a challenge for classical computers. Empirical results demonstrate that our approach significantly outperforms classical methods. Additionally, we found that the proposed quantum model is more stable and less prone to overfitting than the classical methods.
QClusformer: A Quantum Transformer-based Framework for Unsupervised Visual Clustering
May 30, 2024



Unsupervised vision clustering, a cornerstone in computer vision, has been studied for decades, yielding significant outcomes across numerous vision tasks. However, these algorithms involve substantial computational demands when confronted with vast amounts of unlabeled data. Conversely, Quantum computing holds promise in expediting unsupervised algorithms when handling large-scale databases. In this study, we introduce QClusformer, a pioneering Transformer-based framework leveraging Quantum machines to tackle unsupervised vision clustering challenges. Specifically, we design the Transformer architecture, including the self-attention module and transformer blocks, from a Quantum perspective to enable execution on Quantum hardware. In addition, we present QClusformer, a variant based on the Transformer architecture, tailored for unsupervised vision clustering tasks. By integrating these elements into an end-to-end framework, QClusformer consistently outperforms previous methods running on classical computers. Empirical evaluations across diverse benchmarks, including MS-Celeb-1M and DeepFashion, underscore the superior performance of QClusformer compared to state-of-the-art methods.
Quantum Visual Feature Encoding Revisited
May 30, 2024



Although quantum machine learning has been introduced for a while, its applications in computer vision are still limited. This paper, therefore, revisits the quantum visual encoding strategies, the initial step in quantum machine learning. Investigating the root cause, we uncover that the existing quantum encoding design fails to ensure information preservation of the visual features after the encoding process, thus complicating the learning process of the quantum machine learning models. In particular, the problem, termed "Quantum Information Gap" (QIG), leads to a gap of information between classical and corresponding quantum features. We provide theoretical proof and practical demonstrations of that found and underscore the significance of QIG, as it directly impacts the performance of quantum machine learning algorithms. To tackle this challenge, we introduce a simple but efficient new loss function named Quantum Information Preserving (QIP) to minimize this gap, resulting in enhanced performance of quantum machine learning algorithms. Extensive experiments validate the effectiveness of our approach, showcasing superior performance compared to current methodologies and consistently achieving state-of-the-art results in quantum modeling.
BRACTIVE: A Brain Activation Approach to Human Visual Brain Learning
May 29, 2024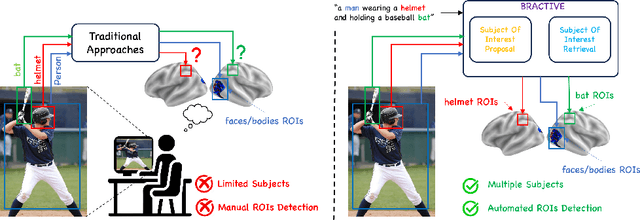
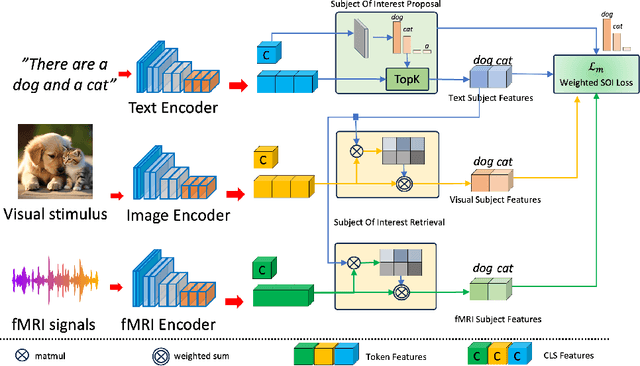

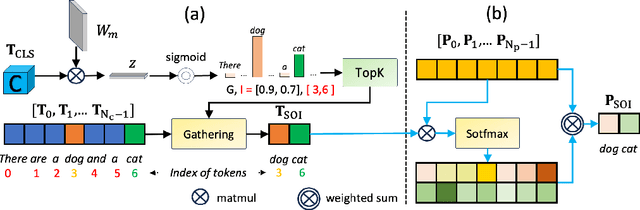
The human brain is a highly efficient processing unit, and understanding how it works can inspire new algorithms and architectures in machine learning. In this work, we introduce a novel framework named Brain Activation Network (BRACTIVE), a transformer-based approach to studying the human visual brain. The main objective of BRACTIVE is to align the visual features of subjects with corresponding brain representations via fMRI signals. It allows us to identify the brain's Regions of Interest (ROI) of the subjects. Unlike previous brain research methods, which can only identify ROIs for one subject at a time and are limited by the number of subjects, BRACTIVE automatically extends this identification to multiple subjects and ROIs. Our experiments demonstrate that BRACTIVE effectively identifies person-specific regions of interest, such as face and body-selective areas, aligning with neuroscience findings and indicating potential applicability to various object categories. More importantly, we found that leveraging human visual brain activity to guide deep neural networks enhances performance across various benchmarks. It encourages the potential of BRACTIVE in both neuroscience and machine intelligence studies.
Brainformer: Modeling MRI Brain Functions to Machine Vision
Nov 30, 2023



"Perception is reality". Human perception plays a vital role in forming beliefs and understanding reality. Exploring how the human brain works in the visual system facilitates bridging the gap between human visual perception and computer vision models. However, neuroscientists study the brain via Neuroimaging, i.e., Functional Magnetic Resonance Imaging (fMRI), to discover the brain's functions. These approaches face interpretation challenges where fMRI data can be complex and require expertise. Therefore, neuroscientists make inferences about cognitive processes based on patterns of brain activities, which can lead to potential misinterpretation or limited functional understanding. In this work, we first present a simple yet effective Brainformer approach, a novel Transformer-based framework, to analyze the patterns of fMRI in the human perception system from the machine learning perspective. Secondly, we introduce a novel mechanism incorporating fMRI, which represents the human brain activities, as the supervision for the machine vision model. This work also introduces a novel perspective on transferring knowledge from human perception to neural networks. Through our experiments, we demonstrated that by leveraging fMRI information, the machine vision model can achieve potential results compared to the current State-of-the-art methods in various image recognition tasks.