 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Evolution with Graph-of-Thoughts: A Bi-Level Language Model Framework for Reinforcement Learning
Sep 19, 2025
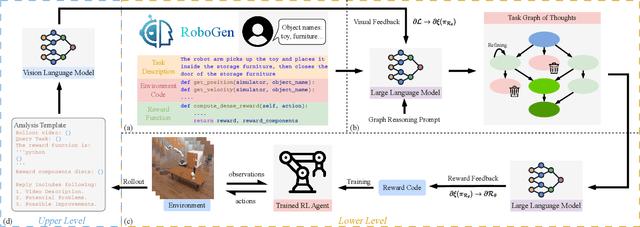


Designing effective reward functions remains a major challenge in reinforcement learning (RL), often requiring considerable human expertise and iterative refinement. Recent advances leverage Large Language Models (LLMs) for automated reward design, but these approaches are limited by hallucinations, reliance on human feedback, and challenges with handling complex, multi-step tasks. In this work, we introduce Reward Evolution with Graph-of-Thoughts (RE-GoT), a novel bi-level framework that enhances LLMs with structured graph-based reasoning and integrates Visual Language Models (VLMs) for automated rollout evaluation. RE-GoT first decomposes tasks into text-attributed graphs, enabling comprehensive analysis and reward function generation, and then iteratively refines rewards using visual feedback from VLMs without human intervention. Extensive experiments on 10 RoboGen and 4 ManiSkill2 tasks demonstrate that RE-GoT consistently outperforms existing LLM-based baselines. On RoboGen, our method improves average task success rates by 32.25%, with notable gains on complex multi-step tasks. On ManiSkill2, RE-GoT achieves an average success rate of 93.73% across four diverse manipulation tasks, significantly surpassing prior LLM-based approaches and even exceeding expert-designed rewards. Our results indicate that combining LLMs and VLMs with graph-of-thoughts reasoning provides a scalable and effective solution for autonomous reward evolution in RL.
Image Tokenizer Needs Post-Training
Sep 15, 2025Recent image generative models typically capture the image distribution in a pre-constructed latent space, relying on a frozen image tokenizer. However, there exists a significant discrepancy between the reconstruction and generation distribution, where current tokenizers only prioritize the reconstruction task that happens before generative training without considering the generation errors during sampling. In this paper, we comprehensively analyze the reason for this discrepancy in a discrete latent space, and, from which, we propose a novel tokenizer training scheme including both main-training and post-training, focusing on improving latent space construction and decoding respectively. During the main training, a latent perturbation strategy is proposed to simulate sampling noises, \ie, the unexpected tokens generated in generative inference. Specifically, we propose a plug-and-play tokenizer training scheme, which significantly enhances the robustness of tokenizer, thus boosting the generation quality and convergence speed, and a novel tokenizer evaluation metric, \ie, pFID, which successfully correlates the tokenizer performance to generation quality. During post-training, we further optimize the tokenizer decoder regarding a well-trained generative model to mitigate the distribution difference between generated and reconstructed tokens. With a $\sim$400M generator, a discrete tokenizer trained with our proposed main training achieves a notable 1.60 gFID and further obtains 1.36 gFID with the additional post-training. Further experiments are conducted to broadly validate the effectiveness of our post-training strategy on off-the-shelf discrete and continuous tokenizers, coupled with autoregressive and diffusion-based generators.
STELAR-VISION: Self-Topology-Aware Efficient Learning for Aligned Reasoning in Vision
Aug 12, 2025Vision-language models (VLMs) have made significant strides in reasoning, yet they often struggle with complex multimodal tasks and tend to generate overly verbose outputs. A key limitation is their reliance on chain-of-thought (CoT) reasoning, despite many tasks benefiting from alternative topologies like trees or graphs. To address this, we introduce STELAR-Vision, a training framework for topology-aware reasoning. At its core is TopoAug, a synthetic data pipeline that enriches training with diverse topological structures. Using supervised fine-tuning and reinforcement learning, we post-train Qwen2VL models with both accuracy and efficiency in mind. Additionally, we propose Frugal Learning, which reduces output length with minimal accuracy loss. On MATH-V and VLM-S2H, STELAR-Vision improves accuracy by 9.7% over its base model and surpasses the larger Qwen2VL-72B-Instruct by 7.3%. On five out-of-distribution benchmarks, it outperforms Phi-4-Multimodal-Instruct by up to 28.4% and LLaMA-3.2-11B-Vision-Instruct by up to 13.2%, demonstrating strong generalization. Compared to Chain-Only training, our approach achieves 4.3% higher overall accuracy on in-distribution datasets and consistently outperforms across all OOD benchmarks. We have released datasets, and code will be available.
Robust Latent Matters: Boosting Image Generation with Sampling Error
Mar 11, 2025



Recent image generation schemes typically capture image distribution in a pre-constructed latent space relying on a frozen image tokenizer. Though the performance of tokenizer plays an essential role to the successful generation, its current evaluation metrics (e.g. rFID) fail to precisely assess the tokenizer and correlate its performance to the generation quality (e.g. gFID). In this paper, we comprehensively analyze the reason for the discrepancy of reconstruction and generation qualities in a discrete latent space, and, from which, we propose a novel plug-and-play tokenizer training scheme to facilitate latent space construction. Specifically, a latent perturbation approach is proposed to simulate sampling noises, i.e., the unexpected tokens sampled, from the generative process. With the latent perturbation, we further propose (1) a novel tokenizer evaluation metric, i.e., pFID, which successfully correlates the tokenizer performance to generation quality and (2) a plug-and-play tokenizer training scheme, which significantly enhances the robustness of tokenizer thus boosting the generation quality and convergence speed. Extensive benchmarking are conducted with 11 advanced discrete image tokenizers with 2 autoregressive generation models to validate our approach. The tokenizer trained with our proposed latent perturbation achieve a notable 1.60 gFID with classifier-free guidance (CFG) and 3.45 gFID without CFG with a $\sim$400M generator. Code: https://github.com/lxa9867/ImageFolder.
SOLAR: Scalable Optimization of Large-scale Architecture for Reasoning
Mar 06, 2025Large Language Models (LLMs) excel in reasoning but remain constrained by their Chain-of-Thought (CoT) approach, which struggles with complex tasks requiring more nuanced topological reasoning. We introduce SOLAR, Scalable Optimization of Large-scale Architecture for Reasoning, a framework that dynamically optimizes various reasoning topologies to enhance accuracy and efficiency. Our Topological Annotation Generation (TAG) system automates topological dataset creation and segmentation, improving post-training and evaluation. Additionally, we propose Topological-Scaling, a reward-driven framework that aligns training and inference scaling, equipping LLMs with adaptive, task-aware reasoning. SOLAR achieves substantial gains on MATH and GSM8K: +5% accuracy with Topological Tuning, +9% with Topological Reward, and +10.02% with Hybrid Scaling. It also reduces response length by over 5% for complex problems, lowering inference latency. To foster the reward system, we train a multi-task Topological Reward Model (M-TRM), which autonomously selects the best reasoning topology and answer in a single pass, eliminating the need for training and inference on multiple single-task TRMs (S-TRMs), thus reducing both training cost and inference latency. In addition, in terms of performance, M-TRM surpasses all S-TRMs, improving accuracy by +10% and rank correlation by +9%. To the best of our knowledge, SOLAR sets a new benchmark for scalable, high-precision LLM reasoning while introducing an automated annotation process and a dynamic reasoning topology competition mechanism.
Hierarchical Knowledge Graph Construction from Images for Scalable E-Commerce
Oct 28, 2024



Knowledge Graph (KG) is playing an increasingly important role in various AI systems. For e-commerce, an efficient and low-cost automated knowledge graph construction method is the foundation of enabling various successful downstream applications. In this paper, we propose a novel method for constructing structured product knowledge graphs from raw product images. The method cooperatively leverages recent advances in the vision-language model (VLM) and large language model (LLM), fully automating the process and allowing timely graph updates. We also present a human-annotated e-commerce product dataset for benchmarking product property extraction in knowledge graph construction. Our method outperforms our baseline in all metrics and evaluated properties, demonstrating its effectiveness and bright usage potential.
Efficient Autoregressive Audio Modeling via Next-Scale Prediction
Aug 16, 2024



Audio generation has achieved remarkable progress with the advance of sophisticated generative models, such as diffusion models (DMs) and autoregressive (AR) models. However, due to the naturally significant sequence length of audio, the efficiency of audio generation remains an essential issue to be addressed, especially for AR models that are incorporated in large language models (LLMs). In this paper, we analyze the token length of audio tokenization and propose a novel \textbf{S}cale-level \textbf{A}udio \textbf{T}okenizer (SAT), with improved residual quantization. Based on SAT, a scale-level \textbf{A}coustic \textbf{A}uto\textbf{R}egressive (AAR) modeling framework is further proposed, which shifts the next-token AR prediction to next-scale AR prediction, significantly reducing the training cost and inference time. To validate the effectiveness of the proposed approach, we comprehensively analyze design choices and demonstrate the proposed AAR framework achieves a remarkable \textbf{35}$\times$ faster inference speed and +\textbf{1.33} Fr\'echet Audio Distance (FAD) against baselines on the AudioSet benchmark. Code: \url{https://github.com/qiuk2/AAR}.
A Reference-Based 3D Semantic-Aware Framework for Accurate Local Facial Attribute Editing
Jul 29, 2024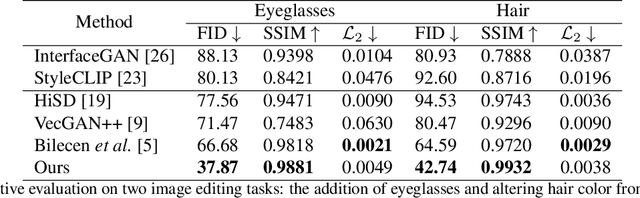
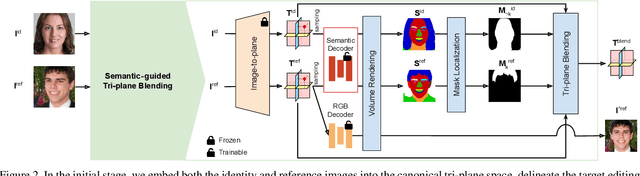

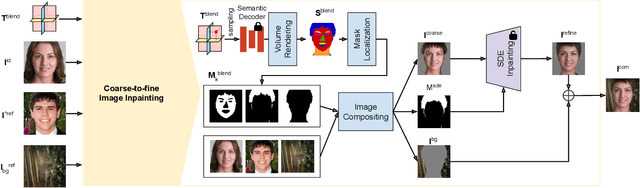
Facial attribute editing plays a crucial role in synthesizing realistic faces with specific characteristics while maintaining realistic appearances. Despite advancements, challenges persist in achieving precise, 3D-aware attribute modifications, which are crucial for consistent and accurate representations of faces from different angles. Current methods struggle with semantic entanglement and lack effective guidance for incorporating attributes while maintaining image integrity. To address these issues, we introduce a novel framework that merges the strengths of latent-based and reference-based editing methods. Our approach employs a 3D GAN inversion technique to embed attributes from the reference image into a tri-plane space, ensuring 3D consistency and realistic viewing from multiple perspectives. We utilize blending techniques and predicted semantic masks to locate precise edit regions, merging them with the contextual guidance from the reference image. A coarse-to-fine inpainting strategy is then applied to preserve the integrity of untargeted areas, significantly enhancing realism. Our evaluations demonstrate superior performance across diverse editing tasks, validating our framework's effectiveness in realistic and applicable facial attribute editing.
RTGen: Generating Region-Text Pairs for Open-Vocabulary Object Detection
May 30, 2024



Open-vocabulary object detection (OVD) requires solid modeling of the region-semantic relationship, which could be learned from massive region-text pairs. However, such data is limited in practice due to significant annotation costs. In this work, we propose RTGen to generate scalable open-vocabulary region-text pairs and demonstrate its capability to boost the performance of open-vocabulary object detection. RTGen includes both text-to-region and region-to-text generation processes on scalable image-caption data. The text-to-region generation is powered by image inpainting, directed by our proposed scene-aware inpainting guider for overall layout harmony. For region-to-text generation, we perform multiple region-level image captioning with various prompts and select the best matching text according to CLIP similarity. To facilitate detection training on region-text pairs, we also introduce a localization-aware region-text contrastive loss that learns object proposals tailored with different localization qualities. Extensive experiments demonstrate that our RTGen can serve as a scalable, semantically rich, and effective source for open-vocabulary object detection and continue to improve the model performance when more data is utilized, delivering superior performance compared to the existing state-of-the-art methods.
Fairness in Visual Clustering: A Novel Transformer Clustering Approach
Apr 14, 2023



Promoting fairness for deep clustering models in unsupervised clustering settings to reduce demographic bias is a challenging goal. This is because of the limitation of large-scale balanced data with well-annotated labels for sensitive or protected attributes. In this paper, we first evaluate demographic bias in deep clustering models from the perspective of cluster purity, which is measured by the ratio of positive samples within a cluster to their correlation degree. This measurement is adopted as an indication of demographic bias. Then, a novel loss function is introduced to encourage a purity consistency for all clusters to maintain the fairness aspect of the learned clustering model. Moreover, we present a novel attention mechanism, Cross-attention, to measure correlations between multiple clusters, strengthening faraway positive samples and improving the purity of clusters during the learning process. Experimental results on a large-scale dataset with numerous attribute settings have demonstrated the effectiveness of the proposed approach on both clustering accuracy and fairness enhancement on several sensitive attributes.