 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReferring Layer Decomposition
Feb 22, 2026Precise, object-aware control over visual content is essential for advanced image editing and compositional generation. Yet, most existing approaches operate on entire images holistically, limiting the ability to isolate and manipulate individual scene elements. In contrast, layered representations, where scenes are explicitly separated into objects, environmental context, and visual effects, provide a more intuitive and structured framework for interpreting and editing visual content. To bridge this gap and enable both compositional understanding and controllable editing, we introduce the Referring Layer Decomposition (RLD) task, which predicts complete RGBA layers from a single RGB image, conditioned on flexible user prompts, such as spatial inputs (e.g., points, boxes, masks), natural language descriptions, or combinations thereof. At the core is the RefLade, a large-scale dataset comprising 1.11M image-layer-prompt triplets produced by our scalable data engine, along with 100K manually curated, high-fidelity layers. Coupled with a perceptually grounded, human-preference-aligned automatic evaluation protocol, RefLade establishes RLD as a well-defined and benchmarkable research task. Building on this foundation, we present RefLayer, a simple baseline designed for prompt-conditioned layer decomposition, achieving high visual fidelity and semantic alignment. Extensive experiments show our approach enables effective training, reliable evaluation, and high-quality image decomposition, while exhibiting strong zero-shot generalization capabilities.
STELAR-VISION: Self-Topology-Aware Efficient Learning for Aligned Reasoning in Vision
Aug 12, 2025Vision-language models (VLMs) have made significant strides in reasoning, yet they often struggle with complex multimodal tasks and tend to generate overly verbose outputs. A key limitation is their reliance on chain-of-thought (CoT) reasoning, despite many tasks benefiting from alternative topologies like trees or graphs. To address this, we introduce STELAR-Vision, a training framework for topology-aware reasoning. At its core is TopoAug, a synthetic data pipeline that enriches training with diverse topological structures. Using supervised fine-tuning and reinforcement learning, we post-train Qwen2VL models with both accuracy and efficiency in mind. Additionally, we propose Frugal Learning, which reduces output length with minimal accuracy loss. On MATH-V and VLM-S2H, STELAR-Vision improves accuracy by 9.7% over its base model and surpasses the larger Qwen2VL-72B-Instruct by 7.3%. On five out-of-distribution benchmarks, it outperforms Phi-4-Multimodal-Instruct by up to 28.4% and LLaMA-3.2-11B-Vision-Instruct by up to 13.2%, demonstrating strong generalization. Compared to Chain-Only training, our approach achieves 4.3% higher overall accuracy on in-distribution datasets and consistently outperforms across all OOD benchmarks. We have released datasets, and code will be available.
Masked Autoencoders Are Effective Tokenizers for Diffusion Models
Feb 05, 2025Recent advances in latent diffusion models have demonstrated their effectiveness for high-resolution image synthesis. However, the properties of the latent space from tokenizer for better learning and generation of diffusion models remain under-explored. Theoretically and empirically, we find that improved generation quality is closely tied to the latent distributions with better structure, such as the ones with fewer Gaussian Mixture modes and more discriminative features. Motivated by these insights, we propose MAETok, an autoencoder (AE) leveraging mask modeling to learn semantically rich latent space while maintaining reconstruction fidelity. Extensive experiments validate our analysis, demonstrating that the variational form of autoencoders is not necessary, and a discriminative latent space from AE alone enables state-of-the-art performance on ImageNet generation using only 128 tokens. MAETok achieves significant practical improvements, enabling a gFID of 1.69 with 76x faster training and 31x higher inference throughput for 512x512 generation. Our findings show that the structure of the latent space, rather than variational constraints, is crucial for effective diffusion models. Code and trained models are released.
Semi-Supervised Learning from Small Annotated Data and Large Unlabeled Data for Fine-grained PICO Entity Recognition
Dec 26, 2024



Objective: Extracting PICO elements -- Participants, Intervention, Comparison, and Outcomes -- from clinical trial literature is essential for clinical evidence retrieval, appraisal, and synthesis. Existing approaches do not distinguish the attributes of PICO entities. This study aims to develop a named entity recognition (NER) model to extract PICO entities with fine granularities. Materials and Methods: Using a corpus of 2,511 abstracts with PICO mentions from 4 public datasets, we developed a semi-supervised method to facilitate the training of a NER model, FinePICO, by combining limited annotated data of PICO entities and abundant unlabeled data. For evaluation, we divided the entire dataset into two subsets: a smaller group with annotations and a larger group without annotations. We then established the theoretical lower and upper performance bounds based on the performance of supervised learning models trained solely on the small, annotated subset and on the entire set with complete annotations, respectively. Finally, we evaluated FinePICO on both the smaller annotated subset and the larger, initially unannotated subset. We measured the performance of FinePICO using precision, recall, and F1. Results: Our method achieved precision/recall/F1 of 0.567/0.636/0.60, respectively, using a small set of annotated samples, outperforming the baseline model (F1: 0.437) by more than 16\%. The model demonstrates generalizability to a different PICO framework and to another corpus, which consistently outperforms the benchmark in diverse experimental settings (p-value \textless0.001). Conclusion: This study contributes a generalizable and effective semi-supervised approach to named entity recognition leveraging large unlabeled data together with small, annotated data. It also initially supports fine-grained PICO extraction.
A MapReduce Approach to Effectively Utilize Long Context Information in Retrieval Augmented Language Models
Dec 17, 2024



While holding great promise for improving and facilitating healthcare, large language models (LLMs) struggle to produce up-to-date responses on evolving topics due to outdated knowledge or hallucination. Retrieval-augmented generation (RAG) is a pivotal innovation that improves the accuracy and relevance of LLM responses by integrating LLMs with a search engine and external sources of knowledge. However, the quality of RAG responses can be largely impacted by the rank and density of key information in the retrieval results, such as the "lost-in-the-middle" problem. In this work, we aim to improve the robustness and reliability of the RAG workflow in the medical domain. Specifically, we propose a map-reduce strategy, BriefContext, to combat the "lost-in-the-middle" issue without modifying the model weights. We demonstrated the advantage of the workflow with various LLM backbones and on multiple QA datasets. This method promises to improve the safety and reliability of LLMs deployed in healthcare domains.
SoftVQ-VAE: Efficient 1-Dimensional Continuous Tokenizer
Dec 14, 2024



Efficient image tokenization with high compression ratios remains a critical challenge for training generative models. We present SoftVQ-VAE, a continuous image tokenizer that leverages soft categorical posteriors to aggregate multiple codewords into each latent token, substantially increasing the representation capacity of the latent space. When applied to Transformer-based architectures, our approach compresses 256x256 and 512x512 images using as few as 32 or 64 1-dimensional tokens. Not only does SoftVQ-VAE show consistent and high-quality reconstruction, more importantly, it also achieves state-of-the-art and significantly faster image generation results across different denoising-based generative models. Remarkably, SoftVQ-VAE improves inference throughput by up to 18x for generating 256x256 images and 55x for 512x512 images while achieving competitive FID scores of 1.78 and 2.21 for SiT-XL. It also improves the training efficiency of the generative models by reducing the number of training iterations by 2.3x while maintaining comparable performance. With its fully-differentiable design and semantic-rich latent space, our experiment demonstrates that SoftVQ-VQE achieves efficient tokenization without compromising generation quality, paving the way for more efficient generative models. Code and model are released.
Hierarchical Knowledge Graph Construction from Images for Scalable E-Commerce
Oct 28, 2024



Knowledge Graph (KG) is playing an increasingly important role in various AI systems. For e-commerce, an efficient and low-cost automated knowledge graph construction method is the foundation of enabling various successful downstream applications. In this paper, we propose a novel method for constructing structured product knowledge graphs from raw product images. The method cooperatively leverages recent advances in the vision-language model (VLM) and large language model (LLM), fully automating the process and allowing timely graph updates. We also present a human-annotated e-commerce product dataset for benchmarking product property extraction in knowledge graph construction. Our method outperforms our baseline in all metrics and evaluated properties, demonstrating its effectiveness and bright usage potential.
A Reference-Based 3D Semantic-Aware Framework for Accurate Local Facial Attribute Editing
Jul 29, 2024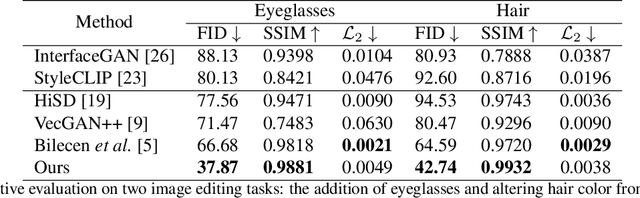
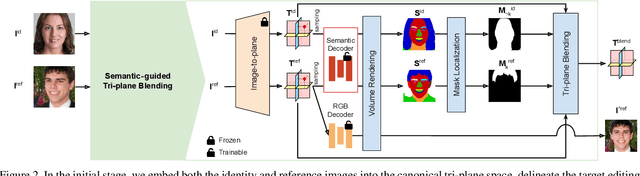

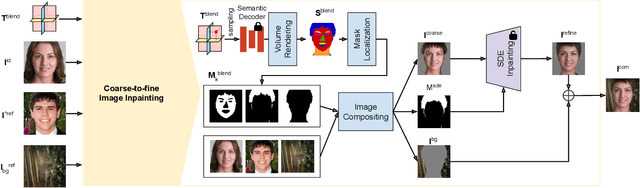
Facial attribute editing plays a crucial role in synthesizing realistic faces with specific characteristics while maintaining realistic appearances. Despite advancements, challenges persist in achieving precise, 3D-aware attribute modifications, which are crucial for consistent and accurate representations of faces from different angles. Current methods struggle with semantic entanglement and lack effective guidance for incorporating attributes while maintaining image integrity. To address these issues, we introduce a novel framework that merges the strengths of latent-based and reference-based editing methods. Our approach employs a 3D GAN inversion technique to embed attributes from the reference image into a tri-plane space, ensuring 3D consistency and realistic viewing from multiple perspectives. We utilize blending techniques and predicted semantic masks to locate precise edit regions, merging them with the contextual guidance from the reference image. A coarse-to-fine inpainting strategy is then applied to preserve the integrity of untargeted areas, significantly enhancing realism. Our evaluations demonstrate superior performance across diverse editing tasks, validating our framework's effectiveness in realistic and applicable facial attribute editing.
RTGen: Generating Region-Text Pairs for Open-Vocabulary Object Detection
May 30, 2024



Open-vocabulary object detection (OVD) requires solid modeling of the region-semantic relationship, which could be learned from massive region-text pairs. However, such data is limited in practice due to significant annotation costs. In this work, we propose RTGen to generate scalable open-vocabulary region-text pairs and demonstrate its capability to boost the performance of open-vocabulary object detection. RTGen includes both text-to-region and region-to-text generation processes on scalable image-caption data. The text-to-region generation is powered by image inpainting, directed by our proposed scene-aware inpainting guider for overall layout harmony. For region-to-text generation, we perform multiple region-level image captioning with various prompts and select the best matching text according to CLIP similarity. To facilitate detection training on region-text pairs, we also introduce a localization-aware region-text contrastive loss that learns object proposals tailored with different localization qualities. Extensive experiments demonstrate that our RTGen can serve as a scalable, semantically rich, and effective source for open-vocabulary object detection and continue to improve the model performance when more data is utilized, delivering superior performance compared to the existing state-of-the-art methods.
Enhanced Training of Query-Based Object Detection via Selective Query Recollection
Dec 15, 2022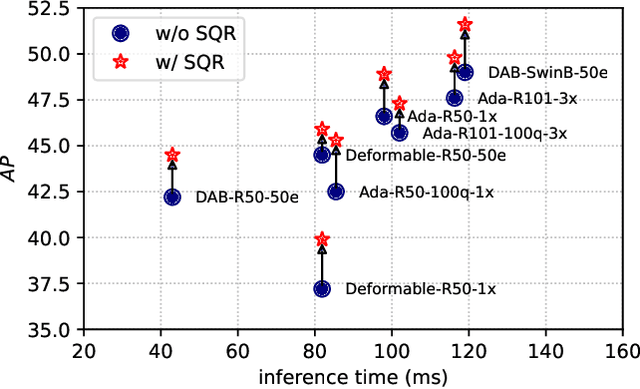

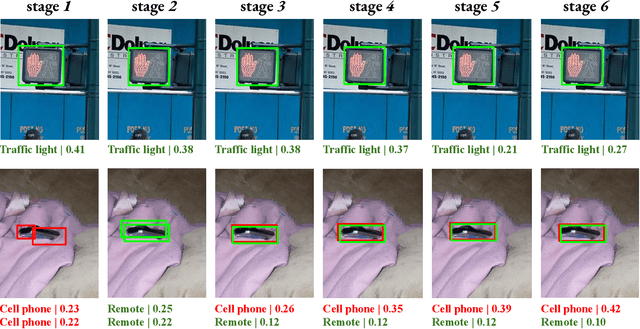
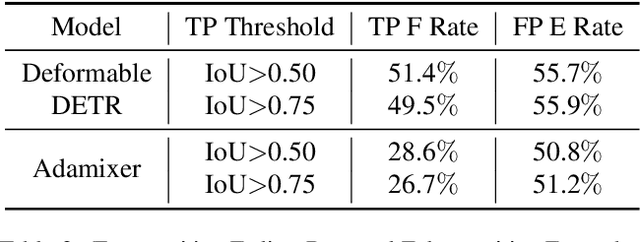
This paper investigates a phenomenon where query-based object detectors mispredict at the last decoding stage while predicting correctly at an intermediate stage. We review the training process and attribute the overlooked phenomenon to two limitations: lack of training emphasis and cascading errors from decoding sequence. We design and present Selective Query Recollection (SQR), a simple and effective training strategy for query-based object detectors. It cumulatively collects intermediate queries as decoding stages go deeper and selectively forwards the queries to the downstream stages aside from the sequential structure. Such-wise, SQR places training emphasis on later stages and allows later stages to work with intermediate queries from earlier stages directly. SQR can be easily plugged into various query-based object detectors and significantly enhances their performance while leaving the inference pipeline unchanged. As a result, we apply SQR on Adamixer, DAB-DETR, and Deformable-DETR across various settings (backbone, number of queries, schedule) and consistently brings 1.4-2.8 AP improvement.