 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnitail: Detecting, Reading, and Matching in Retail Scene
Paper and Code

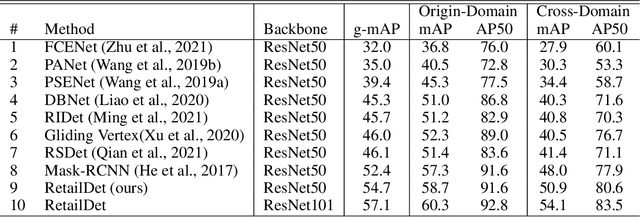
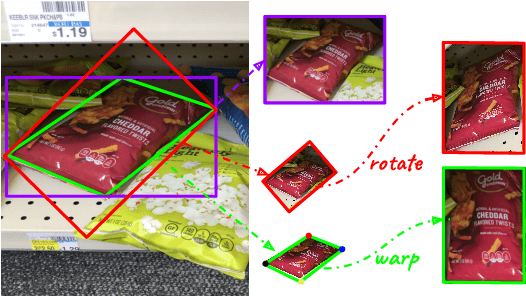
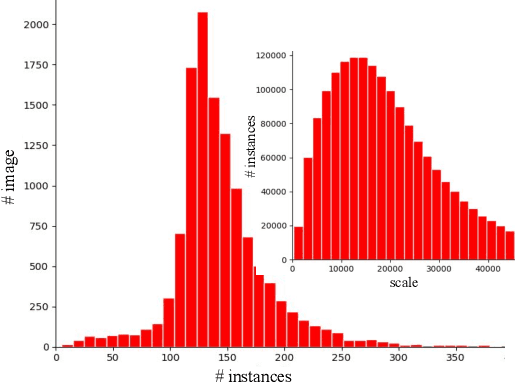
To make full use of computer vision technology in stores, it is required to consider the actual needs that fit the characteristics of the retail scene. Pursuing this goal, we introduce the United Retail Datasets (Unitail), a large-scale benchmark of basic visual tasks on products that challenges algorithms for detecting, reading, and matching. With 1.8M quadrilateral-shaped instances annotated, the Unitail offers a detection dataset to align product appearance better. Furthermore, it provides a gallery-style OCR dataset containing 1454 product categories, 30k text regions, and 21k transcriptions to enable robust reading on products and motivate enhanced product matching. Besides benchmarking the datasets using various state-of-the-arts, we customize a new detector for product detection and provide a simple OCR-based matching solution that verifies its effectiveness.