 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Greener Nights: Exploring AI-Driven Solutions for Light Pollution Management
Apr 15, 2024



This research endeavors to address the pervasive issue of light pollution through an interdisciplinary approach, leveraging data science and machine learning techniques. By analyzing extensive datasets and research findings, we aim to develop predictive models capable of estimating the degree of sky glow observed in various locations and times. Our research seeks to inform evidence-based interventions and promote responsible outdoor lighting practices to mitigate the adverse impacts of light pollution on ecosystems, energy consumption, and human well-being.
Unitail: Detecting, Reading, and Matching in Retail Scene
Apr 01, 2022
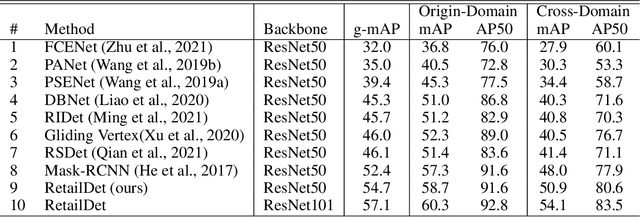
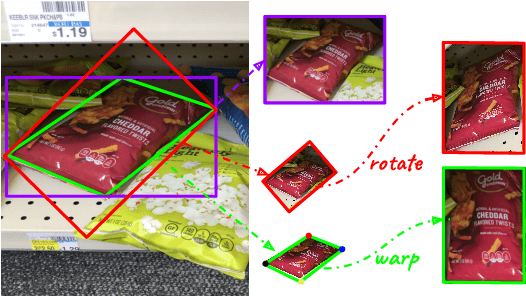
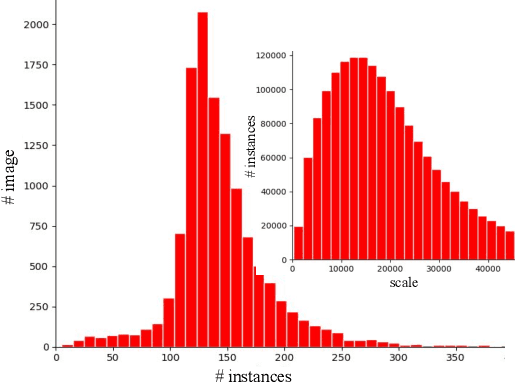
To make full use of computer vision technology in stores, it is required to consider the actual needs that fit the characteristics of the retail scene. Pursuing this goal, we introduce the United Retail Datasets (Unitail), a large-scale benchmark of basic visual tasks on products that challenges algorithms for detecting, reading, and matching. With 1.8M quadrilateral-shaped instances annotated, the Unitail offers a detection dataset to align product appearance better. Furthermore, it provides a gallery-style OCR dataset containing 1454 product categories, 30k text regions, and 21k transcriptions to enable robust reading on products and motivate enhanced product matching. Besides benchmarking the datasets using various state-of-the-arts, we customize a new detector for product detection and provide a simple OCR-based matching solution that verifies its effectiveness.
Semantic Relation Reasoning for Shot-Stable Few-Shot Object Detection
Mar 19, 2021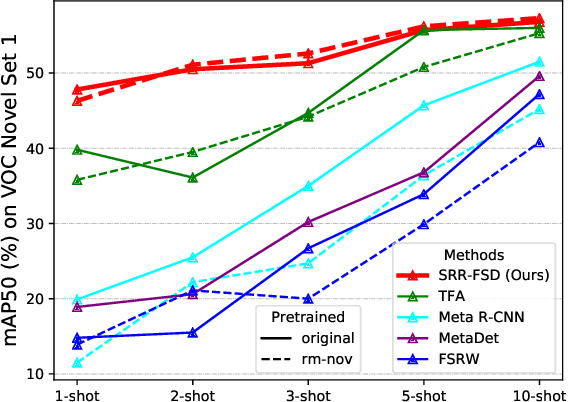
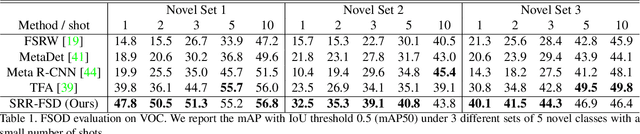


Few-shot object detection is an imperative and long-lasting problem due to the inherent long-tail distribution of real-world data. Its performance is largely affected by the data scarcity of novel classes. But the semantic relation between the novel classes and the base classes is constant regardless of the data availability. In this work, we investigate utilizing this semantic relation together with the visual information and introduce explicit relation reasoning into the learning of novel object detection. Specifically, we represent each class concept by a semantic embedding learned from a large corpus of text. The detector is trained to project the image representations of objects into this embedding space. We also identify the problems of trivially using the raw embeddings with a heuristic knowledge graph and propose to augment the embeddings with a dynamic relation graph. As a result, our few-shot detector, termed SRR-FSD, is robust and stable to the variation of shots of novel objects. Experiments show that SRR-FSD can achieve competitive results at higher shots, and more importantly, a significantly better performance given both lower explicit and implicit shots. The benchmark protocol with implicit shots removed from the pretrained classification dataset can serve as a more realistic setting for future research.
Transfer Learning and Meta Classification Based Deep Churn Prediction System for Telecom Industry
Jan 18, 2019



A churn prediction system guides telecom service providers to reduce revenue loss. Development of a churn prediction system for a telecom industry is a challenging task, mainly due to size of the data, high dimensional features, and imbalanced distribution of the data. In this paper, we focus on a novel solution to the inherent problems of churn prediction, using the concept of Transfer Learning (TL) and Ensemble-based Meta-Classification. The proposed method TL-DeepE is applied in two stages. The first stage employs TL by fine tuning multiple pre-trained Deep Convolution Neural Networks (CNNs). Telecom datasets are in vector form, which is converted into 2D images because Deep CNNs have high learning capacity on images. In the second stage, predictions from these Deep CNNs are appended to the original feature vector and thus are used to build a final feature vector for the high-level Genetic Programming and AdaBoost based ensemble classifier. Thus, the experiments are conducted using various CNNs as base classifiers with the contribution of high-level GP-AdaBoost ensemble classifier, and the results achieved are as an average of the outcomes. By using 10-fold cross-validation, the performance of the proposed TL-DeepE system is compared with existing techniques, for two standard telecommunication datasets; Orange and Cell2cell. In experimental result, the prediction accuracy for Orange and Cell2cell datasets were as 75.4% and 68.2% and a score of the area under the curve as 0.83 and 0.74, respectively.