 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Evaluation of Multiple Sclerosis (MS) Lesion Segmentation Models
May 10, 2026Multiple Sclerosis (MS) is a chronic autoimmune disease that can significantly reduce the quality of life of a patient. Existing treatment options can only help slow down the progression of the disease. Therefore, early detection and precise monitoring of disease progression are important. Deep learning offers state-of-the-art models for detecting and segmenting MS lesions in brain MRI scans. However, most of these models are evaluated using the Dice score, without accounting for lesion-wise detection and segmentation performance or other metrics that quantify model performance in cases that are complex or confusing for human annotators, or in cases that are essential for disease detection and progression monitoring. In this paper, we highlight the need to rethink the evaluation of MS lesion segmentation models. In this context, we first present problem fingerprinting in detail to highlight what neurologists look for in brain MRI scans for MS detection and progression monitoring, and which metrics are required to properly quantify model performance in these contexts. Additionally, we present an analysis of state-of-the-art models on two open-source datasets using these metrics to highlight their usability for real-world deployment in hospitals.
MVB-Grasp: Minimum-Volume-Box Filtering of Diffusion-based Grasps for Frontal Manipulation
May 10, 2026State-of-the-art 6-DoF grasp generators excel on tabletop benchmarks with overhead cameras but struggle in frontal grasping scenarios on low-cost manipulators with constrained workspaces, where kinematic limits and approach-direction constraints cause high failure rates. We address this challenge for the Unitree Z1 arm by proposing MVB-Grasp, a novel grasping stack that injects a Minimum Volume Bounding Box (MVBB) geometric prior into diffusion-based grasp generation to dramatically improve success rates in frontal, workspace-constrained settings. Our key scientific contributions are threefold: (i) an MVBB-based geometric filter that exploits oriented bounding-box face normals to reject grasps approaching through the table or misaligned with accessible object faces in O(N) time; (ii) a combined re-scoring function that blends learned discriminator scores with face-alignment geometry α=0.85, specifically calibrated for the Z1's frontal workspace and kinematic constraints; and (iii) a systematic MuJoCo evaluation protocol measuring grasp success across object types, distances, lateral positions, and pitch orientations to validate embodiment-specific performance. We implement MVB-Grasp on a Unitree Z1 arm with an Intel RealSense D405 camera, integrating YOLOv8 object detection, GraspGen for candidate generation, Principal Component Analysis (PCA)-based MVBB fitting, and inverse-kinematics trajectory planning. Experiments across 81 MuJoCo episodes (cylinder, asymmetric box, waterbottle) demonstrate that MVB-Grasp achieves 59.3% success versus 24.7% for vanilla GraspGen, a 2.4x improvement, by filtering geometrically infeasible candidates and prioritizing face-aligned grasps suited to the Z1's frontal approach constraints. Real-world trials confirm that the MVBB prior substantially improves grasp reliability on constrained, low-cost manipulators without requiring model retraining.
PatchBlock: A Lightweight Defense Against Adversarial Patches for Embedded EdgeAI Devices
Jan 01, 2026Adversarial attacks pose a significant challenge to the reliable deployment of machine learning models in EdgeAI applications, such as autonomous driving and surveillance, which rely on resource-constrained devices for real-time inference. Among these, patch-based adversarial attacks, where small malicious patches (e.g., stickers) are applied to objects, can deceive neural networks into making incorrect predictions with potentially severe consequences. In this paper, we present PatchBlock, a lightweight framework designed to detect and neutralize adversarial patches in images. Leveraging outlier detection and dimensionality reduction, PatchBlock identifies regions affected by adversarial noise and suppresses their impact. It operates as a pre-processing module at the sensor level, efficiently running on CPUs in parallel with GPU inference, thus preserving system throughput while avoiding additional GPU overhead. The framework follows a three-stage pipeline: splitting the input into chunks (Chunking), detecting anomalous regions via a redesigned isolation forest with targeted cuts for faster convergence (Separating), and applying dimensionality reduction on the identified outliers (Mitigating). PatchBlock is both model- and patch-agnostic, can be retrofitted to existing pipelines, and integrates seamlessly between sensor inputs and downstream models. Evaluations across multiple neural architectures, benchmark datasets, attack types, and diverse edge devices demonstrate that PatchBlock consistently improves robustness, recovering up to 77% of model accuracy under strong patch attacks such as the Google Adversarial Patch, while maintaining high portability and minimal clean accuracy loss. Additionally, PatchBlock outperforms the state-of-the-art defenses in efficiency, in terms of computation time and energy consumption per sample, making it suitable for EdgeAI applications.
CognitiveArm: Enabling Real-Time EEG-Controlled Prosthetic Arm Using Embodied Machine Learning
Aug 11, 2025
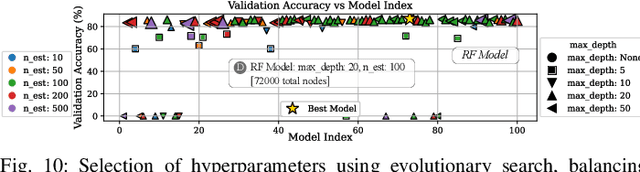
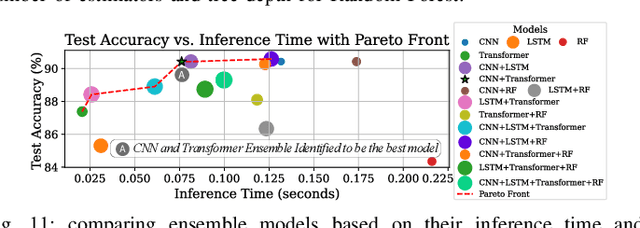

Efficient control of prosthetic limbs via non-invasive brain-computer interfaces (BCIs) requires advanced EEG processing, including pre-filtering, feature extraction, and action prediction, performed in real time on edge AI hardware. Achieving this on resource-constrained devices presents challenges in balancing model complexity, computational efficiency, and latency. We present CognitiveArm, an EEG-driven, brain-controlled prosthetic system implemented on embedded AI hardware, achieving real-time operation without compromising accuracy. The system integrates BrainFlow, an open-source library for EEG data acquisition and streaming, with optimized deep learning (DL) models for precise brain signal classification. Using evolutionary search, we identify Pareto-optimal DL configurations through hyperparameter tuning, optimizer analysis, and window selection, analyzed individually and in ensemble configurations. We apply model compression techniques such as pruning and quantization to optimize models for embedded deployment, balancing efficiency and accuracy. We collected an EEG dataset and designed an annotation pipeline enabling precise labeling of brain signals corresponding to specific intended actions, forming the basis for training our optimized DL models. CognitiveArm also supports voice commands for seamless mode switching, enabling control of the prosthetic arm's 3 degrees of freedom (DoF). Running entirely on embedded hardware, it ensures low latency and real-time responsiveness. A full-scale prototype, interfaced with the OpenBCI UltraCortex Mark IV EEG headset, achieved up to 90% accuracy in classifying three core actions (left, right, idle). Voice integration enables multiplexed, variable movement for everyday tasks (e.g., handshake, cup picking), enhancing real-world performance and demonstrating CognitiveArm's potential for advanced prosthetic control.
NeuGen: Amplifying the 'Neural' in Neural Radiance Fields for Domain Generalization
May 11, 2025Neural Radiance Fields (NeRF) have significantly advanced the field of novel view synthesis, yet their generalization across diverse scenes and conditions remains challenging. Addressing this, we propose the integration of a novel brain-inspired normalization technique Neural Generalization (NeuGen) into leading NeRF architectures which include MVSNeRF and GeoNeRF. NeuGen extracts the domain-invariant features, thereby enhancing the models' generalization capabilities. It can be seamlessly integrated into NeRF architectures and cultivates a comprehensive feature set that significantly improves accuracy and robustness in image rendering. Through this integration, NeuGen shows improved performance on benchmarks on diverse datasets across state-of-the-art NeRF architectures, enabling them to generalize better across varied scenes. Our comprehensive evaluations, both quantitative and qualitative, confirm that our approach not only surpasses existing models in generalizability but also markedly improves rendering quality. Our work exemplifies the potential of merging neuroscientific principles with deep learning frameworks, setting a new precedent for enhanced generalizability and efficiency in novel view synthesis. A demo of our study is available at https://neugennerf.github.io.
PennyLang: Pioneering LLM-Based Quantum Code Generation with a Novel PennyLane-Centric Dataset
Mar 04, 2025Large Language Models (LLMs) offer remarkable capabilities in code generation, natural language processing, and domain-specific reasoning. Their potential in aiding quantum software development remains underexplored, particularly for the PennyLane framework-a leading platform for hybrid quantum-classical computing. To address this gap, we introduce a novel, high-quality dataset comprising 3,347 PennyLane-specific code samples of quantum circuits and their contextual descriptions, specifically curated to train/fine-tune LLM-based quantum code assistance. Our key contributions are threefold: (1) the automatic creation and open-source release of a comprehensive PennyLane dataset leveraging quantum computing textbooks, official documentation, and open-source repositories; (2) the development of a systematic methodology for data refinement, annotation, and formatting to optimize LLM training efficiency; and (3) a thorough evaluation, based on a Retrieval-Augmented Generation (RAG) framework, demonstrating the effectiveness of our dataset in streamlining PennyLane code generation and improving quantum development workflows. Compared to existing efforts that predominantly focus on Qiskit, our dataset significantly broadens the spectrum of quantum frameworks covered in AI-driven code assistance. By bridging this gap and providing reproducible dataset-creation methodologies, we aim to advance the field of AI-assisted quantum programming, making quantum computing more accessible to both newcomers and experienced developers.
Survey of different Large Language Model Architectures: Trends, Benchmarks, and Challenges
Dec 04, 2024

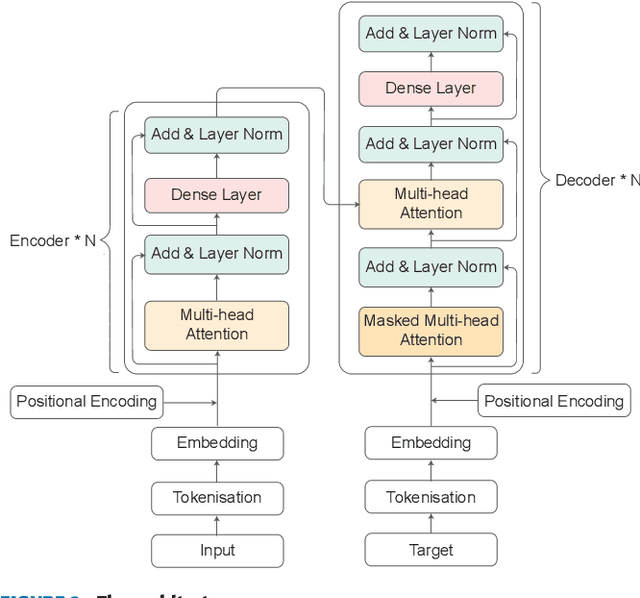

Large Language Models (LLMs) represent a class of deep learning models adept at understanding natural language and generating coherent responses to various prompts or queries. These models far exceed the complexity of conventional neural networks, often encompassing dozens of neural network layers and containing billions to trillions of parameters. They are typically trained on vast datasets, utilizing architectures based on transformer blocks. Present-day LLMs are multi-functional, capable of performing a range of tasks from text generation and language translation to question answering, as well as code generation and analysis. An advanced subset of these models, known as Multimodal Large Language Models (MLLMs), extends LLM capabilities to process and interpret multiple data modalities, including images, audio, and video. This enhancement empowers MLLMs with capabilities like video editing, image comprehension, and captioning for visual content. This survey provides a comprehensive overview of the recent advancements in LLMs. We begin by tracing the evolution of LLMs and subsequently delve into the advent and nuances of MLLMs. We analyze emerging state-of-the-art MLLMs, exploring their technical features, strengths, and limitations. Additionally, we present a comparative analysis of these models and discuss their challenges, potential limitations, and prospects for future development.
MindArm: Mechanized Intelligent Non-Invasive Neuro-Driven Prosthetic Arm System
Mar 29, 2024Currently, people with disability or difficulty to move their arms (referred to as "patients") have very limited technological solutions to efficiently address their physiological limitations. It is mainly due to two reasons: (1) the non-invasive solutions like mind-controlled prosthetic devices are typically very costly and require expensive maintenance; and (2) other solutions require costly invasive brain surgery, which is high risk to perform, expensive, and difficult to maintain. Therefore, current technological solutions are not accessible for all patients with different financial backgrounds. Toward this, we propose a low-cost technological solution called MindArm, a mechanized intelligent non-invasive neuro-driven prosthetic arm system. Our MindArm system employs a deep neural network (DNN) engine to translate brain signals into the intended prosthetic arm motion, thereby helping patients to perform many activities despite their physiological limitations. Here, our MindArm system utilizes widely accessible and low-cost surface electroencephalogram (EEG) electrodes coupled with an Open Brain Computer Interface and UDP networking for acquiring brain signals and transmitting them to the compute module for signal processing. In the compute module, we run a trained DNN model to interpret normalized micro-voltage of the brain signals, and then translate them into a prosthetic arm action via serial communication seamlessly. The experimental results on a fully working prototype demonstrate that, from the three defined actions, our MindArm system achieves positive success rates, i.e., 91\% for idle/stationary, 85\% for shake hand, and 84\% for pick-up cup. This demonstrates that our MindArm provides a novel approach for an alternate low-cost mind-controlled prosthetic devices for all patients.
Borrowing Treasures from Neighbors: In-Context Learning for Multimodal Learning with Missing Modalities and Data Scarcity
Mar 26, 2024Multimodal machine learning with missing modalities is an increasingly relevant challenge arising in various applications such as healthcare. This paper extends the current research into missing modalities to the low-data regime, i.e., a downstream task has both missing modalities and limited sample size issues. This problem setting is particularly challenging and also practical as it is often expensive to get full-modality data and sufficient annotated training samples. We propose to use retrieval-augmented in-context learning to address these two crucial issues by unleashing the potential of a transformer's in-context learning ability. Diverging from existing methods, which primarily belong to the parametric paradigm and often require sufficient training samples, our work exploits the value of the available full-modality data, offering a novel perspective on resolving the challenge. The proposed data-dependent framework exhibits a higher degree of sample efficiency and is empirically demonstrated to enhance the classification model's performance on both full- and missing-modality data in the low-data regime across various multimodal learning tasks. When only 1% of the training data are available, our proposed method demonstrates an average improvement of 6.1% over a recent strong baseline across various datasets and missing states. Notably, our method also reduces the performance gap between full-modality and missing-modality data compared with the baseline.
MedAide: Leveraging Large Language Models for On-Premise Medical Assistance on Edge Devices
Feb 28, 2024Large language models (LLMs) are revolutionizing various domains with their remarkable natural language processing (NLP) abilities. However, deploying LLMs in resource-constrained edge computing and embedded systems presents significant challenges. Another challenge lies in delivering medical assistance in remote areas with limited healthcare facilities and infrastructure. To address this, we introduce MedAide, an on-premise healthcare chatbot. It leverages tiny-LLMs integrated with LangChain, providing efficient edge-based preliminary medical diagnostics and support. MedAide employs model optimizations for minimal memory footprint and latency on embedded edge devices without server infrastructure. The training process is optimized using low-rank adaptation (LoRA). Additionally, the model is trained on diverse medical datasets, employing reinforcement learning from human feedback (RLHF) to enhance its domain-specific capabilities. The system is implemented on various consumer GPUs and Nvidia Jetson development board. MedAide achieves 77\% accuracy in medical consultations and scores 56 in USMLE benchmark, enabling an energy-efficient healthcare assistance platform that alleviates privacy concerns due to edge-based deployment, thereby empowering the community.