 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt-Based Continual Compositional Zero-Shot Learning
Dec 17, 2025We tackle continual adaptation of vision-language models to new attributes, objects, and their compositions in Compositional Zero-Shot Learning (CZSL), while preventing forgetting of prior knowledge. Unlike classical continual learning where classes are disjoint, CCZSL is more complex as attributes and objects may reoccur across sessions while compositions remain unique. Built on a frozen VLM backbone, we propose the first Prompt-based Continual Compositional Zero-Shot Learning (PromptCCZSL) framework that retains prior knowledge through recency-weighted multi-teacher distillation. It employs session-aware compositional prompts to fuse multimodal features for new compositions, while attribute and object prompts are learned through session-agnostic fusion to maintain global semantic consistency, which is further stabilized by a Cosine Anchor Loss (CAL) to preserve prior knowledge. To enhance adaptation in the current session, an Orthogonal Projection Loss (OPL) ensures that new attribute and object embeddings remain distinct from previous ones, preventing overlap, while an Intra-Session Diversity Loss (IDL) promotes variation among current-session embeddings for richer, more discriminative representations. We also introduce a comprehensive protocol that jointly measures catastrophic forgetting and compositional generalization. Extensive experiments on UT-Zappos and C-GQA benchmarks demonstrate that PromptCCZSL achieves substantial improvements over prior VLM-based and non-VLM baselines, setting a new benchmark for CCZSL in closed-world settings.
Uni-Hema: Unified Model for Digital Hematopathology
Nov 19, 2025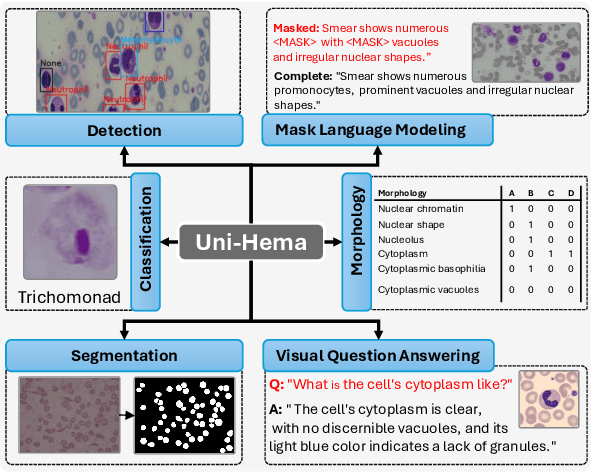
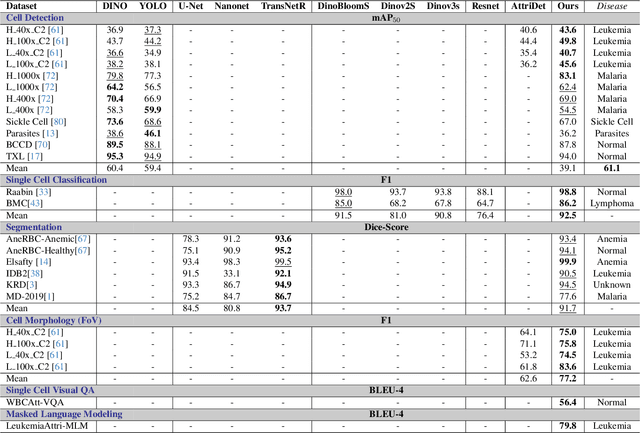
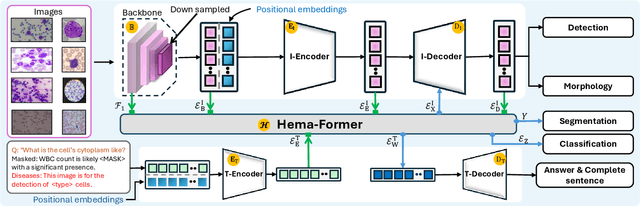
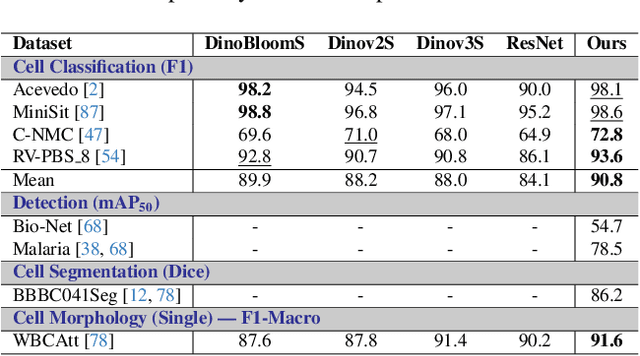
Digital hematopathology requires cell-level analysis across diverse disease categories, including malignant disorders (e.g., leukemia), infectious conditions (e.g., malaria), and non-malignant red blood cell disorders (e.g., sickle cell disease). Whether single-task, vision-language, WSI-optimized, or single-cell hematology models, these approaches share a key limitation, they cannot provide unified, multi-task, multi-modal reasoning across the complexities of digital hematopathology. To overcome these limitations, we propose Uni-Hema, a multi-task, unified model for digital hematopathology integrating detection, classification, segmentation, morphology prediction, and reasoning across multiple diseases. Uni-Hema leverages 46 publicly available datasets, encompassing over 700K images and 21K question-answer pairs, and is built upon Hema-Former, a multimodal module that bridges visual and textual representations at the hierarchy level for the different tasks (detection, classification, segmentation, morphology, mask language modeling and visual question answer) at different granularity. Extensive experiments demonstrate that Uni-Hema achieves comparable or superior performance to train on a single-task and single dataset models, across diverse hematological tasks, while providing interpretable, morphologically relevant insights at the single-cell level. Our framework establishes a new standard for multi-task and multi-modal digital hematopathology. The code will be made publicly available.
Leveraging Sparse Annotations for Leukemia Diagnosis on the Large Leukemia Dataset
Apr 03, 2025Leukemia is 10th most frequently diagnosed cancer and one of the leading causes of cancer related deaths worldwide. Realistic analysis of Leukemia requires White Blook Cells (WBC) localization, classification, and morphological assessment. Despite deep learning advances in medical imaging, leukemia analysis lacks a large, diverse multi-task dataset, while existing small datasets lack domain diversity, limiting real world applicability. To overcome dataset challenges, we present a large scale WBC dataset named Large Leukemia Dataset (LLD) and novel methods for detecting WBC with their attributes. Our contribution here is threefold. First, we present a large-scale Leukemia dataset collected through Peripheral Blood Films (PBF) from several patients, through multiple microscopes, multi cameras, and multi magnification. To enhance diagnosis explainability and medical expert acceptance, each leukemia cell is annotated at 100x with 7 morphological attributes, ranging from Cell Size to Nuclear Shape. Secondly, we propose a multi task model that not only detects WBCs but also predicts their attributes, providing an interpretable and clinically meaningful solution. Third, we propose a method for WBC detection with attribute analysis using sparse annotations. This approach reduces the annotation burden on hematologists, requiring them to mark only a small area within the field of view. Our method enables the model to leverage the entire field of view rather than just the annotated regions, enhancing learning efficiency and diagnostic accuracy. From diagnosis explainability to overcoming domain shift challenges, presented datasets could be used for many challenging aspects of microscopic image analysis. The datasets, code, and demo are available at: https://im.itu.edu.pk/sparse-leukemiaattri/
TLAC: Two-stage LMM Augmented CLIP for Zero-Shot Classification
Mar 15, 2025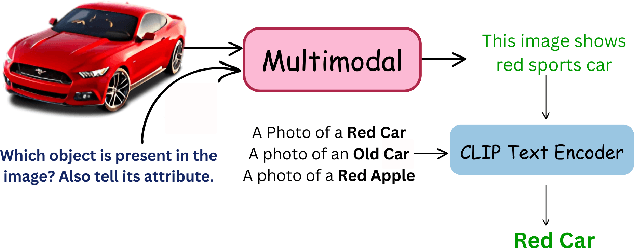
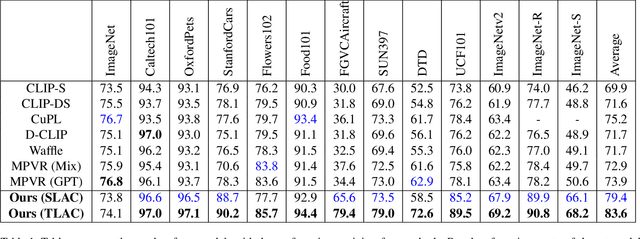
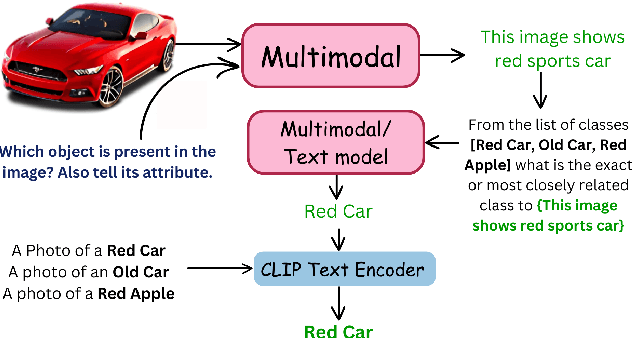
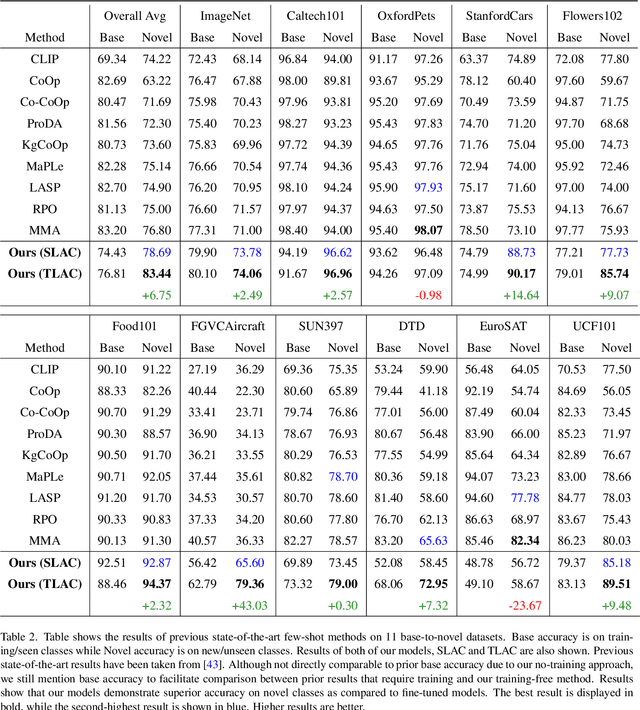
Contrastive Language-Image Pretraining (CLIP) has shown impressive zero-shot performance on image classification. However, state-of-the-art methods often rely on fine-tuning techniques like prompt learning and adapter-based tuning to optimize CLIP's performance. The necessity for fine-tuning significantly limits CLIP's adaptability to novel datasets and domains. This requirement mandates substantial time and computational resources for each new dataset. To overcome this limitation, we introduce simple yet effective training-free approaches, Single-stage LMM Augmented CLIP (SLAC) and Two-stage LMM Augmented CLIP (TLAC), that leverages powerful Large Multimodal Models (LMMs), such as Gemini, for image classification. The proposed methods leverages the capabilities of pre-trained LMMs, allowing for seamless adaptation to diverse datasets and domains without the need for additional training. Our approaches involve prompting the LMM to identify objects within an image. Subsequently, the CLIP text encoder determines the image class by identifying the dataset class with the highest semantic similarity to the LLM predicted object. We evaluated our models on 11 base-to-novel datasets and they achieved superior accuracy on 9 of these, including benchmarks like ImageNet, SUN397 and Caltech101, while maintaining a strictly training-free paradigm. Our overall accuracy of 83.44% surpasses the previous state-of-the-art few-shot methods by a margin of 6.75%. Our method achieved 83.6% average accuracy across 13 datasets, a 9.7% improvement over the previous 73.9% state-of-the-art for training-free approaches. Our method improves domain generalization, with a 3.6% gain on ImageNetV2, 16.96% on ImageNet-S, and 12.59% on ImageNet-R, over prior few-shot methods.
MIAdapt: Source-free Few-shot Domain Adaptive Object Detection for Microscopic Images
Mar 05, 2025Existing generic unsupervised domain adaptation approaches require access to both a large labeled source dataset and a sufficient unlabeled target dataset during adaptation. However, collecting a large dataset, even if unlabeled, is a challenging and expensive endeavor, especially in medical imaging. In addition, constraints such as privacy issues can result in cases where source data is unavailable. Taking in consideration these challenges, we propose MIAdapt, an adaptive approach for Microscopic Imagery Adaptation as a solution for Source-free Few-shot Domain Adaptive Object detection (SF-FSDA). We also define two competitive baselines (1) Faster-FreeShot and (2) MT-FreeShot. Extensive experiments on the challenging M5-Malaria and Raabin-WBC datasets validate the effectiveness of MIAdapt. Without using any image from the source domain MIAdapt surpasses state-of-the-art source-free UDA (SF-UDA) methods by +21.3% mAP and few-shot domain adaptation (FSDA) approaches by +4.7% mAP on Raabin-WBC. Our code and models will be publicly available.
Attention Based Simple Primitives for Open World Compositional Zero-Shot Learning
Jul 18, 2024



Compositional Zero-Shot Learning (CZSL) aims to predict unknown compositions made up of attribute and object pairs. Predicting compositions unseen during training is a challenging task. We are exploring Open World Compositional Zero-Shot Learning (OW-CZSL) in this study, where our test space encompasses all potential combinations of attributes and objects. Our approach involves utilizing the self-attention mechanism between attributes and objects to achieve better generalization from seen to unseen compositions. Utilizing a self-attention mechanism facilitates the model's ability to identify relationships between attribute and objects. The similarity between the self-attended textual and visual features is subsequently calculated to generate predictions during the inference phase. The potential test space may encompass implausible object-attribute combinations arising from unrestricted attribute-object pairings. To mitigate this issue, we leverage external knowledge from ConceptNet to restrict the test space to realistic compositions. Our proposed model, Attention-based Simple Primitives (ASP), demonstrates competitive performance, achieving results comparable to the state-of-the-art.
Few-Shot Domain Adaptive Object Detection for Microscopic Images
Jul 10, 2024
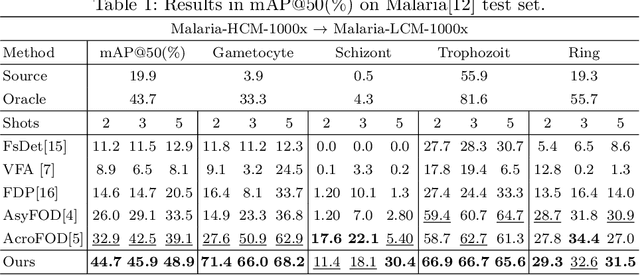

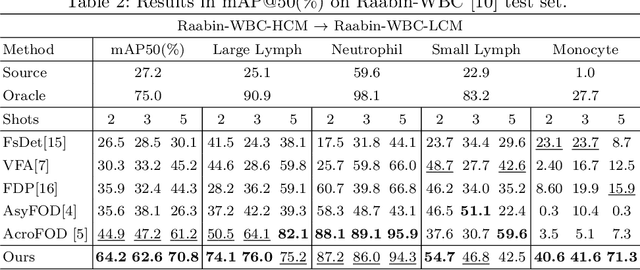
In recent years, numerous domain adaptive strategies have been proposed to help deep learning models overcome the challenges posed by domain shift. However, even unsupervised domain adaptive strategies still require a large amount of target data. Medical imaging datasets are often characterized by class imbalance and scarcity of labeled and unlabeled data. Few-shot domain adaptive object detection (FSDAOD) addresses the challenge of adapting object detectors to target domains with limited labeled data. Existing works struggle with randomly selected target domain images that may not accurately represent the real population, resulting in overfitting to small validation sets and poor generalization to larger test sets. Medical datasets exhibit high class imbalance and background similarity, leading to increased false positives and lower mean Average Precision (map) in target domains. To overcome these challenges, we propose a novel FSDAOD strategy for microscopic imaging. Our contributions include a domain adaptive class balancing strategy for few-shot scenarios, multi-layer instance-level inter and intra-domain alignment to enhance similarity between class instances regardless of domain, and an instance-level classification loss applied in the middle layers of the object detector to enforce feature retention necessary for correct classification across domains. Extensive experimental results with competitive baselines demonstrate the effectiveness of our approach, achieving state-of-the-art results on two public microscopic datasets. Code available at https://github.co/intelligentMachinesLab/few-shot-domain-adaptive-microscopy
Improving Single Domain-Generalized Object Detection: A Focus on Diversification and Alignment
May 23, 2024



In this work, we tackle the problem of domain generalization for object detection, specifically focusing on the scenario where only a single source domain is available. We propose an effective approach that involves two key steps: diversifying the source domain and aligning detections based on class prediction confidence and localization. Firstly, we demonstrate that by carefully selecting a set of augmentations, a base detector can outperform existing methods for single domain generalization by a good margin. This highlights the importance of domain diversification in improving the performance of object detectors. Secondly, we introduce a method to align detections from multiple views, considering both classification and localization outputs. This alignment procedure leads to better generalized and well-calibrated object detector models, which are crucial for accurate decision-making in safety-critical applications. Our approach is detector-agnostic and can be seamlessly applied to both single-stage and two-stage detectors. To validate the effectiveness of our proposed methods, we conduct extensive experiments and ablations on challenging domain-shift scenarios. The results consistently demonstrate the superiority of our approach compared to existing methods. Our code and models are available at: https://github.com/msohaildanish/DivAlign
A Large-scale Multi Domain Leukemia Dataset for the White Blood Cells Detection with Morphological Attributes for Explainability
May 17, 2024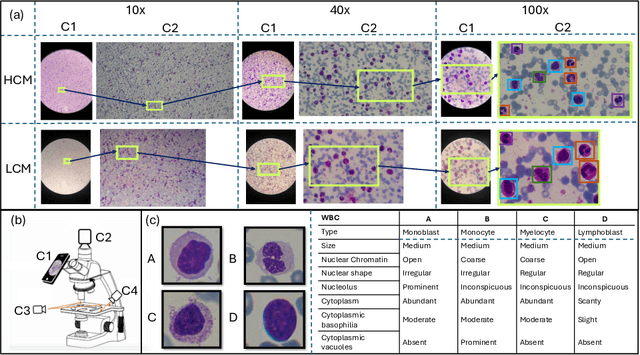
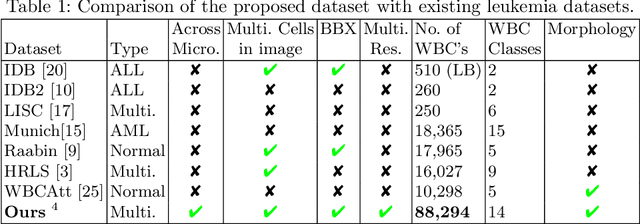
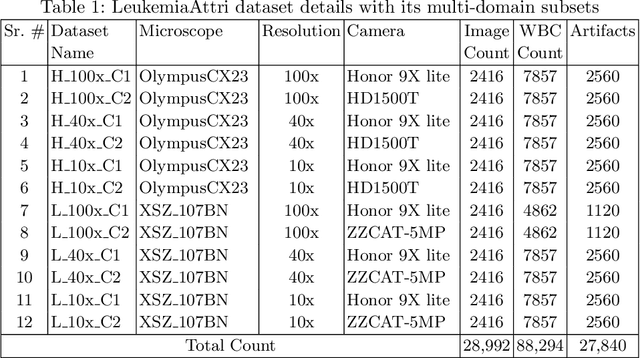
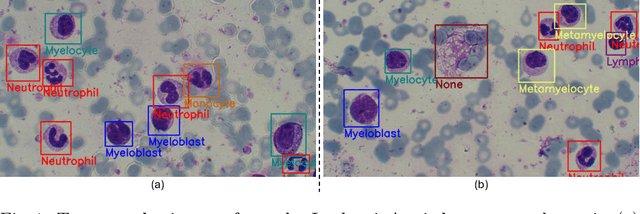
Earlier diagnosis of Leukemia can save thousands of lives annually. The prognosis of leukemia is challenging without the morphological information of White Blood Cells (WBC) and relies on the accessibility of expensive microscopes and the availability of hematologists to analyze Peripheral Blood Samples (PBS). Deep Learning based methods can be employed to assist hematologists. However, these algorithms require a large amount of labeled data, which is not readily available. To overcome this limitation, we have acquired a realistic, generalized, and large dataset. To collect this comprehensive dataset for real-world applications, two microscopes from two different cost spectrums (high-cost HCM and low-cost LCM) are used for dataset capturing at three magnifications (100x, 40x, 10x) through different sensors (high-end camera for HCM, middle-level camera for LCM and mobile-phone camera for both). The high-sensor camera is 47 times more expensive than the middle-level camera and HCM is 17 times more expensive than LCM. In this collection, using HCM at high resolution (100x), experienced hematologists annotated 10.3k WBC types (14) and artifacts, having 55k morphological labels (Cell Size, Nuclear Chromatin, Nuclear Shape, etc.) from 2.4k images of several PBS leukemia patients. Later on, these annotations are transferred to other 2 magnifications of HCM, and 3 magnifications of LCM, and on each camera captured images. Along with the LeukemiaAttri dataset, we provide baselines over multiple object detectors and Unsupervised Domain Adaptation (UDA) strategies, along with morphological information-based attribute prediction. The dataset will be publicly available after publication to facilitate the research in this direction.
Domain Adaptive Object Detection via Balancing Between Self-Training and Adversarial Learning
Nov 08, 2023Deep learning based object detectors struggle generalizing to a new target domain bearing significant variations in object and background. Most current methods align domains by using image or instance-level adversarial feature alignment. This often suffers due to unwanted background and lacks class-specific alignment. A straightforward approach to promote class-level alignment is to use high confidence predictions on unlabeled domain as pseudo-labels. These predictions are often noisy since model is poorly calibrated under domain shift. In this paper, we propose to leverage model's predictive uncertainty to strike the right balance between adversarial feature alignment and class-level alignment. We develop a technique to quantify predictive uncertainty on class assignments and bounding-box predictions. Model predictions with low uncertainty are used to generate pseudo-labels for self-training, whereas the ones with higher uncertainty are used to generate tiles for adversarial feature alignment. This synergy between tiling around uncertain object regions and generating pseudo-labels from highly certain object regions allows capturing both image and instance-level context during the model adaptation. We report thorough ablation study to reveal the impact of different components in our approach. Results on five diverse and challenging adaptation scenarios show that our approach outperforms existing state-of-the-art methods with noticeable margins.