 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIAdapt: Source-free Few-shot Domain Adaptive Object Detection for Microscopic Images
Mar 05, 2025Existing generic unsupervised domain adaptation approaches require access to both a large labeled source dataset and a sufficient unlabeled target dataset during adaptation. However, collecting a large dataset, even if unlabeled, is a challenging and expensive endeavor, especially in medical imaging. In addition, constraints such as privacy issues can result in cases where source data is unavailable. Taking in consideration these challenges, we propose MIAdapt, an adaptive approach for Microscopic Imagery Adaptation as a solution for Source-free Few-shot Domain Adaptive Object detection (SF-FSDA). We also define two competitive baselines (1) Faster-FreeShot and (2) MT-FreeShot. Extensive experiments on the challenging M5-Malaria and Raabin-WBC datasets validate the effectiveness of MIAdapt. Without using any image from the source domain MIAdapt surpasses state-of-the-art source-free UDA (SF-UDA) methods by +21.3% mAP and few-shot domain adaptation (FSDA) approaches by +4.7% mAP on Raabin-WBC. Our code and models will be publicly available.
Leveraging Topology for Domain Adaptive Road Segmentation in Satellite and Aerial Imagery
Sep 27, 2023Getting precise aspects of road through segmentation from remote sensing imagery is useful for many real-world applications such as autonomous vehicles, urban development and planning, and achieving sustainable development goals. Roads are only a small part of the image, and their appearance, type, width, elevation, directions, etc. exhibit large variations across geographical areas. Furthermore, due to differences in urbanization styles, planning, and the natural environments; regions along the roads vary significantly. Due to these variations among the train and test domains, the road segmentation algorithms fail to generalize to new geographical locations. Unlike the generic domain alignment scenarios, road segmentation has no scene structure, and generic domain adaptation methods are unable to enforce topological properties like continuity, connectivity, smoothness, etc., thus resulting in degraded domain alignment. In this work, we propose a topology-aware unsupervised domain adaptation approach for road segmentation in remote sensing imagery. Specifically, we predict road skeleton, an auxiliary task to impose the topological constraints. To enforce consistent predictions of road and skeleton, especially in the unlabeled target domain, the conformity loss is defined across the skeleton prediction head and the road-segmentation head. Furthermore, for self-training, we filter out the noisy pseudo-labels by using a connectivity-based pseudo-labels refinement strategy, on both road and skeleton segmentation heads, thus avoiding holes and discontinuities. Extensive experiments on the benchmark datasets show the effectiveness of the proposed approach compared to existing state-of-the-art methods. Specifically, for SpaceNet to DeepGlobe adaptation, the proposed approach outperforms the competing methods by a minimum margin of 6.6%, 6.7%, and 9.8% in IoU, F1-score, and APLS, respectively.
Distribution Regularized Self-Supervised Learning for Domain Adaptation of Semantic Segmentation
Jun 20, 2022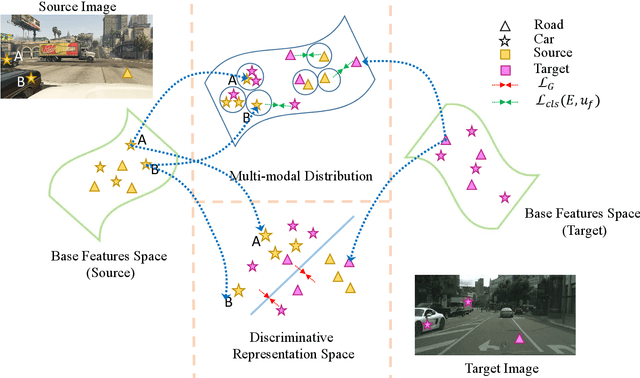
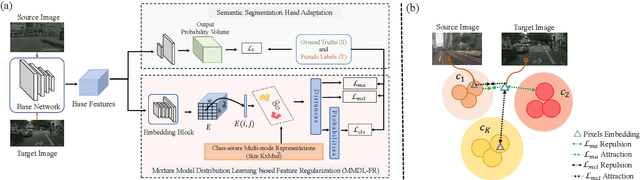
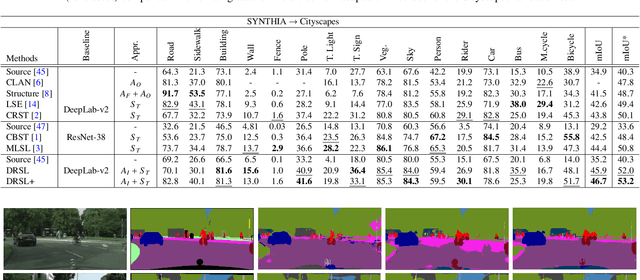
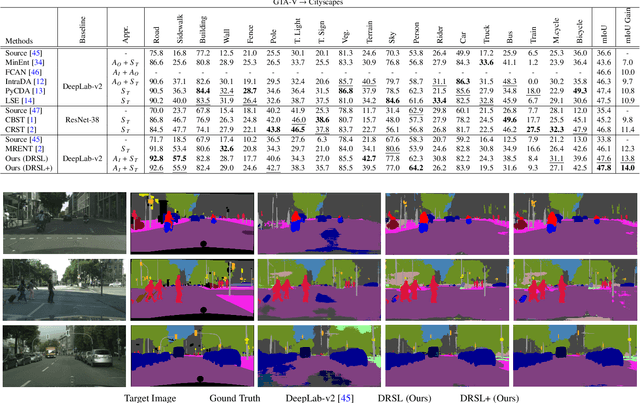
This paper proposes a novel pixel-level distribution regularization scheme (DRSL) for self-supervised domain adaptation of semantic segmentation. In a typical setting, the classification loss forces the semantic segmentation model to greedily learn the representations that capture inter-class variations in order to determine the decision (class) boundary. Due to the domain shift, this decision boundary is unaligned in the target domain, resulting in noisy pseudo labels adversely affecting self-supervised domain adaptation. To overcome this limitation, along with capturing inter-class variation, we capture pixel-level intra-class variations through class-aware multi-modal distribution learning (MMDL). Thus, the information necessary for capturing the intra-class variations is explicitly disentangled from the information necessary for inter-class discrimination. Features captured thus are much more informative, resulting in pseudo-labels with low noise. This disentanglement allows us to perform separate alignments in discriminative space and multi-modal distribution space, using cross-entropy based self-learning for the former. For later, we propose a novel stochastic mode alignment method, by explicitly decreasing the distance between the target and source pixels that map to the same mode. The distance metric learning loss, computed over pseudo-labels and backpropagated from multi-modal modeling head, acts as the regularizer over the base network shared with the segmentation head. The results from comprehensive experiments on synthetic to real domain adaptation setups, i.e., GTA-V/SYNTHIA to Cityscapes, show that DRSL outperforms many existing approaches (a minimum margin of 2.3% and 2.5% in mIoU for SYNTHIA to Cityscapes).
Combining Scale-Invariance and Uncertainty for Self-Supervised Domain Adaptation of Foggy Scenes Segmentation
Jan 17, 2022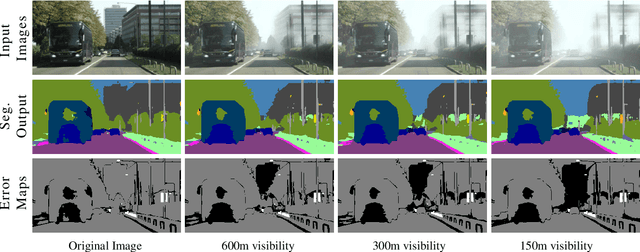

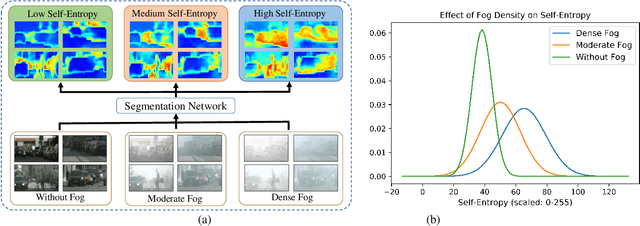
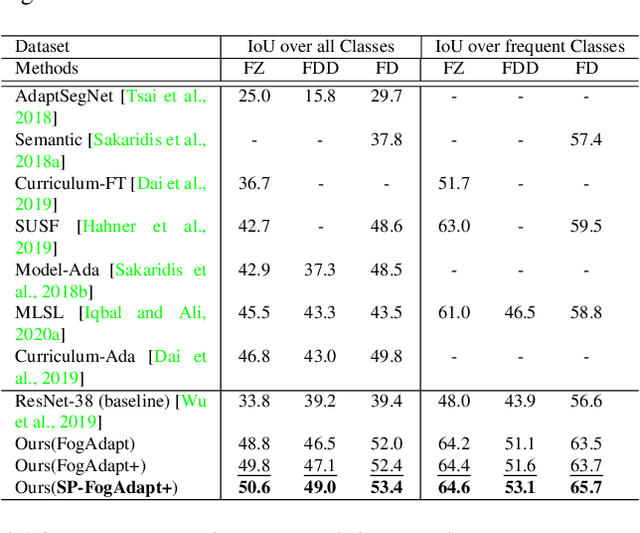
This paper presents FogAdapt, a novel approach for domain adaptation of semantic segmentation for dense foggy scenes. Although significant research has been directed to reduce the domain shift in semantic segmentation, adaptation to scenes with adverse weather conditions remains an open question. Large variations in the visibility of the scene due to weather conditions, such as fog, smog, and haze, exacerbate the domain shift, thus making unsupervised adaptation in such scenarios challenging. We propose a self-entropy and multi-scale information augmented self-supervised domain adaptation method (FogAdapt) to minimize the domain shift in foggy scenes segmentation. Supported by the empirical evidence that an increase in fog density results in high self-entropy for segmentation probabilities, we introduce a self-entropy based loss function to guide the adaptation method. Furthermore, inferences obtained at different image scales are combined and weighted by the uncertainty to generate scale-invariant pseudo-labels for the target domain. These scale-invariant pseudo-labels are robust to visibility and scale variations. We evaluate the proposed model on real clear-weather scenes to real foggy scenes adaptation and synthetic non-foggy images to real foggy scenes adaptation scenarios. Our experiments demonstrate that FogAdapt significantly outperforms the current state-of-the-art in semantic segmentation of foggy images. Specifically, by considering the standard settings compared to state-of-the-art (SOTA) methods, FogAdapt gains 3.8% on Foggy Zurich, 6.0% on Foggy Driving-dense, and 3.6% on Foggy Driving in mIoU when adapted from Cityscapes to Foggy Zurich.
Weakly Supervised Domain Adaptation for Built-up Region Segmentation in Aerial and Satellite Imagery
Jul 05, 2020
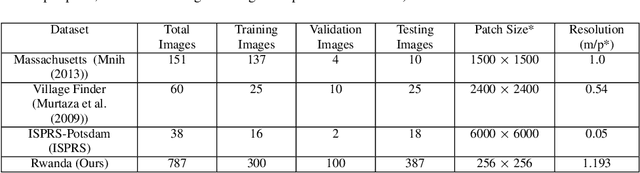


This paper proposes a novel domain adaptation algorithm to handle the challenges posed by the satellite and aerial imagery, and demonstrates its effectiveness on the built-up region segmentation problem. Built-up area estimation is an important component in understanding the human impact on the environment, the effect of public policy, and general urban population analysis. The diverse nature of aerial and satellite imagery and lack of labeled data covering this diversity makes machine learning algorithms difficult to generalize for such tasks, especially across multiple domains. On the other hand, due to the lack of strong spatial context and structure, in comparison to the ground imagery, the application of existing unsupervised domain adaptation methods results in the sub-optimal adaptation. We thoroughly study the limitations of existing domain adaptation methods and propose a weakly-supervised adaptation strategy where we assume image-level labels are available for the target domain. More specifically, we design a built-up area segmentation network (as encoder-decoder), with an image classification head added to guide the adaptation. The devised system is able to address the problem of visual differences in multiple satellite and aerial imagery datasets, ranging from high resolution (HR) to very high resolution (VHR). A realistic and challenging HR dataset is created by hand-tagging the 73.4 sq-km of Rwanda, capturing a variety of build-up structures over different terrain. The developed dataset is spatially rich compared to existing datasets and covers diverse built-up scenarios including built-up areas in forests and deserts, mud houses, tin, and colored rooftops. Extensive experiments are performed by adapting from the single-source domain, to segment out the target domain. We achieve high gains ranging 11.6%-52% in IoU over the existing state-of-the-art methods.
MLSL: Multi-Level Self-Supervised Learning for Domain Adaptation with Spatially Independent and Semantically Consistent Labeling
Sep 30, 2019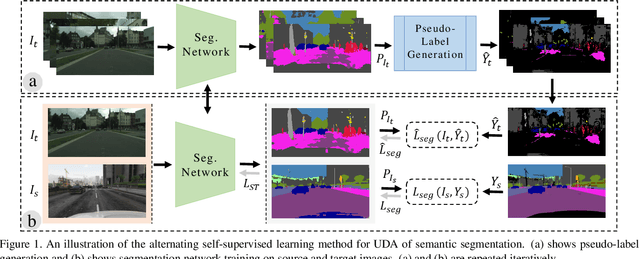
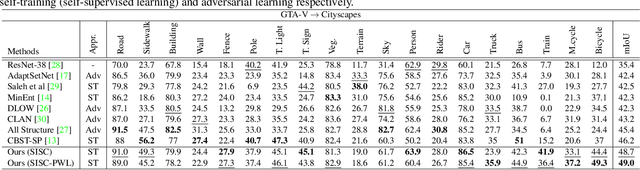
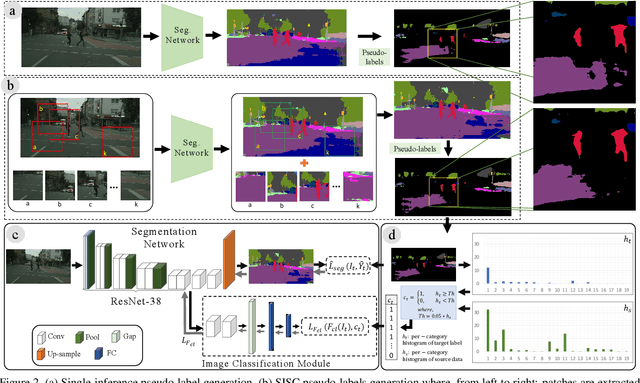
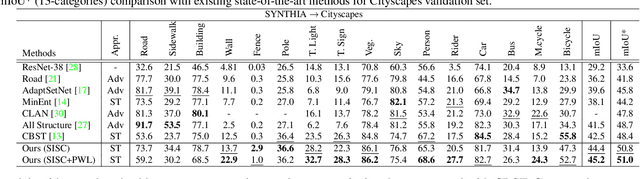
Most of the recent Deep Semantic Segmentation algorithms suffer from large generalization errors, even when powerful hierarchical representation models based on convolutional neural networks have been employed. This could be attributed to limited training data and large distribution gap in train and test domain datasets. In this paper, we propose a multi-level self-supervised learning model for domain adaptation of semantic segmentation. Exploiting the idea that an object (and most of the stuff given context) should be labeled consistently regardless of its location, we generate spatially independent and semantically consistent (SISC) pseudo-labels by segmenting multiple sub-images using base model and designing an aggregation strategy. Image level pseudo weak-labels, PWL, are computed to guide domain adaptation by capturing global context similarity in source and domain at latent space level. Thus helping latent space learn the representation even when there are very few pixels belonging to the domain category (small object for example) compared to rest of the image. Our multi-level Self-supervised learning (MLSL) outperforms existing state-of art (self or adversarial learning) algorithms. Specifically, keeping all setting similar and employing MLSL we obtain an mIoU gain of 5:1% on GTA-V to Cityscapes adaptation and 4:3% on SYNTHIA to Cityscapes adaptation compared to existing state-of-art method.
Orientation Aware Object Detection with Application to Firearms
Apr 22, 2019


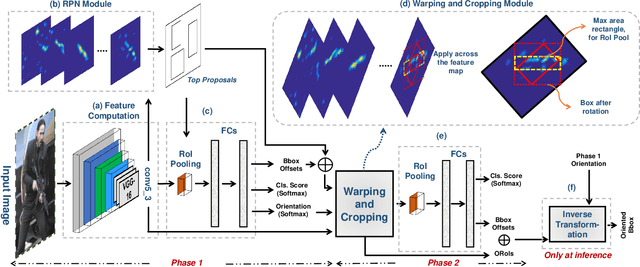
Automatic detection of firearms is important for enhancing security and safety of people, however, it is a challenging task owing to the wide variations in shape, size and appearance of firearms. To handle these challenges we propose an Orientation Aware Object Detector (OAOD) which has achieved improved firearm detection and localization performance. The proposed detector has two phases. In the Phase-1 it predicts orientation of the object which is used to rotate the object proposal. Maximum area rectangles are cropped from the rotated object proposals which are again classified and localized in the Phase-2 of the algorithm. The oriented object proposals are mapped back to the original coordinates resulting in oriented bounding boxes which localize the weapons much better than the axis aligned bounding boxes. Being orientation aware, our non-maximum suppression is able to avoid multiple detection of the same object and it can better resolve objects which lie in close proximity to each other. This two phase system leverages OAOD to predict object oriented bounding boxes while being trained only on the axis aligned boxes in the ground-truth. In order to train object detectors for firearm detection, a dataset consisting of around eleven thousand firearm images is collected from the internet and manually annotated. The proposed ITU Firearm (ITUF) dataset contains wide range of guns and rifles. The OAOD algorithm is evaluated on the ITUF dataset and compared with current state of the art object detectors. Our experiments demonstrate the excellent performance of the proposed detector for the task of firearm detection.