 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality Scalable Quantization Methodology for Deep Learning on Edge
Jul 15, 2024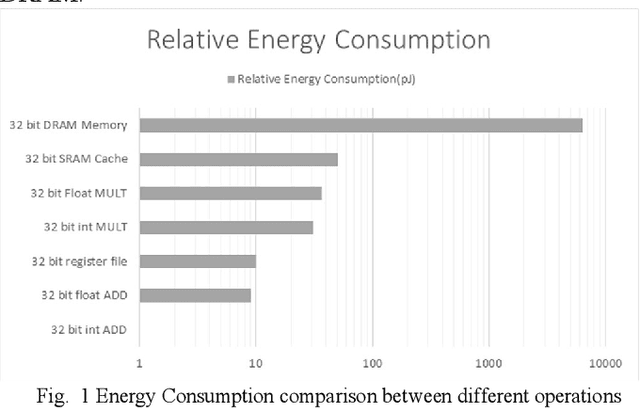
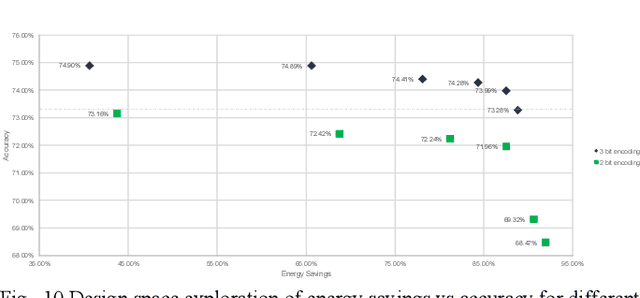
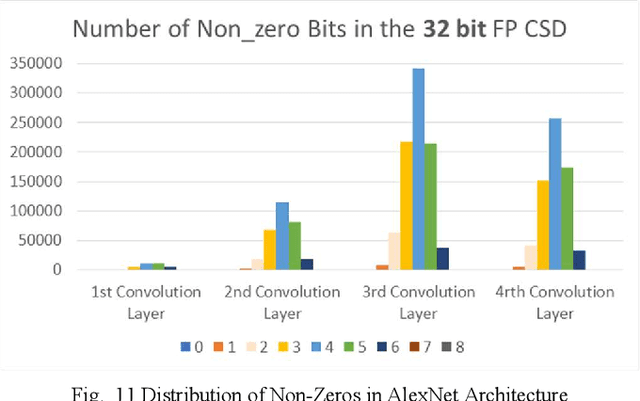

Deep Learning Architectures employ heavy computations and bulk of the computational energy is taken up by the convolution operations in the Convolutional Neural Networks. The objective of our proposed work is to reduce the energy consumption and size of CNN for using machine learning techniques in edge computing on ubiquitous computing devices. We propose Systematic Quality Scalable Design Methodology consisting of Quality Scalable Quantization on a higher abstraction level and Quality Scalable Multipliers at lower abstraction level. The first component consists of parameter compression where we approximate representation of values in filters of deep learning models by encoding in 3 bits. A shift and scale based on-chip decoding hardware is proposed which can decode these 3-bit representations to recover approximate filter values. The size of the DNN model is reduced this way and can be sent over a communication channel to be decoded on the edge computing devices. This way power is reduced by limiting data bits by approximation. In the second component we propose a quality scalable multiplier which reduces the number of partial products by converting numbers in canonic sign digit representations and further approximating the number by reducing least significant bits. These quantized CNNs provide almost same ac-curacy as network with original weights with little or no fine-tuning. The hardware for the adaptive multipliers utilize gate clocking for reducing energy consumption during multiplications. The proposed methodology greatly reduces the memory and power requirements of DNN models making it a feasible approach to deploy Deep Learning on edge computing. The experiments done on LeNet and ConvNets show an increase upto 6% of zeros and memory savings upto 82.4919% while keeping the accuracy near the state of the art.
Myocardial Infarction Detection from ECG: A Gramian Angular Field-based 2D-CNN Approach
Feb 25, 2023This paper presents a novel method for myocardial infarction (MI) detection using lead II of electrocardiogram (ECG). Under our proposed method, we first clean the noisy ECG signals using db4 wavelet, followed by an R-peak detection algorithm to segment the ECG signals into beats. We then translate the ECG timeseries dataset to an equivalent dataset of gray-scale images using Gramian Angular Summation Field (GASF) and Gramian Angular Difference Field (GADF) operations. Subsequently, the gray-scale images are fed into a custom two-dimensional convolutional neural network (2D-CNN) which efficiently differentiates the ECG beats of the healthy subjects from the ECG beats of the subjects with MI. We train and test the performance of our proposed method on a public dataset, namely, Physikalisch Technische Bundesanstalt (PTB) ECG dataset from Physionet. Our proposed approach achieves an average classification accuracy of 99.68\%, 99.80\%, 99.82\%, and 99.84\% under GASF dataset with noise and baseline wander, GADF dataset with noise and baseline wander, GASF dataset with noise and baseline wander removed, and GADF dataset with noise and baseline wander removed, respectively. Our proposed method is able to cope with additive noise and baseline wander, and does not require handcrafted features by a domain expert. Most importantly, this work opens the floor for innovation in wearable devices (e.g., smart watches, wrist bands etc.) to do accurate, real-time and early MI detection using a single-lead (lead II) ECG.
Distribution Regularized Self-Supervised Learning for Domain Adaptation of Semantic Segmentation
Jun 20, 2022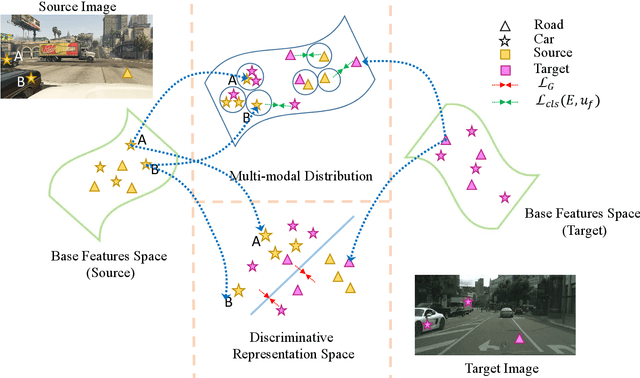
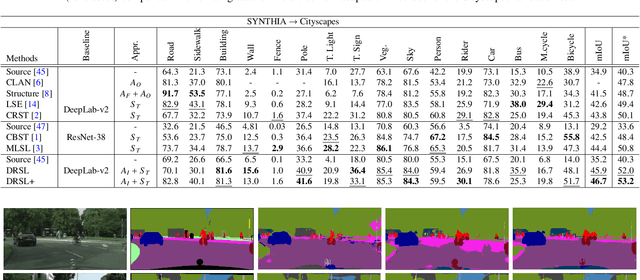
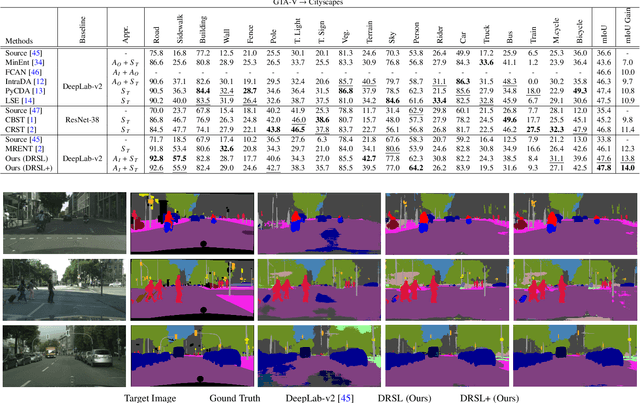
This paper proposes a novel pixel-level distribution regularization scheme (DRSL) for self-supervised domain adaptation of semantic segmentation. In a typical setting, the classification loss forces the semantic segmentation model to greedily learn the representations that capture inter-class variations in order to determine the decision (class) boundary. Due to the domain shift, this decision boundary is unaligned in the target domain, resulting in noisy pseudo labels adversely affecting self-supervised domain adaptation. To overcome this limitation, along with capturing inter-class variation, we capture pixel-level intra-class variations through class-aware multi-modal distribution learning (MMDL). Thus, the information necessary for capturing the intra-class variations is explicitly disentangled from the information necessary for inter-class discrimination. Features captured thus are much more informative, resulting in pseudo-labels with low noise. This disentanglement allows us to perform separate alignments in discriminative space and multi-modal distribution space, using cross-entropy based self-learning for the former. For later, we propose a novel stochastic mode alignment method, by explicitly decreasing the distance between the target and source pixels that map to the same mode. The distance metric learning loss, computed over pseudo-labels and backpropagated from multi-modal modeling head, acts as the regularizer over the base network shared with the segmentation head. The results from comprehensive experiments on synthetic to real domain adaptation setups, i.e., GTA-V/SYNTHIA to Cityscapes, show that DRSL outperforms many existing approaches (a minimum margin of 2.3% and 2.5% in mIoU for SYNTHIA to Cityscapes).
Combining Scale-Invariance and Uncertainty for Self-Supervised Domain Adaptation of Foggy Scenes Segmentation
Jan 17, 2022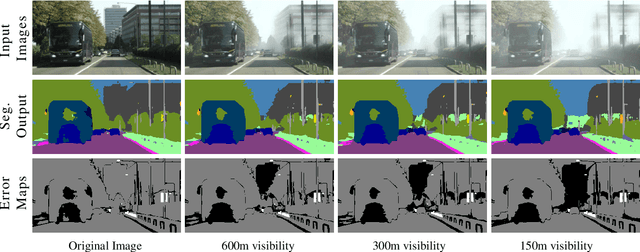

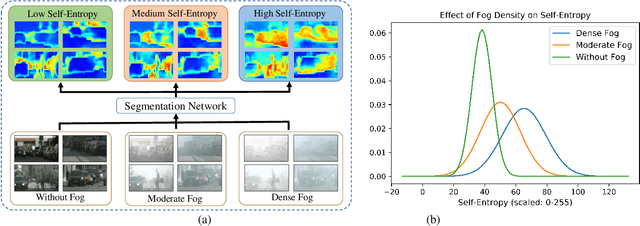
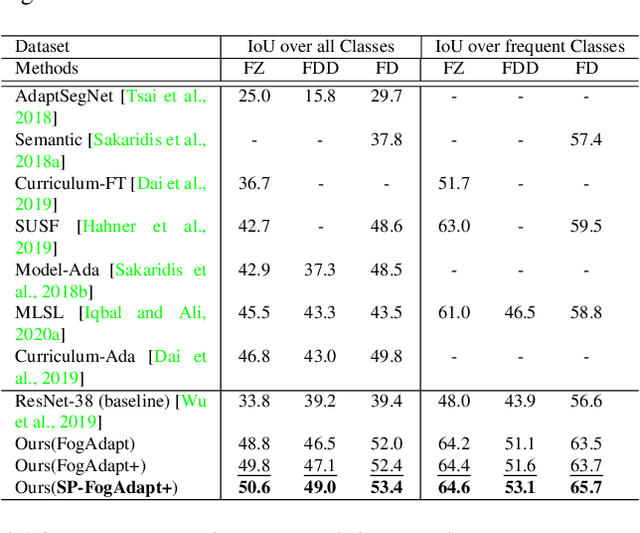
This paper presents FogAdapt, a novel approach for domain adaptation of semantic segmentation for dense foggy scenes. Although significant research has been directed to reduce the domain shift in semantic segmentation, adaptation to scenes with adverse weather conditions remains an open question. Large variations in the visibility of the scene due to weather conditions, such as fog, smog, and haze, exacerbate the domain shift, thus making unsupervised adaptation in such scenarios challenging. We propose a self-entropy and multi-scale information augmented self-supervised domain adaptation method (FogAdapt) to minimize the domain shift in foggy scenes segmentation. Supported by the empirical evidence that an increase in fog density results in high self-entropy for segmentation probabilities, we introduce a self-entropy based loss function to guide the adaptation method. Furthermore, inferences obtained at different image scales are combined and weighted by the uncertainty to generate scale-invariant pseudo-labels for the target domain. These scale-invariant pseudo-labels are robust to visibility and scale variations. We evaluate the proposed model on real clear-weather scenes to real foggy scenes adaptation and synthetic non-foggy images to real foggy scenes adaptation scenarios. Our experiments demonstrate that FogAdapt significantly outperforms the current state-of-the-art in semantic segmentation of foggy images. Specifically, by considering the standard settings compared to state-of-the-art (SOTA) methods, FogAdapt gains 3.8% on Foggy Zurich, 6.0% on Foggy Driving-dense, and 3.6% on Foggy Driving in mIoU when adapted from Cityscapes to Foggy Zurich.
MAQ-CaF: A Modular Air Quality Calibration and Forecasting method for cross-sensitive pollutants
Apr 22, 2021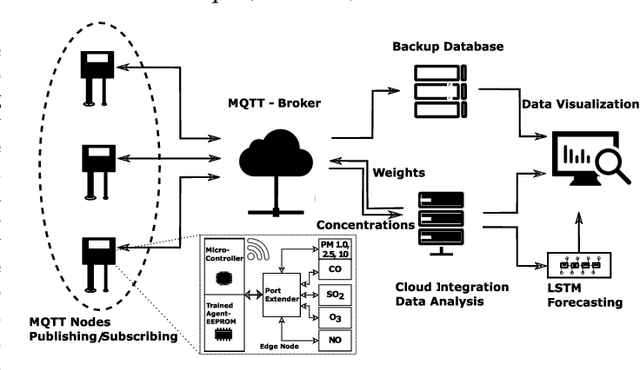
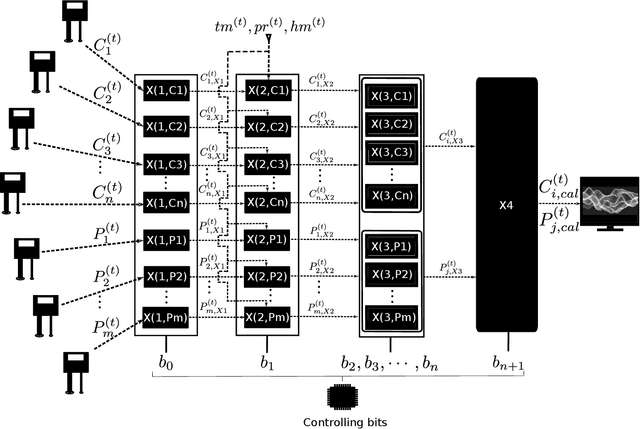
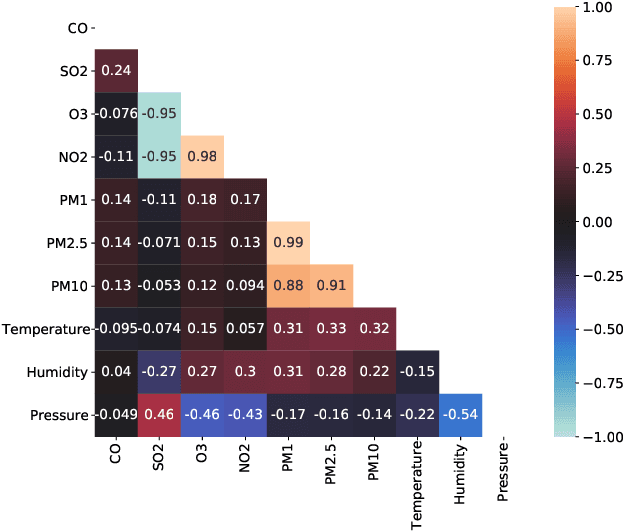
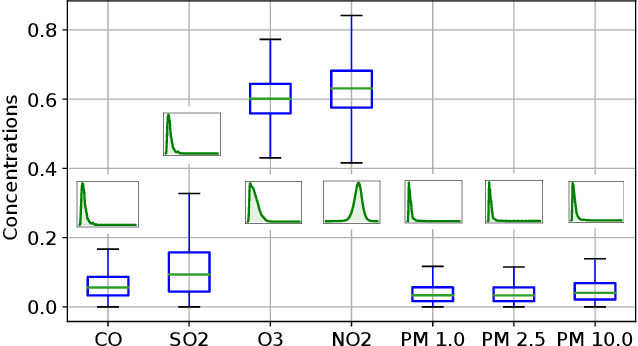
The climatic challenges are rising across the globe in general and in worst hit under-developed countries in particular. The need for accurate measurements and forecasting of pollutants with low-cost deployment is more pertinent today than ever before. Low-cost air quality monitoring sensors are prone to erroneous measurements, frequent downtimes, and uncertain operational conditions. Such a situation demands a prudent approach to ensure an effective and flexible calibration scheme. We propose MAQ-CaF, a modular air quality calibration, and forecasting methodology, that side-steps the challenges of unreliability through its modular machine learning-based design which leverages the potential of IoT framework. It stores the calibrated data both locally and remotely with an added feature of future predictions. Our specially designed validation process helps to establish the proposed solution's applicability and flexibility without compromising accuracy. CO, SO2, NO2, O3, PM1.0, PM2.5 and PM10 were calibrated and monitored with reasonable accuracy. Such an attempt is a step toward addressing climate change's global challenge through appropriate monitoring and air quality tracking across a wider geographical region via affordable monitoring.
Systimator: A Design Space Exploration Methodology for Systolic Array based CNNs Acceleration on the FPGA-based Edge Nodes
Dec 15, 2018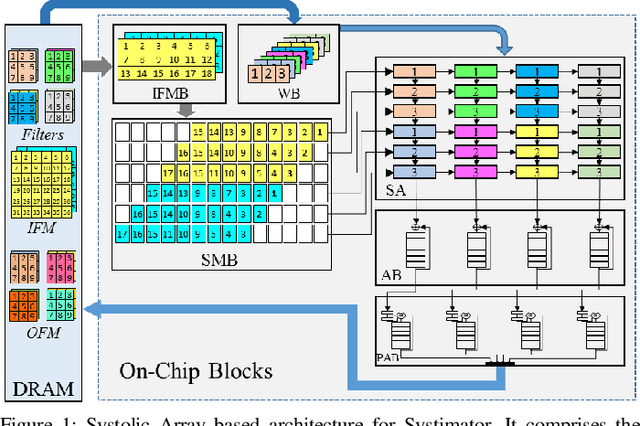
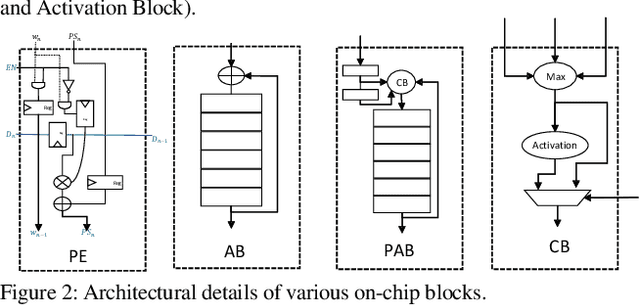
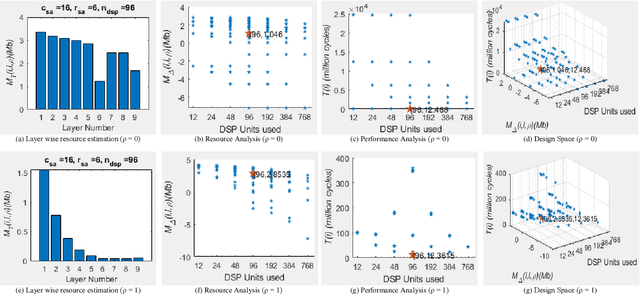
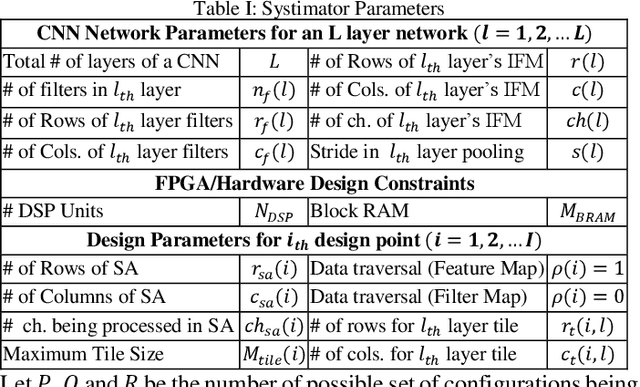
The evolution of IoT based smart applications demand porting of artificial intelligence algorithms to the edge computing devices. CNNs form a large part of these AI algorithms. Systolic array based CNN acceleration is being widely advocated due its ability to allow scalable architectures. However, CNNs are inherently memory and compute intensive algorithms, and hence pose significant challenges to be implemented on the resource-constrained edge computing devices. Memory-constrained low-cost FPGA based devices form a substantial fraction of these edge computing devices. Thus, when porting to such edge-computing devices, the designer is left unguided as to how to select a suitable systolic array configuration that could fit in the available hardware resources. In this paper we propose Systimator, a design space exploration based methodology that provides a set of design points that can be mapped within the memory bounds of the target FPGA device. The methodology is based upon an analytical model that is formulated to estimate the required resources for systolic arrays, assuming multiple data reuse patterns. The methodology further provides the performance estimates for each of the candidate design points. We show that Systimator provides an in-depth analysis of resource-requirement of systolic array based CNNs. We provide our resource estimation results for porting of convolutional layers of TINY YOLO, a CNN based object detector, on a Xilinx ARTIX 7 FPGA.
MPNA: A Massively-Parallel Neural Array Accelerator with Dataflow Optimization for Convolutional Neural Networks
Oct 30, 2018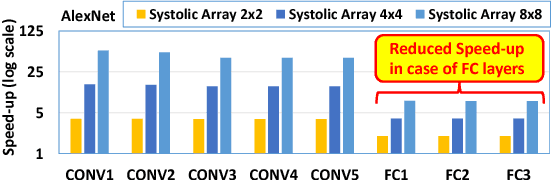


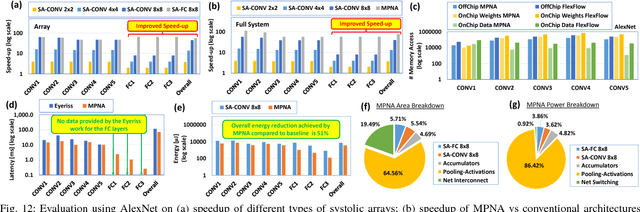
The state-of-the-art accelerators for Convolutional Neural Networks (CNNs) typically focus on accelerating only the convolutional layers, but do not prioritize the fully-connected layers much. Hence, they lack a synergistic optimization of the hardware architecture and diverse dataflows for the complete CNN design, which can provide a higher potential for performance/energy efficiency. Towards this, we propose a novel Massively-Parallel Neural Array (MPNA) accelerator that integrates two heterogeneous systolic arrays and respective highly-optimized dataflow patterns to jointly accelerate both the convolutional (CONV) and the fully-connected (FC) layers. Besides fully-exploiting the available off-chip memory bandwidth, these optimized dataflows enable high data-reuse of all the data types (i.e., weights, input and output activations), and thereby enable our MPNA to achieve high energy savings. We synthesized our MPNA architecture using the ASIC design flow for a 28nm technology, and performed functional and timing validation using multiple real-world complex CNNs. MPNA achieves 149.7GOPS/W at 280MHz and consumes 239mW. Experimental results show that our MPNA architecture provides 1.7x overall performance improvement compared to state-of-the-art accelerator, and 51% energy saving compared to the baseline architecture.