 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality Scalable Quantization Methodology for Deep Learning on Edge
Paper and Code
Jul 15, 2024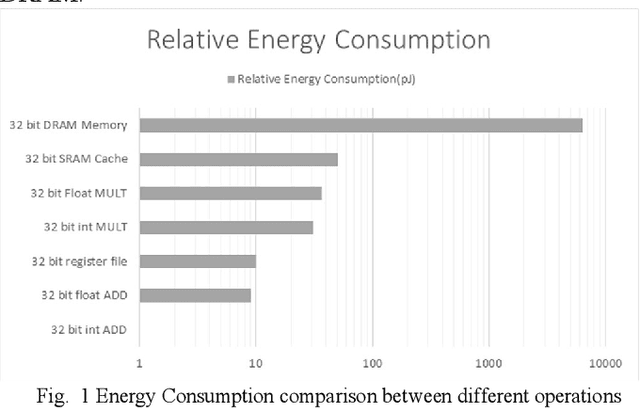
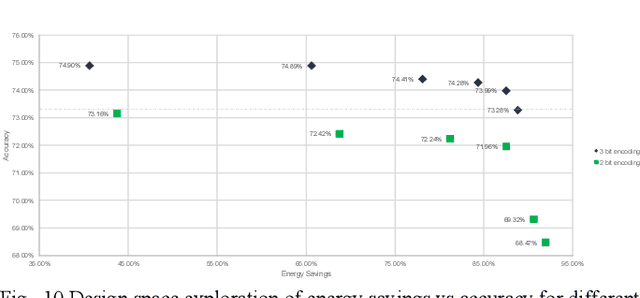
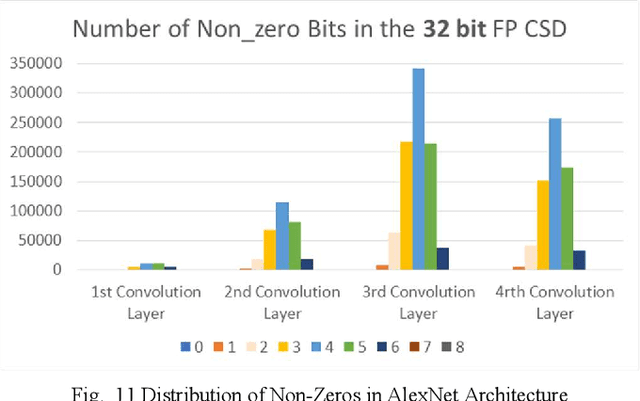

Deep Learning Architectures employ heavy computations and bulk of the computational energy is taken up by the convolution operations in the Convolutional Neural Networks. The objective of our proposed work is to reduce the energy consumption and size of CNN for using machine learning techniques in edge computing on ubiquitous computing devices. We propose Systematic Quality Scalable Design Methodology consisting of Quality Scalable Quantization on a higher abstraction level and Quality Scalable Multipliers at lower abstraction level. The first component consists of parameter compression where we approximate representation of values in filters of deep learning models by encoding in 3 bits. A shift and scale based on-chip decoding hardware is proposed which can decode these 3-bit representations to recover approximate filter values. The size of the DNN model is reduced this way and can be sent over a communication channel to be decoded on the edge computing devices. This way power is reduced by limiting data bits by approximation. In the second component we propose a quality scalable multiplier which reduces the number of partial products by converting numbers in canonic sign digit representations and further approximating the number by reducing least significant bits. These quantized CNNs provide almost same ac-curacy as network with original weights with little or no fine-tuning. The hardware for the adaptive multipliers utilize gate clocking for reducing energy consumption during multiplications. The proposed methodology greatly reduces the memory and power requirements of DNN models making it a feasible approach to deploy Deep Learning on edge computing. The experiments done on LeNet and ConvNets show an increase upto 6% of zeros and memory savings upto 82.4919% while keeping the accuracy near the state of the art.