 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGC-VTON: Predicting Globally Consistent and Occlusion Aware Local Flows with Neighborhood Integrity Preservation for Virtual Try-on
Nov 07, 2023Flow based garment warping is an integral part of image-based virtual try-on networks. However, optimizing a single flow predicting network for simultaneous global boundary alignment and local texture preservation results in sub-optimal flow fields. Moreover, dense flows are inherently not suited to handle intricate conditions like garment occlusion by body parts or by other garments. Forcing flows to handle the above issues results in various distortions like texture squeezing, and stretching. In this work, we propose a novel approach where we disentangle the global boundary alignment and local texture preserving tasks via our GlobalNet and LocalNet modules. A consistency loss is then employed between the two modules which harmonizes the local flows with the global boundary alignment. Additionally, we explicitly handle occlusions by predicting body-parts visibility mask, which is used to mask out the occluded regions in the warped garment. The masking prevents the LocalNet from predicting flows that distort texture to compensate for occlusions. We also introduce a novel regularization loss (NIPR), that defines a criteria to identify the regions in the warped garment where texture integrity is violated (squeezed or stretched). NIPR subsequently penalizes the flow in those regions to ensure regular and coherent warps that preserve the texture in local neighborhoods. Evaluation on a widely used virtual try-on dataset demonstrates strong performance of our network compared to the current SOTA methods.
Distribution Regularized Self-Supervised Learning for Domain Adaptation of Semantic Segmentation
Jun 20, 2022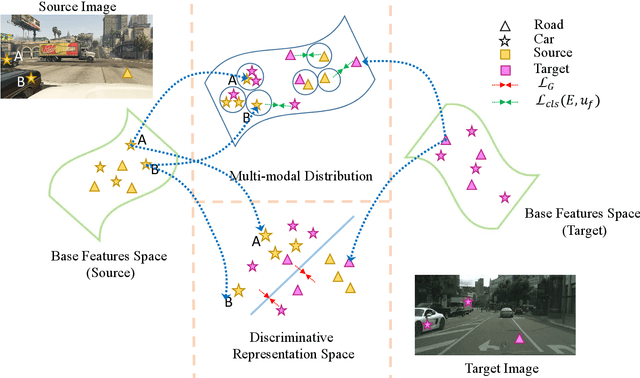
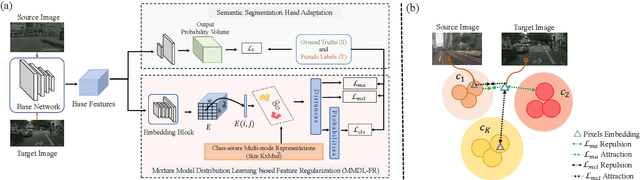
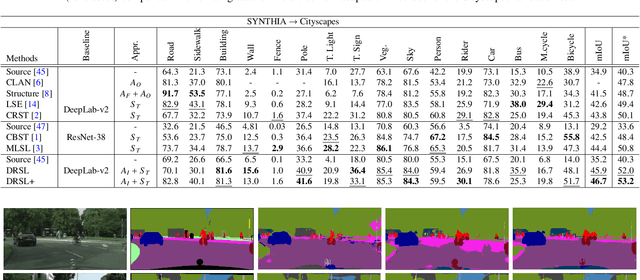
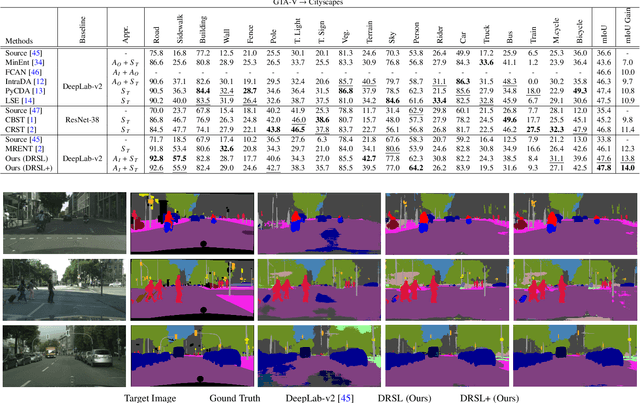
This paper proposes a novel pixel-level distribution regularization scheme (DRSL) for self-supervised domain adaptation of semantic segmentation. In a typical setting, the classification loss forces the semantic segmentation model to greedily learn the representations that capture inter-class variations in order to determine the decision (class) boundary. Due to the domain shift, this decision boundary is unaligned in the target domain, resulting in noisy pseudo labels adversely affecting self-supervised domain adaptation. To overcome this limitation, along with capturing inter-class variation, we capture pixel-level intra-class variations through class-aware multi-modal distribution learning (MMDL). Thus, the information necessary for capturing the intra-class variations is explicitly disentangled from the information necessary for inter-class discrimination. Features captured thus are much more informative, resulting in pseudo-labels with low noise. This disentanglement allows us to perform separate alignments in discriminative space and multi-modal distribution space, using cross-entropy based self-learning for the former. For later, we propose a novel stochastic mode alignment method, by explicitly decreasing the distance between the target and source pixels that map to the same mode. The distance metric learning loss, computed over pseudo-labels and backpropagated from multi-modal modeling head, acts as the regularizer over the base network shared with the segmentation head. The results from comprehensive experiments on synthetic to real domain adaptation setups, i.e., GTA-V/SYNTHIA to Cityscapes, show that DRSL outperforms many existing approaches (a minimum margin of 2.3% and 2.5% in mIoU for SYNTHIA to Cityscapes).
Cross-Region Building Counting in Satellite Imagery using Counting Consistency
Oct 26, 2021
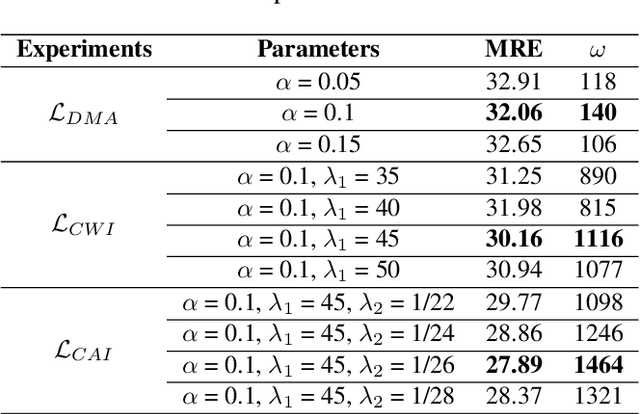
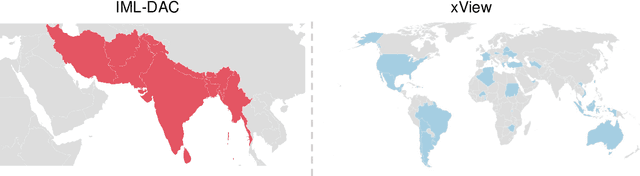
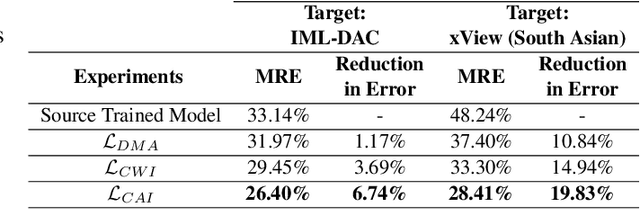
Estimating the number of buildings in any geographical region is a vital component of urban analysis, disaster management, and public policy decision. Deep learning methods for building localization and counting in satellite imagery, can serve as a viable and cheap alternative. However, these algorithms suffer performance degradation when applied to the regions on which they have not been trained. Current large datasets mostly cover the developed regions and collecting such datasets for every region is a costly, time-consuming, and difficult endeavor. In this paper, we propose an unsupervised domain adaptation method for counting buildings where we use a labeled source domain (developed regions) and adapt the trained model on an unlabeled target domain (developing regions). We initially align distribution maps across domains by aligning the output space distribution through adversarial loss. We then exploit counting consistency constraints, within-image count consistency, and across-image count consistency, to decrease the domain shift. Within-image consistency enforces that building count in the whole image should be greater than or equal to count in any of its sub-image. Across-image consistency constraint enforces that if an image contains considerably more buildings than the other image, then their sub-images shall also have the same order. These two constraints encourage the behavior to be consistent across and within the images, regardless of the scale. To evaluate the performance of our proposed approach, we collected and annotated a large-scale dataset consisting of challenging South Asian regions having higher building densities and irregular structures as compared to existing datasets. We perform extensive experiments to verify the efficacy of our approach and report improvements of approximately 7% to 20% over the competitive baseline methods.