 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Region Building Counting in Satellite Imagery using Counting Consistency
Oct 26, 2021
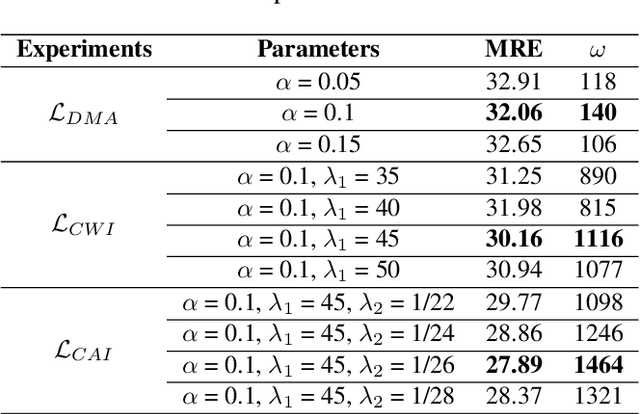
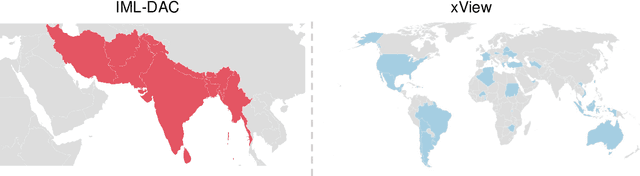
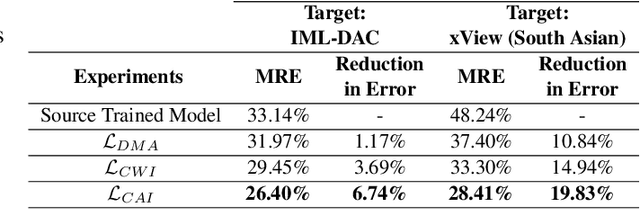
Estimating the number of buildings in any geographical region is a vital component of urban analysis, disaster management, and public policy decision. Deep learning methods for building localization and counting in satellite imagery, can serve as a viable and cheap alternative. However, these algorithms suffer performance degradation when applied to the regions on which they have not been trained. Current large datasets mostly cover the developed regions and collecting such datasets for every region is a costly, time-consuming, and difficult endeavor. In this paper, we propose an unsupervised domain adaptation method for counting buildings where we use a labeled source domain (developed regions) and adapt the trained model on an unlabeled target domain (developing regions). We initially align distribution maps across domains by aligning the output space distribution through adversarial loss. We then exploit counting consistency constraints, within-image count consistency, and across-image count consistency, to decrease the domain shift. Within-image consistency enforces that building count in the whole image should be greater than or equal to count in any of its sub-image. Across-image consistency constraint enforces that if an image contains considerably more buildings than the other image, then their sub-images shall also have the same order. These two constraints encourage the behavior to be consistent across and within the images, regardless of the scale. To evaluate the performance of our proposed approach, we collected and annotated a large-scale dataset consisting of challenging South Asian regions having higher building densities and irregular structures as compared to existing datasets. We perform extensive experiments to verify the efficacy of our approach and report improvements of approximately 7% to 20% over the competitive baseline methods.
Advanced kNN: A Mature Machine Learning Series
Mar 01, 2020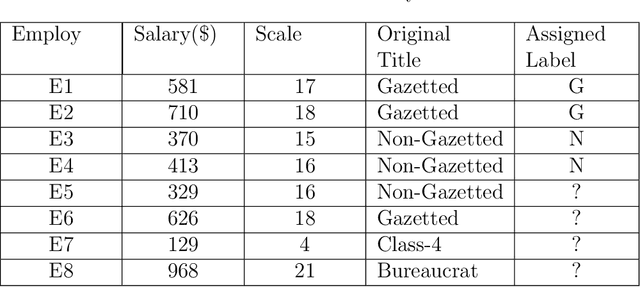
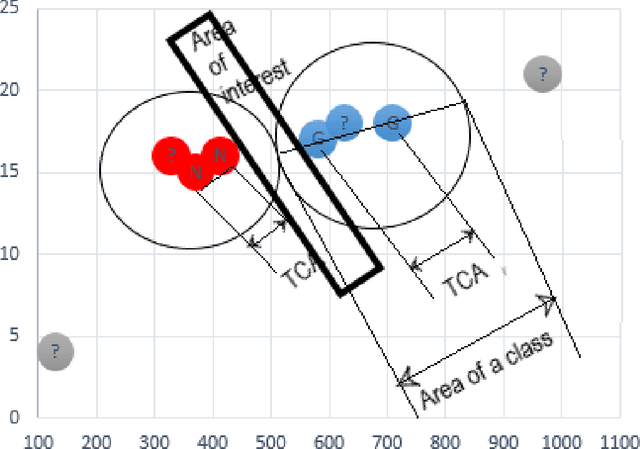
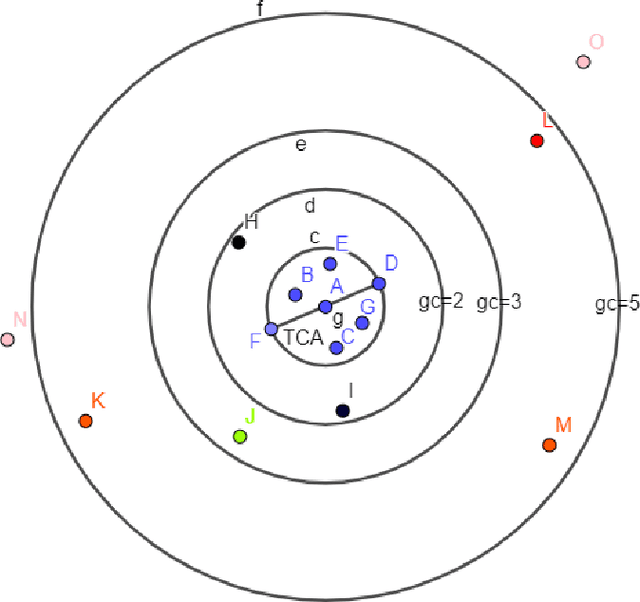
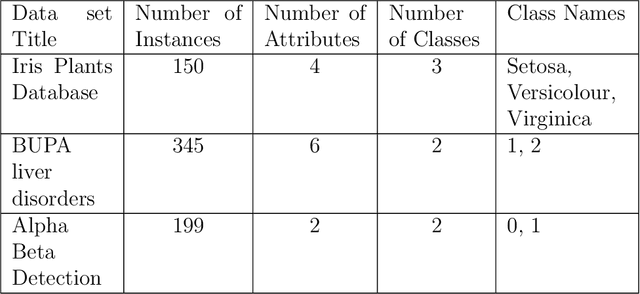
k-nearest neighbour (kNN) is one of the most prominent, simple and basic algorithm used in machine learning and data mining. However, kNN has limited prediction ability, i.e., kNN cannot predict any instance correctly if it does not belong to any of the predefined classes in the training data set. The purpose of this paper is to suggest an Advanced kNN (A-kNN) algorithm that will be able to classify an instance as unknown, after verifying that it does not belong to any of the predefined classes. Performance of kNN and A-kNN is compared on three different data sets namely iris plant data set, BUPA liver disorder data set, and Alpha Beta detection data set. Results of A-kNN are significantly accurate for detecting unknown instances.