 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistillGrasp: Integrating Features Correlation with Knowledge Distillation for Depth Completion of Transparent Objects
Aug 01, 2024Due to the visual properties of reflection and refraction, RGB-D cameras cannot accurately capture the depth of transparent objects, leading to incomplete depth maps. To fill in the missing points, recent studies tend to explore new visual features and design complex networks to reconstruct the depth, however, these approaches tremendously increase computation, and the correlation of different visual features remains a problem. To this end, we propose an efficient depth completion network named DistillGrasp which distillates knowledge from the teacher branch to the student branch. Specifically, in the teacher branch, we design a position correlation block (PCB) that leverages RGB images as the query and key to search for the corresponding values, guiding the model to establish correct correspondence between two features and transfer it to the transparent areas. For the student branch, we propose a consistent feature correlation module (CFCM) that retains the reliable regions of RGB images and depth maps respectively according to the consistency and adopts a CNN to capture the pairwise relationship for depth completion. To avoid the student branch only learning regional features from the teacher branch, we devise a distillation loss that not only considers the distance loss but also the object structure and edge information. Extensive experiments conducted on the ClearGrasp dataset manifest that our teacher network outperforms state-of-the-art methods in terms of accuracy and generalization, and the student network achieves competitive results with a higher speed of 48 FPS. In addition, the significant improvement in a real-world robotic grasping system illustrates the effectiveness and robustness of our proposed system.
Pathloss-based non-Line-of-Sight Identification in an Indoor Environment: An Experimental Study
Jul 29, 2023

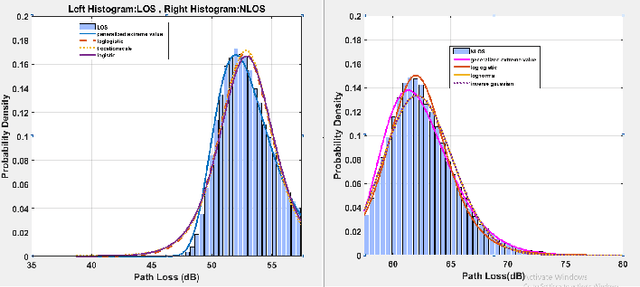
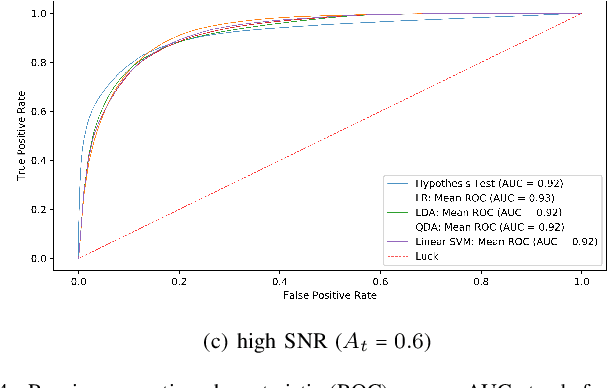
This paper reports the findings of an experimental study on the problem of line-of-sight (LOS)/non-line-of-sight (NLOS) classification in an indoor environment. Specifically, we deploy a pair of NI 2901 USRP software-defined radios (SDR) in a large hall. The transmit SDR emits an unmodulated tone of frequency 10 KHz, on a center frequency of 2.4 GHz, using three different signal-to-noise ratios (SNR). The receive SDR constructs a dataset of pathloss measurements from the received signal as it moves across 15 equi-spaced positions on a 1D grid (for both LOS and NLOS scenarios). We utilize our custom dataset to estimate the pathloss parameters (i.e., pathloss exponent) using the least-squares method, and later, utilize the parameterized pathloss model to construct a binary hypothesis test for NLOS identification. Further, noting that the pathloss measurements slightly deviate from Gaussian distribution, we feed our custom dataset to four machine learning (ML) algorithms, i.e., linear support vector machine (SVM) and radial basis function SVM (RBF-SVM), linear discriminant analysis (LDA), quadratic discriminant analysis (QDA), and logistic regression (LR). It turns out that the performance of the ML algorithms is only slightly superior to the Neyman-Pearson-based binary hypothesis test (BHT). That is, the RBF-SVM classifier (the best performing ML classifier) and the BHT achieve a maximum accuracy of 88.24% and 87.46% for low SNR, 83.91% and 81.21% for medium SNR, and 87.38% and 86.65% for high SNR.
A Review on Computational Intelligence Techniques in Cloud and Edge Computing
Jul 27, 2020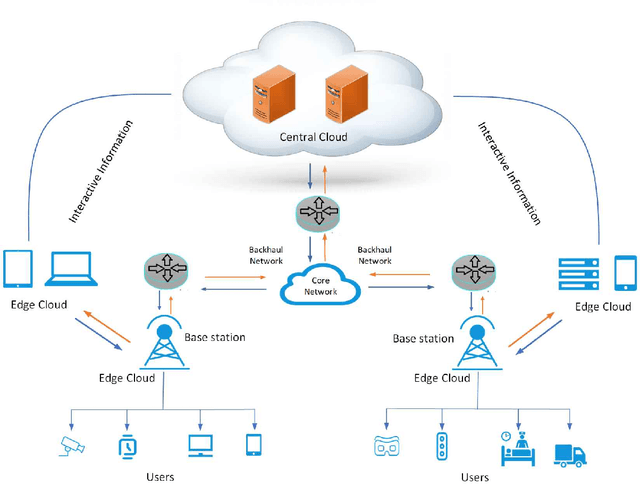
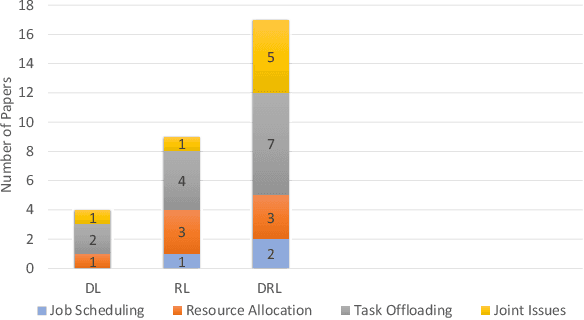
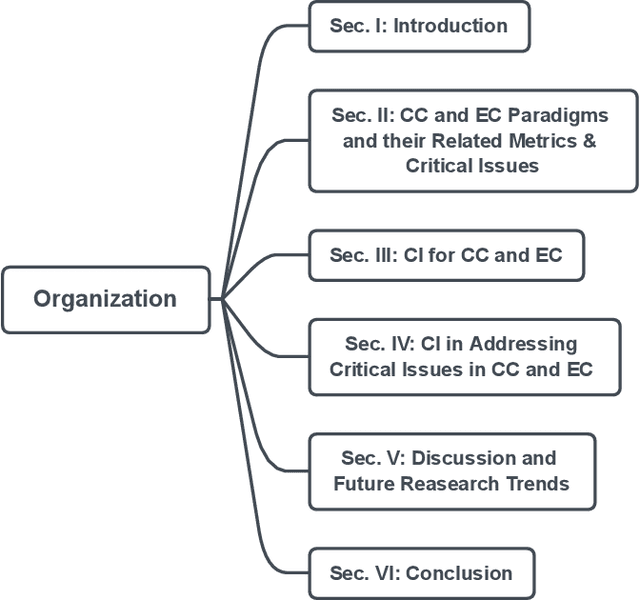
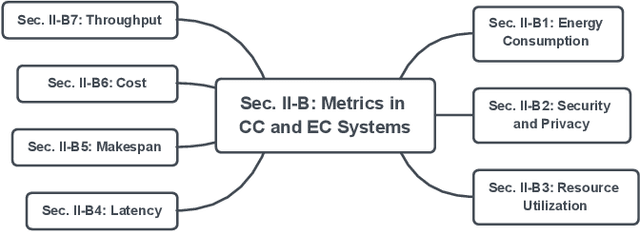
Cloud computing (CC) is a centralized computing paradigm that accumulates resources centrally and provides these resources to users through Internet. Although CC holds a large number of resources, it may not be acceptable by real-time mobile applications, as it is usually far away from users geographically. On the other hand, edge computing (EC), which distributes resources to the network edge, enjoys increasing popularity in the applications with low-latency and high-reliability requirements. EC provides resources in a decentralized manner, which can respond to users' requirements faster than the normal CC, but with limited computing capacities. As both CC and EC are resource-sensitive, several big issues arise, such as how to conduct job scheduling, resource allocation, and task offloading, which significantly influence the performance of the whole system. To tackle these issues, many optimization problems have been formulated. These optimization problems usually have complex properties, such as non-convexity and NP-hardness, which may not be addressed by the traditional convex optimization-based solutions. Computational intelligence (CI), consisting of a set of nature-inspired computational approaches, recently exhibits great potential in addressing these optimization problems in CC and EC. This paper provides an overview of research problems in CC and EC and recent progresses in addressing them with the help of CI techniques. Informative discussions and future research trends are also presented, with the aim of offering insights to the readers and motivating new research directions.
Advanced kNN: A Mature Machine Learning Series
Mar 01, 2020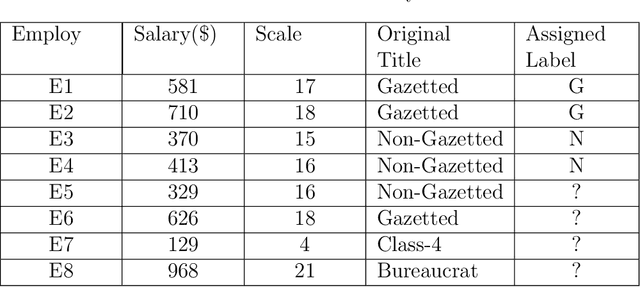
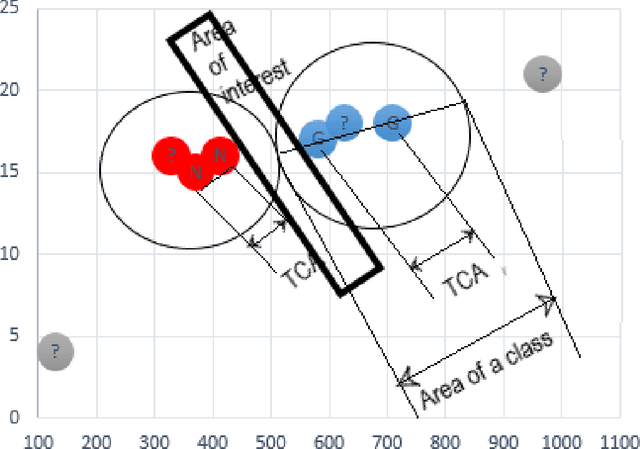
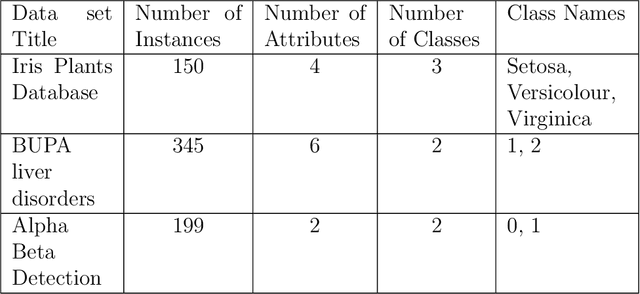
k-nearest neighbour (kNN) is one of the most prominent, simple and basic algorithm used in machine learning and data mining. However, kNN has limited prediction ability, i.e., kNN cannot predict any instance correctly if it does not belong to any of the predefined classes in the training data set. The purpose of this paper is to suggest an Advanced kNN (A-kNN) algorithm that will be able to classify an instance as unknown, after verifying that it does not belong to any of the predefined classes. Performance of kNN and A-kNN is compared on three different data sets namely iris plant data set, BUPA liver disorder data set, and Alpha Beta detection data set. Results of A-kNN are significantly accurate for detecting unknown instances.
Blind Image Deconvolution using Pretrained Generative Priors
Aug 20, 2019
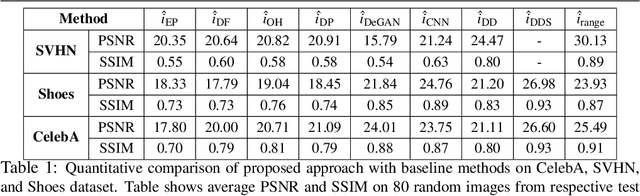
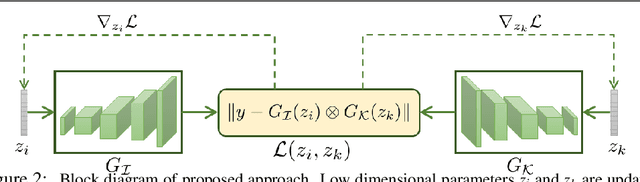

This paper proposes a novel approach to regularize the ill-posed blind image deconvolution (blind image deblurring) problem using deep generative networks. We employ two separate deep generative models - one trained to produce sharp images while the other trained to generate blur kernels from lower dimensional parameters. To deblur, we propose an alternating gradient descent scheme operating in the latent lower-dimensional space of each of the pretrained generative models. Our experiments show excellent deblurring results even under large blurs and heavy noise. To improve the performance on rich image datasets not well learned by the generative networks, we present a modification of the proposed scheme that governs the deblurring process under both generative and classical priors.
Invertible generative models for inverse problems: mitigating representation error and dataset bias
May 28, 2019
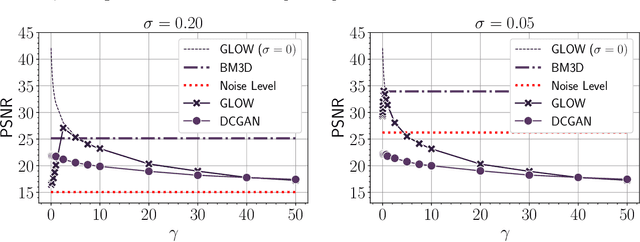

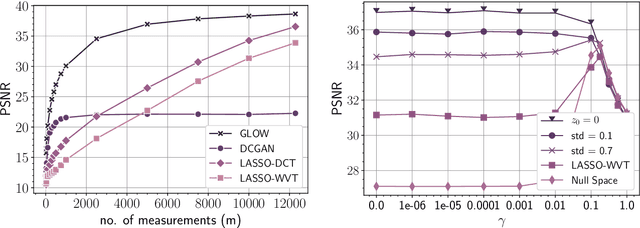
Trained generative models have shown remarkable performance as priors for inverse problems in imaging. For example, Generative Adversarial Network priors permit recovery of test images from 5-10x fewer measurements than sparsity priors. Unfortunately, these models may be unable to represent any particular image because of architectural choices, mode collapse, and bias in the training dataset. In this paper, we demonstrate that invertible neural networks, which have zero representation error by design, can be effective natural signal priors at inverse problems such as denoising, compressive sensing, and inpainting. Given a trained generative model, we study the empirical risk formulation of the desired inverse problem under a regularization that promotes high likelihood images, either directly by penalization or algorithmically by initialization. For compressive sensing, invertible priors can yield higher accuracy than sparsity priors across almost all undersampling ratios. For the same accuracy on test images, they can use 10-20x fewer measurements. We demonstrate that invertible priors can yield better reconstructions than sparsity priors for images that have rare features of variation within the biased training set, including out-of-distribution natural images.
Motion Corrected Multishot MRI Reconstruction Using Generative Networks with Sensitivity Encoding
Mar 24, 2019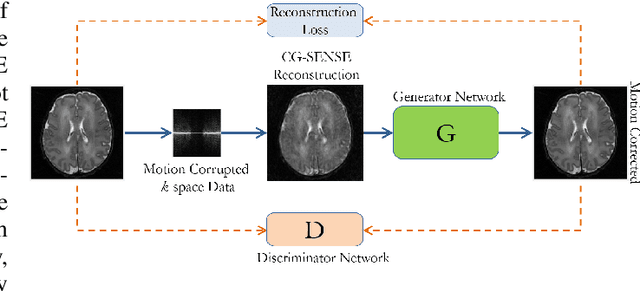
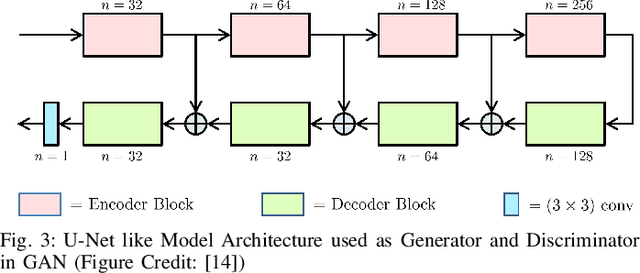

Multishot Magnetic Resonance Imaging (MRI) is a promising imaging modality that can produce a high-resolution image with relatively less data acquisition time. The downside of multishot MRI is that it is very sensitive to subject motion and even small amounts of motion during the scan can produce artifacts in the final MR image that may cause misdiagnosis. Numerous efforts have been made to address this issue; however, all of these proposals are limited in terms of how much motion they can correct and the required computational time. In this paper, we propose a novel generative networks based conjugate gradient SENSE (CG-SENSE) reconstruction framework for motion correction in multishot MRI. The proposed framework first employs CG-SENSE reconstruction to produce the motion-corrupted image and then a generative adversarial network (GAN) is used to correct the motion artifacts. The proposed method has been rigorously evaluated on synthetically corrupted data on varying degrees of motion, numbers of shots, and encoding trajectories. Our analyses (both quantitative as well as qualitative/visual analysis) establishes that the proposed method significantly robust and outperforms state-of-the-art motion correction techniques and also reduces severalfold of computational times.
Leveraging Deep Stein's Unbiased Risk Estimator for Unsupervised X-ray Denoising
Nov 29, 2018
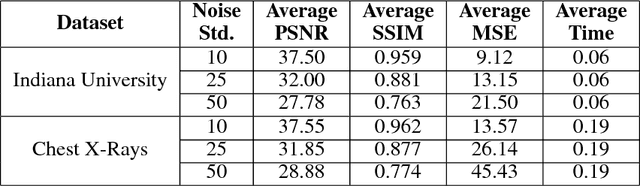
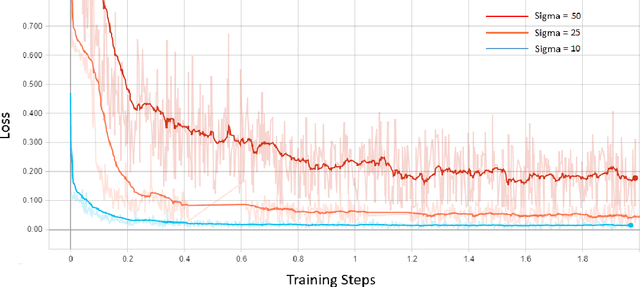
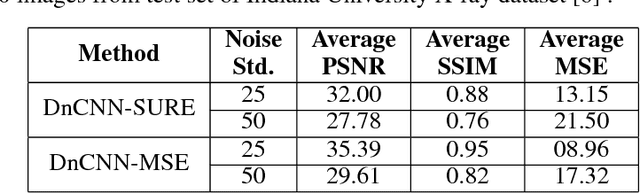
Among the plethora of techniques devised to curb the prevalence of noise in medical images, deep learning based approaches have shown the most promise. However, one critical limitation of these deep learning based denoisers is the requirement of high-quality noiseless ground truth images that are difficult to obtain in many medical imaging applications such as X-rays. To circumvent this issue, we leverage recently proposed approach of [7] that incorporates Stein's Unbiased Risk Estimator (SURE) to train a deep convolutional neural network without requiring denoised ground truth X-ray data. Our experimental results demonstrate the effectiveness of SURE based approach for denoising X-ray images.
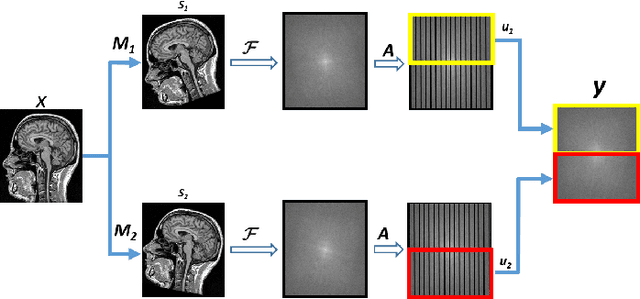
Automating Motion Correction in Multishot MRI Using Generative Adversarial Networks
Nov 24, 2018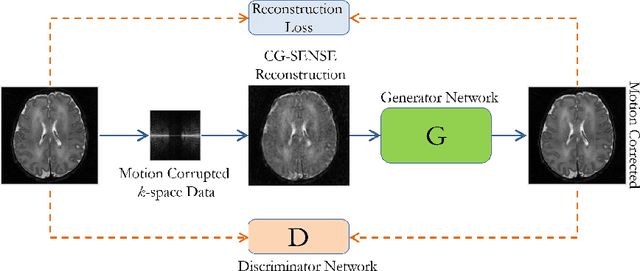

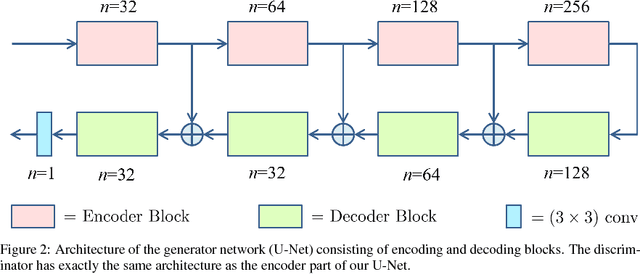

Multishot Magnetic Resonance Imaging (MRI) has recently gained popularity as it accelerates the MRI data acquisition process without compromising the quality of final MR image. However, it suffers from motion artifacts caused by patient movements which may lead to misdiagnosis. Modern state-of-the-art motion correction techniques are able to counter small degree motion, however, their adoption is hindered by their time complexity. This paper proposes a Generative Adversarial Network (GAN) for reconstructing motion free high-fidelity images while reducing the image reconstruction time by an impressive two orders of magnitude.
Blind Image Deconvolution using Deep Generative Priors
Mar 15, 2018

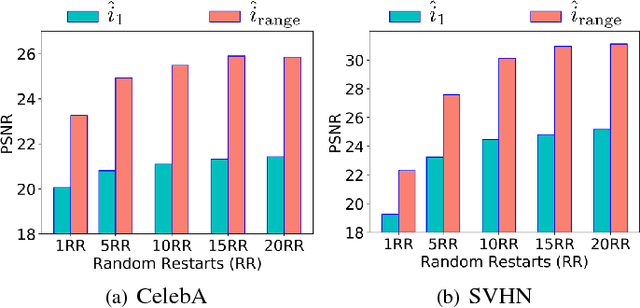
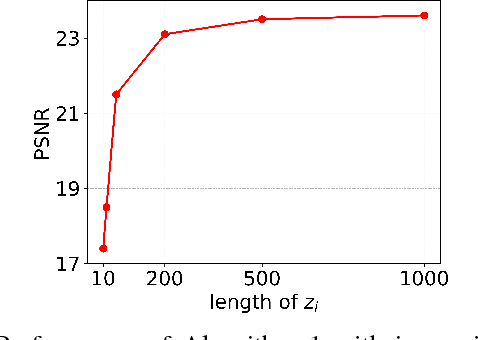
This paper proposes a new framework to regularize the \textit{ill-posed} and \textit{non-linear} blind image deconvolution problem by using deep generative priors. We employ two separate deep generative models --- one trained to produce sharp images while the other trained to generate blur kernels from lower-dimensional parameters. The regularized problem is efficiently solved by simple alternating gradient descent algorithm operating in the latent lower-dimensional space of each generative model. We empirically show that by doing so, excellent image deblurring results are achieved even under extravagantly large blurs, and heavy noise. Our proposed method is in stark contrast to the conventional end-to-end approaches, where a deep neural network is trained on blurred input, and the corresponding sharp output images while completely ignoring the knowledge of the underlying forward map (convolution operator) in image blurring.