 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative AI in Signal Processing Education: An Audio Foundation Model Based Approach
Feb 01, 2026Audio Foundation Models (AFMs), a specialized category of Generative AI (GenAI), have the potential to transform signal processing (SP) education by integrating core applications such as speech and audio enhancement, denoising, source separation, feature extraction, automatic classification, and real-time signal analysis into learning and research. This paper introduces SPEduAFM, a conceptual AFM tailored for SP education, bridging traditional SP principles with GenAI-driven innovations. Through an envisioned case study, we outline how AFMs can enable a range of applications, including automated lecture transcription, interactive demonstrations, and inclusive learning tools, showcasing their potential to transform abstract concepts into engaging, practical experiences. This paper also addresses challenges such as ethics, explainability, and customization by highlighting dynamic, real-time auditory interactions that foster experiential and authentic learning. By presenting SPEduAFM as a forward-looking vision, we aim to inspire broader adoption of GenAI in engineering education, enhancing accessibility, engagement, and innovation in the classroom and beyond.
Can AI Chatbots Provide Coaching in Engineering? Beyond Information Processing Toward Mastery
Jan 07, 2026Engineering education faces a double disruption: traditional apprenticeship models that cultivated judgment and tacit skill are eroding, just as generative AI emerges as an informal coaching partner. This convergence rekindles long-standing questions in the philosophy of AI and cognition about the limits of computation, the nature of embodied rationality, and the distinction between information processing and wisdom. Building on this rich intellectual tradition, this paper examines whether AI chatbots can provide coaching that fosters mastery rather than merely delivering information. We synthesize critical perspectives from decades of scholarship on expertise, tacit knowledge, and human-machine interaction, situating them within the context of contemporary AI-driven education. Empirically, we report findings from a mixed-methods study (N = 75 students, N = 7 faculty) exploring the use of a coaching chatbot in engineering education. Results reveal a consistent boundary: participants accept AI for technical problem solving (convergent tasks; M = 3.84 on a 1-5 Likert scale) but remain skeptical of its capacity for moral, emotional, and contextual judgment (divergent tasks). Faculty express stronger concerns over risk (M = 4.71 vs. M = 4.14, p = 0.003), and privacy emerges as a key requirement, with 64-71 percent of participants demanding strict confidentiality. Our findings suggest that while generative AI can democratize access to cognitive and procedural support, it cannot replicate the embodied, value-laden dimensions of human mentorship. We propose a multiplex coaching framework that integrates human wisdom within expert-in-the-loop models, preserving the depth of apprenticeship while leveraging AI scalability to enrich the next generation of engineering education.
GuardEval: A Multi-Perspective Benchmark for Evaluating Safety, Fairness, and Robustness in LLM Moderators
Dec 22, 2025As large language models (LLMs) become deeply embedded in daily life, the urgent need for safer moderation systems, distinguishing between naive from harmful requests while upholding appropriate censorship boundaries, has never been greater. While existing LLMs can detect harmful or unsafe content, they often struggle with nuanced cases such as implicit offensiveness, subtle gender and racial biases, and jailbreak prompts, due to the subjective and context-dependent nature of these issues. Furthermore, their heavy reliance on training data can reinforce societal biases, resulting in inconsistent and ethically problematic outputs. To address these challenges, we introduce GuardEval, a unified multi-perspective benchmark dataset designed for both training and evaluation, containing 106 fine-grained categories spanning human emotions, offensive and hateful language, gender and racial bias, and broader safety concerns. We also present GemmaGuard (GGuard), a QLoRA fine-tuned version of Gemma3-12B trained on GuardEval, to assess content moderation with fine-grained labels. Our evaluation shows that GGuard achieves a macro F1 score of 0.832, substantially outperforming leading moderation models, including OpenAI Moderator (0.64) and Llama Guard (0.61). We show that multi-perspective, human-centered safety benchmarks are critical for reducing biased and inconsistent moderation decisions. GuardEval and GGuard together demonstrate that diverse, representative data materially improve safety, fairness, and robustness on complex, borderline cases.
Anatomy-Guided Representation Learning Using a Transformer-Based Network for Thyroid Nodule Segmentation in Ultrasound Images
Dec 14, 2025Accurate thyroid nodule segmentation in ultrasound images is critical for diagnosis and treatment planning. However, ambiguous boundaries between nodules and surrounding tissues, size variations, and the scarcity of annotated ultrasound data pose significant challenges for automated segmentation. Existing deep learning models struggle to incorporate contextual information from the thyroid gland and generalize effectively across diverse cases. To address these challenges, we propose SSMT-Net, a Semi-Supervised Multi-Task Transformer-based Network that leverages unlabeled data to enhance Transformer-centric encoder feature extraction capability in an initial unsupervised phase. In the supervised phase, the model jointly optimizes nodule segmentation, gland segmentation, and nodule size estimation, integrating both local and global contextual features. Extensive evaluations on the TN3K and DDTI datasets demonstrate that SSMT-Net outperforms state-of-the-art methods, with higher accuracy and robustness, indicating its potential for real-world clinical applications.
WorldView-Bench: A Benchmark for Evaluating Global Cultural Perspectives in Large Language Models
May 14, 2025Large Language Models (LLMs) are predominantly trained and aligned in ways that reinforce Western-centric epistemologies and socio-cultural norms, leading to cultural homogenization and limiting their ability to reflect global civilizational plurality. Existing benchmarking frameworks fail to adequately capture this bias, as they rely on rigid, closed-form assessments that overlook the complexity of cultural inclusivity. To address this, we introduce WorldView-Bench, a benchmark designed to evaluate Global Cultural Inclusivity (GCI) in LLMs by analyzing their ability to accommodate diverse worldviews. Our approach is grounded in the Multiplex Worldview proposed by Senturk et al., which distinguishes between Uniplex models, reinforcing cultural homogenization, and Multiplex models, which integrate diverse perspectives. WorldView-Bench measures Cultural Polarization, the exclusion of alternative perspectives, through free-form generative evaluation rather than conventional categorical benchmarks. We implement applied multiplexity through two intervention strategies: (1) Contextually-Implemented Multiplex LLMs, where system prompts embed multiplexity principles, and (2) Multi-Agent System (MAS)-Implemented Multiplex LLMs, where multiple LLM agents representing distinct cultural perspectives collaboratively generate responses. Our results demonstrate a significant increase in Perspectives Distribution Score (PDS) entropy from 13% at baseline to 94% with MAS-Implemented Multiplex LLMs, alongside a shift toward positive sentiment (67.7%) and enhanced cultural balance. These findings highlight the potential of multiplex-aware AI evaluation in mitigating cultural bias in LLMs, paving the way for more inclusive and ethically aligned AI systems.
Large Language Model Enhanced Particle Swarm Optimization for Hyperparameter Tuning for Deep Learning Models
Apr 19, 2025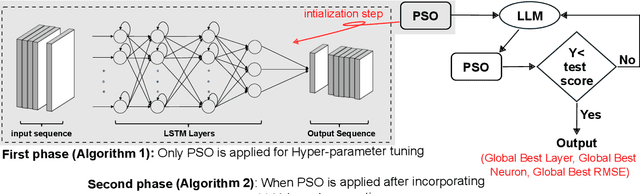
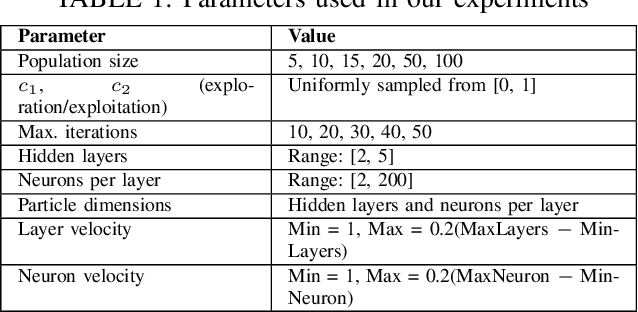
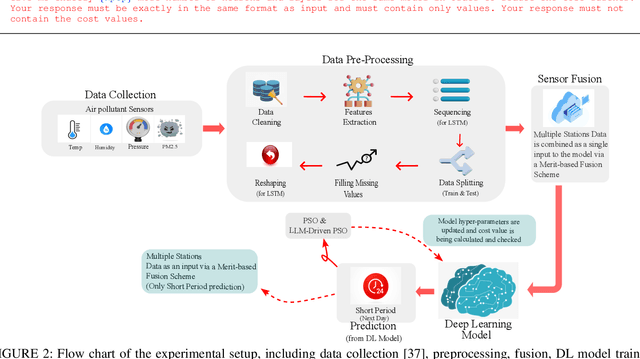

Determining the ideal architecture for deep learning models, such as the number of layers and neurons, is a difficult and resource-intensive process that frequently relies on human tuning or computationally costly optimization approaches. While Particle Swarm Optimization (PSO) and Large Language Models (LLMs) have been individually applied in optimization and deep learning, their combined use for enhancing convergence in numerical optimization tasks remains underexplored. Our work addresses this gap by integrating LLMs into PSO to reduce model evaluations and improve convergence for deep learning hyperparameter tuning. The proposed LLM-enhanced PSO method addresses the difficulties of efficiency and convergence by using LLMs (particularly ChatGPT-3.5 and Llama3) to improve PSO performance, allowing for faster achievement of target objectives. Our method speeds up search space exploration by substituting underperforming particle placements with best suggestions offered by LLMs. Comprehensive experiments across three scenarios -- (1) optimizing the Rastrigin function, (2) using Long Short-Term Memory (LSTM) networks for time series regression, and (3) using Convolutional Neural Networks (CNNs) for material classification -- show that the method significantly improves convergence rates and lowers computational costs. Depending on the application, computational complexity is lowered by 20% to 60% compared to traditional PSO methods. Llama3 achieved a 20% to 40% reduction in model calls for regression tasks, whereas ChatGPT-3.5 reduced model calls by 60% for both regression and classification tasks, all while preserving accuracy and error rates. This groundbreaking methodology offers a very efficient and effective solution for optimizing deep learning models, leading to substantial computational performance improvements across a wide range of applications.
A Survey of Social Cybersecurity: Techniques for Attack Detection, Evaluations, Challenges, and Future Prospects
Apr 06, 2025



In today's digital era, the Internet, especially social media platforms, plays a significant role in shaping public opinions, attitudes, and beliefs. Unfortunately, the credibility of scientific information sources is often undermined by the spread of misinformation through various means, including technology-driven tools like bots, cyborgs, trolls, sock-puppets, and deep fakes. This manipulation of public discourse serves antagonistic business agendas and compromises civil society. In response to this challenge, a new scientific discipline has emerged: social cybersecurity.
TEMSET-24K: Densely Annotated Dataset for Indexing Multipart Endoscopic Videos using Surgical Timeline Segmentation
Feb 10, 2025Indexing endoscopic surgical videos is vital in surgical data science, forming the basis for systematic retrospective analysis and clinical performance evaluation. Despite its significance, current video analytics rely on manual indexing, a time-consuming process. Advances in computer vision, particularly deep learning, offer automation potential, yet progress is limited by the lack of publicly available, densely annotated surgical datasets. To address this, we present TEMSET-24K, an open-source dataset comprising 24,306 trans-anal endoscopic microsurgery (TEMS) video micro-clips. Each clip is meticulously annotated by clinical experts using a novel hierarchical labeling taxonomy encompassing phase, task, and action triplets, capturing intricate surgical workflows. To validate this dataset, we benchmarked deep learning models, including transformer-based architectures. Our in silico evaluation demonstrates high accuracy (up to 0.99) and F1 scores (up to 0.99) for key phases like Setup and Suturing. The STALNet model, tested with ConvNeXt, ViT, and SWIN V2 encoders, consistently segmented well-represented phases. TEMSET-24K provides a critical benchmark, propelling state-of-the-art solutions in surgical data science.
Safeguarding connected autonomous vehicle communication: Protocols, intra- and inter-vehicular attacks and defenses
Feb 06, 2025



The advancements in autonomous driving technology, coupled with the growing interest from automotive manufacturers and tech companies, suggest a rising adoption of Connected Autonomous Vehicles (CAVs) in the near future. Despite some evidence of higher accident rates in AVs, these incidents tend to result in less severe injuries compared to traditional vehicles due to cooperative safety measures. However, the increased complexity of CAV systems exposes them to significant security vulnerabilities, potentially compromising their performance and communication integrity. This paper contributes by presenting a detailed analysis of existing security frameworks and protocols, focusing on intra- and inter-vehicle communications. We systematically evaluate the effectiveness of these frameworks in addressing known vulnerabilities and propose a set of best practices for enhancing CAV communication security. The paper also provides a comprehensive taxonomy of attack vectors in CAV ecosystems and suggests future research directions for designing more robust security mechanisms. Our key contributions include the development of a new classification system for CAV security threats, the proposal of practical security protocols, and the introduction of use cases that demonstrate how these protocols can be integrated into real-world CAV applications. These insights are crucial for advancing secure CAV adoption and ensuring the safe integration of autonomous vehicles into intelligent transportation systems.
Open Foundation Models in Healthcare: Challenges, Paradoxes, and Opportunities with GenAI Driven Personalized Prescription
Feb 04, 2025In response to the success of proprietary Large Language Models (LLMs) such as OpenAI's GPT-4, there is a growing interest in developing open, non-proprietary LLMs and AI foundation models (AIFMs) for transparent use in academic, scientific, and non-commercial applications. Despite their inability to match the refined functionalities of their proprietary counterparts, open models hold immense potential to revolutionize healthcare applications. In this paper, we examine the prospects of open-source LLMs and AIFMs for developing healthcare applications and make two key contributions. Firstly, we present a comprehensive survey of the current state-of-the-art open-source healthcare LLMs and AIFMs and introduce a taxonomy of these open AIFMs, categorizing their utility across various healthcare tasks. Secondly, to evaluate the general-purpose applications of open LLMs in healthcare, we present a case study on personalized prescriptions. This task is particularly significant due to its critical role in delivering tailored, patient-specific medications that can greatly improve treatment outcomes. In addition, we compare the performance of open-source models with proprietary models in settings with and without Retrieval-Augmented Generation (RAG). Our findings suggest that, although less refined, open LLMs can achieve performance comparable to proprietary models when paired with grounding techniques such as RAG. Furthermore, to highlight the clinical significance of LLMs-empowered personalized prescriptions, we perform subjective assessment through an expert clinician. We also elaborate on ethical considerations and potential risks associated with the misuse of powerful LLMs and AIFMs, highlighting the need for a cautious and responsible implementation in healthcare.