 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTEMSET-24K: Densely Annotated Dataset for Indexing Multipart Endoscopic Videos using Surgical Timeline Segmentation
Feb 10, 2025Indexing endoscopic surgical videos is vital in surgical data science, forming the basis for systematic retrospective analysis and clinical performance evaluation. Despite its significance, current video analytics rely on manual indexing, a time-consuming process. Advances in computer vision, particularly deep learning, offer automation potential, yet progress is limited by the lack of publicly available, densely annotated surgical datasets. To address this, we present TEMSET-24K, an open-source dataset comprising 24,306 trans-anal endoscopic microsurgery (TEMS) video micro-clips. Each clip is meticulously annotated by clinical experts using a novel hierarchical labeling taxonomy encompassing phase, task, and action triplets, capturing intricate surgical workflows. To validate this dataset, we benchmarked deep learning models, including transformer-based architectures. Our in silico evaluation demonstrates high accuracy (up to 0.99) and F1 scores (up to 0.99) for key phases like Setup and Suturing. The STALNet model, tested with ConvNeXt, ViT, and SWIN V2 encoders, consistently segmented well-represented phases. TEMSET-24K provides a critical benchmark, propelling state-of-the-art solutions in surgical data science.
Open Foundation Models in Healthcare: Challenges, Paradoxes, and Opportunities with GenAI Driven Personalized Prescription
Feb 04, 2025In response to the success of proprietary Large Language Models (LLMs) such as OpenAI's GPT-4, there is a growing interest in developing open, non-proprietary LLMs and AI foundation models (AIFMs) for transparent use in academic, scientific, and non-commercial applications. Despite their inability to match the refined functionalities of their proprietary counterparts, open models hold immense potential to revolutionize healthcare applications. In this paper, we examine the prospects of open-source LLMs and AIFMs for developing healthcare applications and make two key contributions. Firstly, we present a comprehensive survey of the current state-of-the-art open-source healthcare LLMs and AIFMs and introduce a taxonomy of these open AIFMs, categorizing their utility across various healthcare tasks. Secondly, to evaluate the general-purpose applications of open LLMs in healthcare, we present a case study on personalized prescriptions. This task is particularly significant due to its critical role in delivering tailored, patient-specific medications that can greatly improve treatment outcomes. In addition, we compare the performance of open-source models with proprietary models in settings with and without Retrieval-Augmented Generation (RAG). Our findings suggest that, although less refined, open LLMs can achieve performance comparable to proprietary models when paired with grounding techniques such as RAG. Furthermore, to highlight the clinical significance of LLMs-empowered personalized prescriptions, we perform subjective assessment through an expert clinician. We also elaborate on ethical considerations and potential risks associated with the misuse of powerful LLMs and AIFMs, highlighting the need for a cautious and responsible implementation in healthcare.
R-CONV: An Analytical Approach for Efficient Data Reconstruction via Convolutional Gradients
Jun 06, 2024In the effort to learn from extensive collections of distributed data, federated learning has emerged as a promising approach for preserving privacy by using a gradient-sharing mechanism instead of exchanging raw data. However, recent studies show that private training data can be leaked through many gradient attacks. While previous analytical-based attacks have successfully reconstructed input data from fully connected layers, their effectiveness diminishes when applied to convolutional layers. This paper introduces an advanced data leakage method to efficiently exploit convolutional layers' gradients. We present a surprising finding: even with non-fully invertible activation functions, such as ReLU, we can analytically reconstruct training samples from the gradients. To the best of our knowledge, this is the first analytical approach that successfully reconstructs convolutional layer inputs directly from the gradients, bypassing the need to reconstruct layers' outputs. Prior research has mainly concentrated on the weight constraints of convolution layers, overlooking the significance of gradient constraints. Our findings demonstrate that existing analytical methods used to estimate the risk of gradient attacks lack accuracy. In some layers, attacks can be launched with less than 5% of the reported constraints.
MedISure: Towards Assuring Machine Learning-based Medical Image Classifiers using Mixup Boundary Analysis
Nov 23, 2023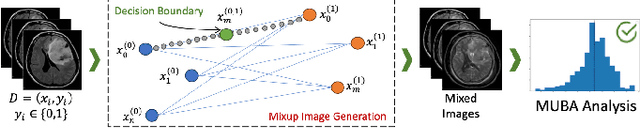
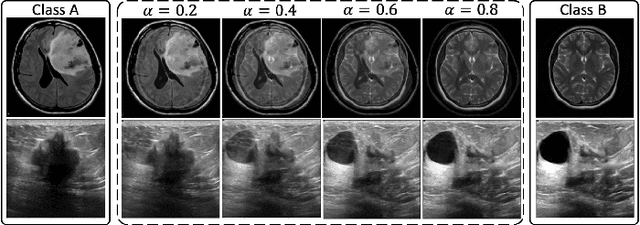
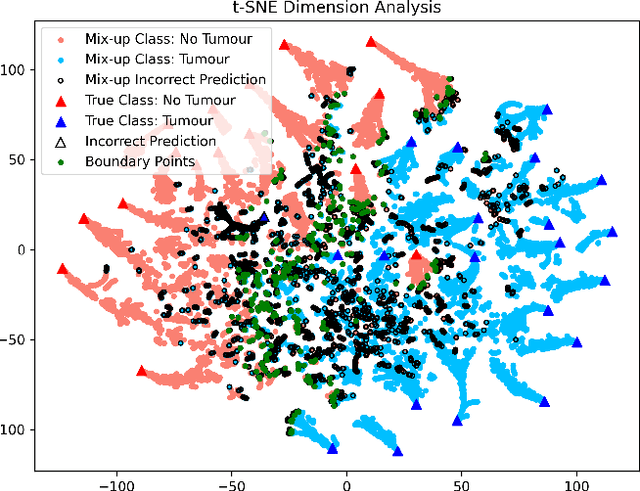
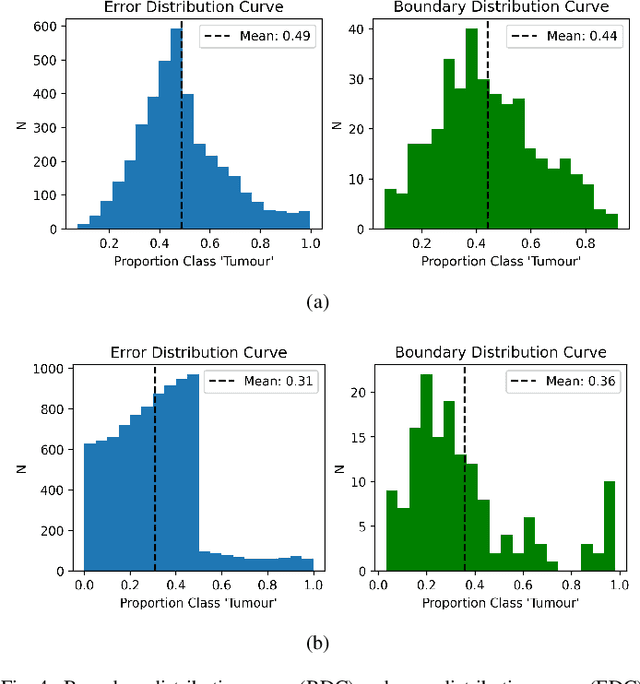
Machine learning (ML) models are becoming integral in healthcare technologies, presenting a critical need for formal assurance to validate their safety, fairness, robustness, and trustworthiness. These models are inherently prone to errors, potentially posing serious risks to patient health and could even cause irreparable harm. Traditional software assurance techniques rely on fixed code and do not directly apply to ML models since these algorithms are adaptable and learn from curated datasets through a training process. However, adapting established principles, such as boundary testing using synthetic test data can effectively bridge this gap. To this end, we present a novel technique called Mix-Up Boundary Analysis (MUBA) that facilitates evaluating image classifiers in terms of prediction fairness. We evaluated MUBA for two important medical imaging tasks -- brain tumour classification and breast cancer classification -- and achieved promising results. This research aims to showcase the importance of adapting traditional assurance principles for assessing ML models to enhance the safety and reliability of healthcare technologies. To facilitate future research, we plan to publicly release our code for MUBA.
Multivessel Coronary Artery Segmentation and Stenosis Localisation using Ensemble Learning
Oct 27, 2023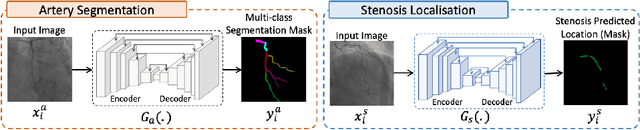
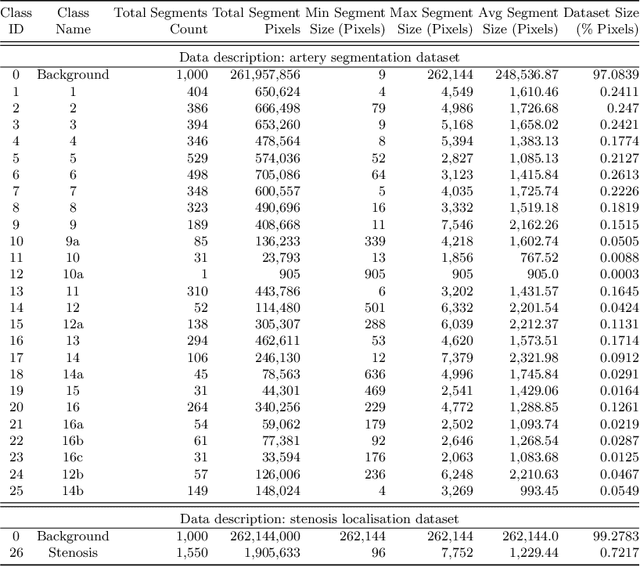

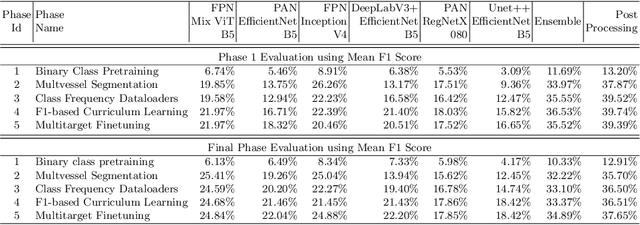
Coronary angiography analysis is a common clinical task performed by cardiologists to diagnose coronary artery disease (CAD) through an assessment of atherosclerotic plaque's accumulation. This study introduces an end-to-end machine learning solution developed as part of our solution for the MICCAI 2023 Automatic Region-based Coronary Artery Disease diagnostics using x-ray angiography imagEs (ARCADE) challenge, which aims to benchmark solutions for multivessel coronary artery segmentation and potential stenotic lesion localisation from X-ray coronary angiograms. We adopted a robust baseline model training strategy to progressively improve performance, comprising five successive stages of binary class pretraining, multivessel segmentation, fine-tuning using class frequency weighted dataloaders, fine-tuning using F1-based curriculum learning strategy (F1-CLS), and finally multi-target angiogram view classifier-based collective adaptation. Unlike many other medical imaging procedures, this task exhibits a notable degree of interobserver variability. %, making it particularly amenable to automated analysis. Our ensemble model combines the outputs from six baseline models using the weighted ensembling approach, which our analysis shows is found to double the predictive accuracy of the proposed solution. The final prediction was further refined, targeting the correction of misclassified blobs. Our solution achieved a mean F1 score of $37.69\%$ for coronary artery segmentation, and $39.41\%$ for stenosis localisation, positioning our team in the 5th position on both leaderboards. This work demonstrates the potential of automated tools to aid CAD diagnosis, guide interventions, and improve the accuracy of stent injections in clinical settings.
Adversarial Machine Learning for Social Good: Reframing the Adversary as an Ally
Oct 05, 2023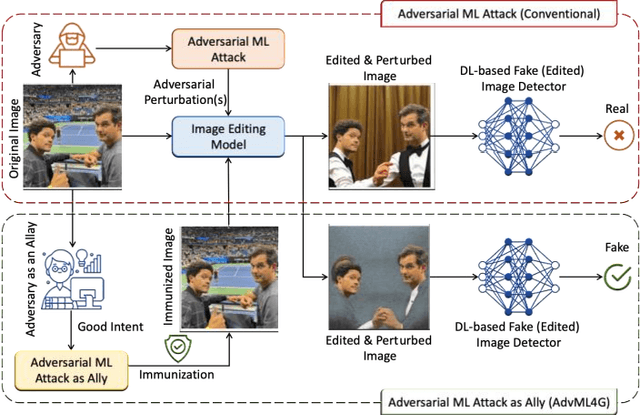
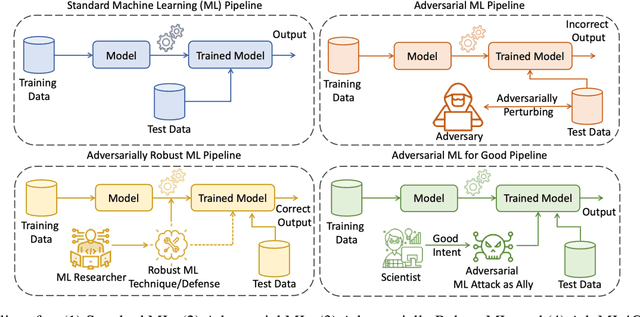
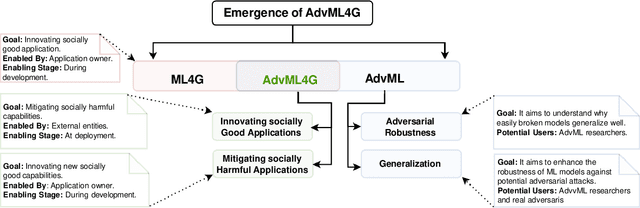
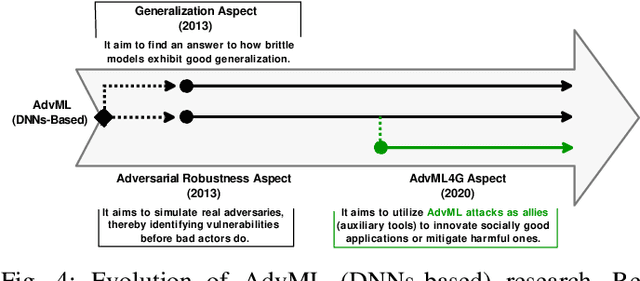
Deep Neural Networks (DNNs) have been the driving force behind many of the recent advances in machine learning. However, research has shown that DNNs are vulnerable to adversarial examples -- input samples that have been perturbed to force DNN-based models to make errors. As a result, Adversarial Machine Learning (AdvML) has gained a lot of attention, and researchers have investigated these vulnerabilities in various settings and modalities. In addition, DNNs have also been found to incorporate embedded bias and often produce unexplainable predictions, which can result in anti-social AI applications. The emergence of new AI technologies that leverage Large Language Models (LLMs), such as ChatGPT and GPT-4, increases the risk of producing anti-social applications at scale. AdvML for Social Good (AdvML4G) is an emerging field that repurposes the AdvML bug to invent pro-social applications. Regulators, practitioners, and researchers should collaborate to encourage the development of pro-social applications and hinder the development of anti-social ones. In this work, we provide the first comprehensive review of the emerging field of AdvML4G. This paper encompasses a taxonomy that highlights the emergence of AdvML4G, a discussion of the differences and similarities between AdvML4G and AdvML, a taxonomy covering social good-related concepts and aspects, an exploration of the motivations behind the emergence of AdvML4G at the intersection of ML4G and AdvML, and an extensive summary of the works that utilize AdvML4G as an auxiliary tool for innovating pro-social applications. Finally, we elaborate upon various challenges and open research issues that require significant attention from the research community.
R2S100K: Road-Region Segmentation Dataset For Semi-Supervised Autonomous Driving in the Wild
Aug 11, 2023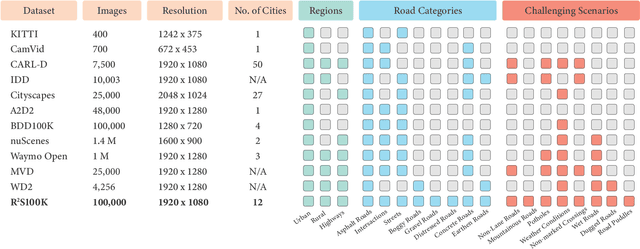
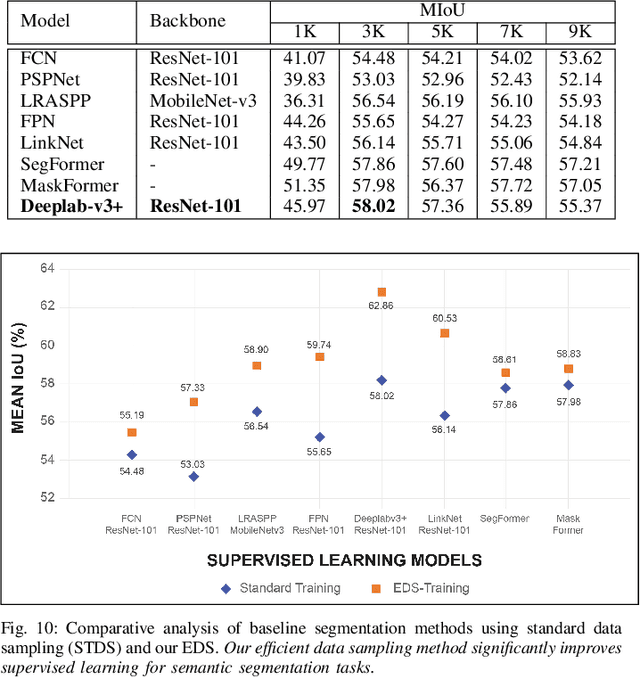


Semantic understanding of roadways is a key enabling factor for safe autonomous driving. However, existing autonomous driving datasets provide well-structured urban roads while ignoring unstructured roadways containing distress, potholes, water puddles, and various kinds of road patches i.e., earthen, gravel etc. To this end, we introduce Road Region Segmentation dataset (R2S100K) -- a large-scale dataset and benchmark for training and evaluation of road segmentation in aforementioned challenging unstructured roadways. R2S100K comprises 100K images extracted from a large and diverse set of video sequences covering more than 1000 KM of roadways. Out of these 100K privacy respecting images, 14,000 images have fine pixel-labeling of road regions, with 86,000 unlabeled images that can be leveraged through semi-supervised learning methods. Alongside, we present an Efficient Data Sampling (EDS) based self-training framework to improve learning by leveraging unlabeled data. Our experimental results demonstrate that the proposed method significantly improves learning methods in generalizability and reduces the labeling cost for semantic segmentation tasks. Our benchmark will be publicly available to facilitate future research at https://r2s100k.github.io/.
Membership Inference Attacks on DNNs using Adversarial Perturbations
Jul 11, 2023



Several membership inference (MI) attacks have been proposed to audit a target DNN. Given a set of subjects, MI attacks tell which subjects the target DNN has seen during training. This work focuses on the post-training MI attacks emphasizing high confidence membership detection -- True Positive Rates (TPR) at low False Positive Rates (FPR). Current works in this category -- likelihood ratio attack (LiRA) and enhanced MI attack (EMIA) -- only perform well on complex datasets (e.g., CIFAR-10 and Imagenet) where the target DNN overfits its train set, but perform poorly on simpler datasets (0% TPR by both attacks on Fashion-MNIST, 2% and 0% TPR respectively by LiRA and EMIA on MNIST at 1% FPR). To address this, firstly, we unify current MI attacks by presenting a framework divided into three stages -- preparation, indication and decision. Secondly, we utilize the framework to propose two novel attacks: (1) Adversarial Membership Inference Attack (AMIA) efficiently utilizes the membership and the non-membership information of the subjects while adversarially minimizing a novel loss function, achieving 6% TPR on both Fashion-MNIST and MNIST datasets; and (2) Enhanced AMIA (E-AMIA) combines EMIA and AMIA to achieve 8% and 4% TPRs on Fashion-MNIST and MNIST datasets respectively, at 1% FPR. Thirdly, we introduce two novel augmented indicators that positively leverage the loss information in the Gaussian neighborhood of a subject. This improves TPR of all four attacks on average by 2.5% and 0.25% respectively on Fashion-MNIST and MNIST datasets at 1% FPR. Finally, we propose simple, yet novel, evaluation metric, the running TPR average (RTA) at a given FPR, that better distinguishes different MI attacks in the low FPR region. We also show that AMIA and E-AMIA are more transferable to the unknown DNNs (other than the target DNN) and are more robust to DP-SGD training as compared to LiRA and EMIA.
Robust Surgical Tools Detection in Endoscopic Videos with Noisy Data
Jul 03, 2023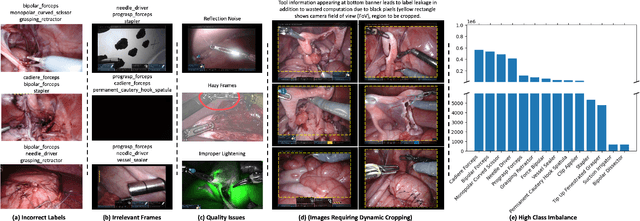
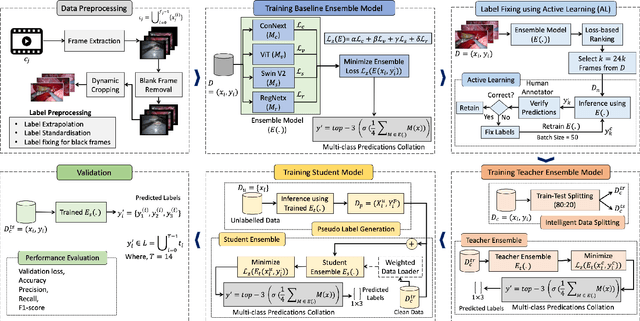
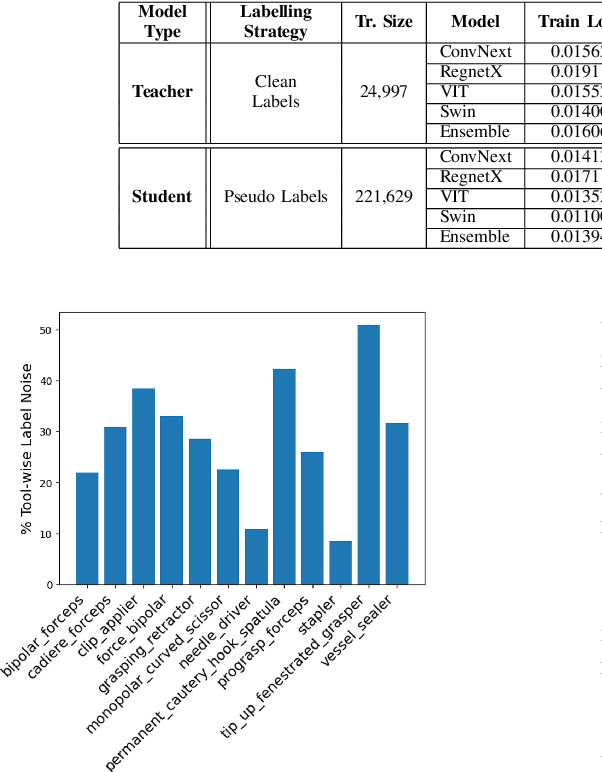
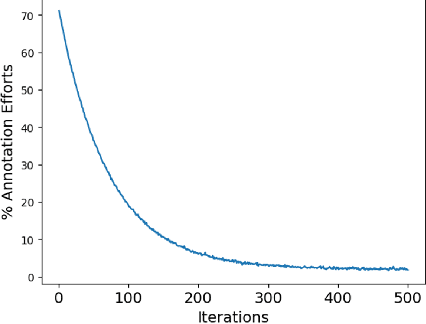
Over the past few years, surgical data science has attracted substantial interest from the machine learning (ML) community. Various studies have demonstrated the efficacy of emerging ML techniques in analysing surgical data, particularly recordings of procedures, for digitizing clinical and non-clinical functions like preoperative planning, context-aware decision-making, and operating skill assessment. However, this field is still in its infancy and lacks representative, well-annotated datasets for training robust models in intermediate ML tasks. Also, existing datasets suffer from inaccurate labels, hindering the development of reliable models. In this paper, we propose a systematic methodology for developing robust models for surgical tool detection using noisy data. Our methodology introduces two key innovations: (1) an intelligent active learning strategy for minimal dataset identification and label correction by human experts; and (2) an assembling strategy for a student-teacher model-based self-training framework to achieve the robust classification of 14 surgical tools in a semi-supervised fashion. Furthermore, we employ weighted data loaders to handle difficult class labels and address class imbalance issues. The proposed methodology achieves an average F1-score of 85.88\% for the ensemble model-based self-training with class weights, and 80.88\% without class weights for noisy labels. Also, our proposed method significantly outperforms existing approaches, which effectively demonstrates its effectiveness.
Can We Revitalize Interventional Healthcare with AI-XR Surgical Metaverses?
Mar 25, 2023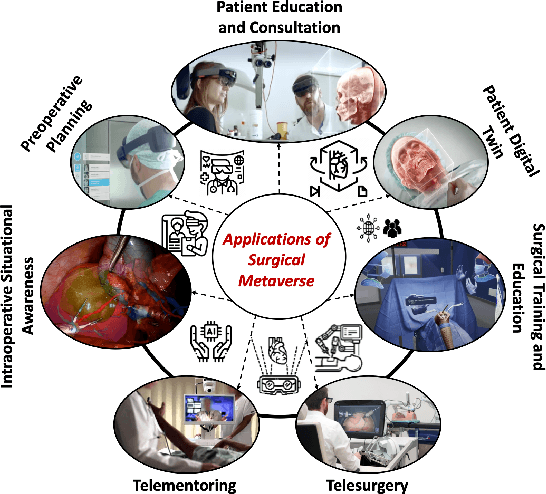

Recent advancements in technology, particularly in machine learning (ML), deep learning (DL), and the metaverse, offer great potential for revolutionizing surgical science. The combination of artificial intelligence and extended reality (AI-XR) technologies has the potential to create a surgical metaverse, a virtual environment where surgeries can be planned and performed. This paper aims to provide insight into the various potential applications of an AI-XR surgical metaverse and the challenges that must be addressed to bring its full potential to fruition. It is important for the community to focus on these challenges to fully realize the potential of the AI-XR surgical metaverses. Furthermore, to emphasize the need for secure and robust AI-XR surgical metaverses and to demonstrate the real-world implications of security threats to the AI-XR surgical metaverses, we present a case study in which the ``an immersive surgical attack'' on incision point localization is performed in the context of preoperative planning in a surgical metaverse.