 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding a Robust Risk-Based Access Control System to Combat Ransomware's Capability to Encrypt: A Machine Learning Approach
Jan 23, 2026Ransomware core capability, unauthorized encryption, demands controls that identify and block malicious cryptographic activity without disrupting legitimate use. We present a probabilistic, risk-based access control architecture that couples machine learning inference with mandatory access control to regulate encryption on Linux in real time. The system builds a specialized dataset from the native ftrace framework using the function_graph tracer, yielding high-resolution kernel-function execution traces augmented with resource and I/O counters. These traces support both a supervised classifier and interpretable rules that drive an SELinux policy via lightweight booleans, enabling context-sensitive permit/deny decisions at the moment encryption begins. Compared to approaches centered on sandboxing, hypervisor introspection, or coarse system-call telemetry, the function-level tracing we adopt provides finer behavioral granularity than syscall-only telemetry while avoiding the virtualization/VMI overhead of sandbox-based approaches. Our current user-space prototype has a non-trivial footprint under burst I/O; we quantify it and recognize that a production kernel-space solution should aim to address this. We detail dataset construction, model training and rule extraction, and the run-time integration that gates file writes for suspect encryption while preserving benign cryptographic workflows. During evaluation, the two-layer composition retains model-level detection quality while delivering rule-like responsiveness; we also quantify operational footprint and outline engineering steps to reduce CPU and memory overhead for enterprise deployment. The result is a practical path from behavioral tracing and learning to enforceable, explainable, and risk-proportionate encryption control on production Linux systems.
R-CONV: An Analytical Approach for Efficient Data Reconstruction via Convolutional Gradients
Jun 06, 2024In the effort to learn from extensive collections of distributed data, federated learning has emerged as a promising approach for preserving privacy by using a gradient-sharing mechanism instead of exchanging raw data. However, recent studies show that private training data can be leaked through many gradient attacks. While previous analytical-based attacks have successfully reconstructed input data from fully connected layers, their effectiveness diminishes when applied to convolutional layers. This paper introduces an advanced data leakage method to efficiently exploit convolutional layers' gradients. We present a surprising finding: even with non-fully invertible activation functions, such as ReLU, we can analytically reconstruct training samples from the gradients. To the best of our knowledge, this is the first analytical approach that successfully reconstructs convolutional layer inputs directly from the gradients, bypassing the need to reconstruct layers' outputs. Prior research has mainly concentrated on the weight constraints of convolution layers, overlooking the significance of gradient constraints. Our findings demonstrate that existing analytical methods used to estimate the risk of gradient attacks lack accuracy. In some layers, attacks can be launched with less than 5% of the reported constraints.
A Blackbox Model Is All You Need to Breach Privacy: Smart Grid Forecasting Models as a Use Case
Sep 04, 2023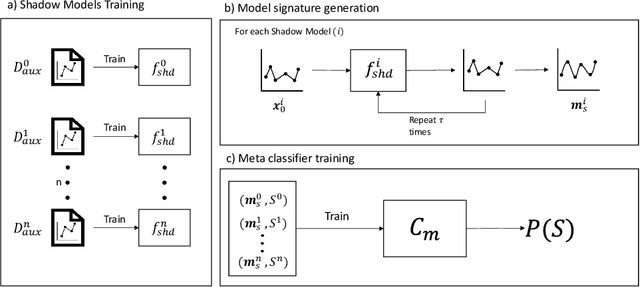
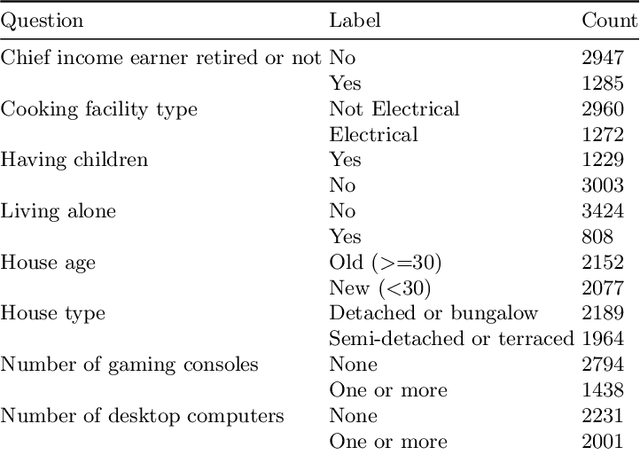
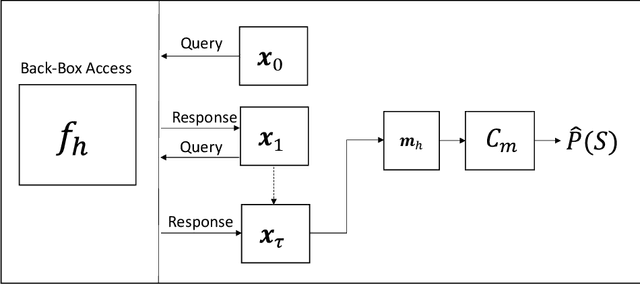
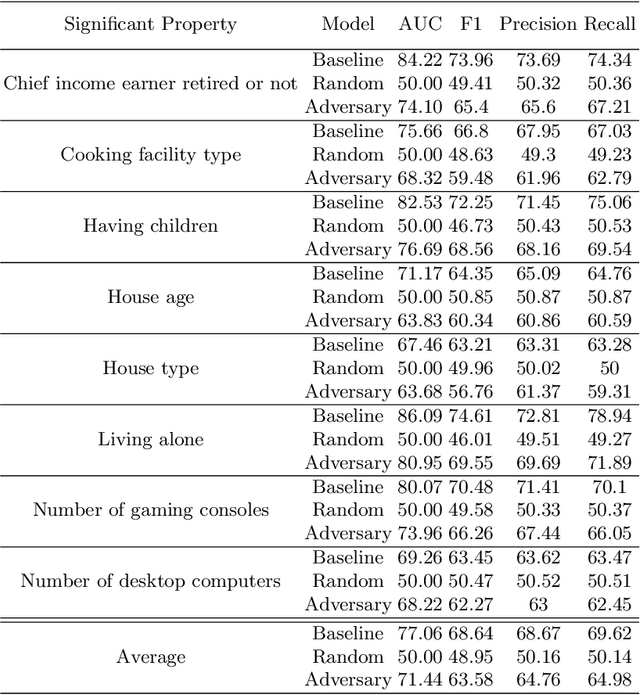
This paper investigates the potential privacy risks associated with forecasting models, with specific emphasis on their application in the context of smart grids. While machine learning and deep learning algorithms offer valuable utility, concerns arise regarding their exposure of sensitive information. Previous studies have focused on classification models, overlooking risks associated with forecasting models. Deep learning based forecasting models, such as Long Short Term Memory (LSTM), play a crucial role in several applications including optimizing smart grid systems but also introduce privacy risks. Our study analyzes the ability of forecasting models to leak global properties and privacy threats in smart grid systems. We demonstrate that a black box access to an LSTM model can reveal a significant amount of information equivalent to having access to the data itself (with the difference being as low as 1% in Area Under the ROC Curve). This highlights the importance of protecting forecasting models at the same level as the data.