 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUni-Hema: Unified Model for Digital Hematopathology
Nov 19, 2025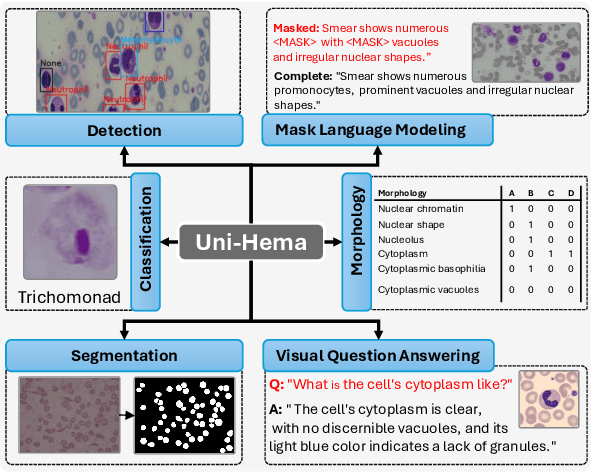
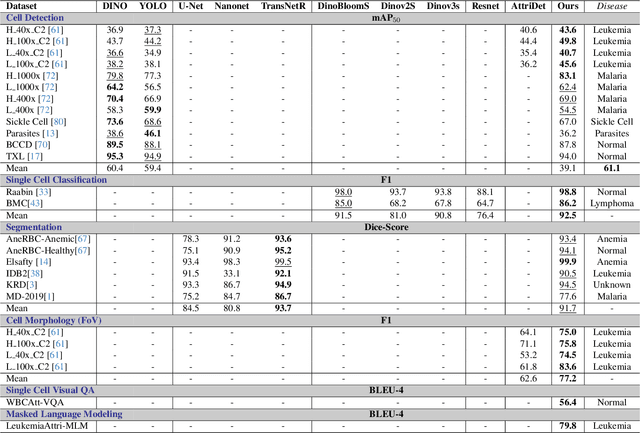
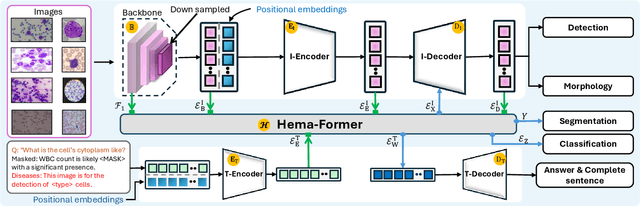
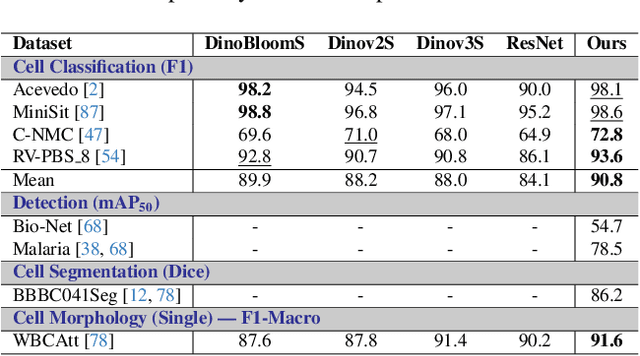
Digital hematopathology requires cell-level analysis across diverse disease categories, including malignant disorders (e.g., leukemia), infectious conditions (e.g., malaria), and non-malignant red blood cell disorders (e.g., sickle cell disease). Whether single-task, vision-language, WSI-optimized, or single-cell hematology models, these approaches share a key limitation, they cannot provide unified, multi-task, multi-modal reasoning across the complexities of digital hematopathology. To overcome these limitations, we propose Uni-Hema, a multi-task, unified model for digital hematopathology integrating detection, classification, segmentation, morphology prediction, and reasoning across multiple diseases. Uni-Hema leverages 46 publicly available datasets, encompassing over 700K images and 21K question-answer pairs, and is built upon Hema-Former, a multimodal module that bridges visual and textual representations at the hierarchy level for the different tasks (detection, classification, segmentation, morphology, mask language modeling and visual question answer) at different granularity. Extensive experiments demonstrate that Uni-Hema achieves comparable or superior performance to train on a single-task and single dataset models, across diverse hematological tasks, while providing interpretable, morphologically relevant insights at the single-cell level. Our framework establishes a new standard for multi-task and multi-modal digital hematopathology. The code will be made publicly available.
Leveraging Sparse Annotations for Leukemia Diagnosis on the Large Leukemia Dataset
Apr 03, 2025Leukemia is 10th most frequently diagnosed cancer and one of the leading causes of cancer related deaths worldwide. Realistic analysis of Leukemia requires White Blook Cells (WBC) localization, classification, and morphological assessment. Despite deep learning advances in medical imaging, leukemia analysis lacks a large, diverse multi-task dataset, while existing small datasets lack domain diversity, limiting real world applicability. To overcome dataset challenges, we present a large scale WBC dataset named Large Leukemia Dataset (LLD) and novel methods for detecting WBC with their attributes. Our contribution here is threefold. First, we present a large-scale Leukemia dataset collected through Peripheral Blood Films (PBF) from several patients, through multiple microscopes, multi cameras, and multi magnification. To enhance diagnosis explainability and medical expert acceptance, each leukemia cell is annotated at 100x with 7 morphological attributes, ranging from Cell Size to Nuclear Shape. Secondly, we propose a multi task model that not only detects WBCs but also predicts their attributes, providing an interpretable and clinically meaningful solution. Third, we propose a method for WBC detection with attribute analysis using sparse annotations. This approach reduces the annotation burden on hematologists, requiring them to mark only a small area within the field of view. Our method enables the model to leverage the entire field of view rather than just the annotated regions, enhancing learning efficiency and diagnostic accuracy. From diagnosis explainability to overcoming domain shift challenges, presented datasets could be used for many challenging aspects of microscopic image analysis. The datasets, code, and demo are available at: https://im.itu.edu.pk/sparse-leukemiaattri/
MIAdapt: Source-free Few-shot Domain Adaptive Object Detection for Microscopic Images
Mar 05, 2025Existing generic unsupervised domain adaptation approaches require access to both a large labeled source dataset and a sufficient unlabeled target dataset during adaptation. However, collecting a large dataset, even if unlabeled, is a challenging and expensive endeavor, especially in medical imaging. In addition, constraints such as privacy issues can result in cases where source data is unavailable. Taking in consideration these challenges, we propose MIAdapt, an adaptive approach for Microscopic Imagery Adaptation as a solution for Source-free Few-shot Domain Adaptive Object detection (SF-FSDA). We also define two competitive baselines (1) Faster-FreeShot and (2) MT-FreeShot. Extensive experiments on the challenging M5-Malaria and Raabin-WBC datasets validate the effectiveness of MIAdapt. Without using any image from the source domain MIAdapt surpasses state-of-the-art source-free UDA (SF-UDA) methods by +21.3% mAP and few-shot domain adaptation (FSDA) approaches by +4.7% mAP on Raabin-WBC. Our code and models will be publicly available.
Few-Shot Domain Adaptive Object Detection for Microscopic Images
Jul 10, 2024
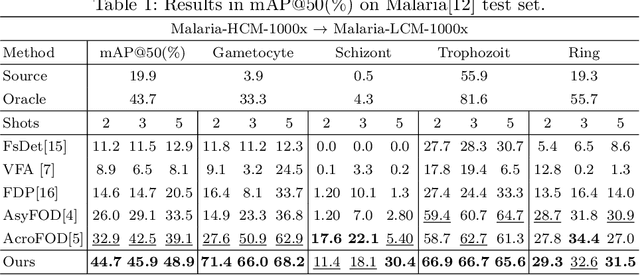

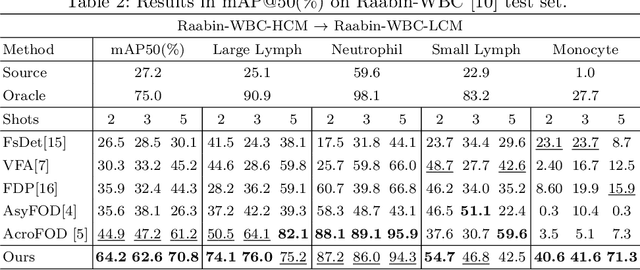
In recent years, numerous domain adaptive strategies have been proposed to help deep learning models overcome the challenges posed by domain shift. However, even unsupervised domain adaptive strategies still require a large amount of target data. Medical imaging datasets are often characterized by class imbalance and scarcity of labeled and unlabeled data. Few-shot domain adaptive object detection (FSDAOD) addresses the challenge of adapting object detectors to target domains with limited labeled data. Existing works struggle with randomly selected target domain images that may not accurately represent the real population, resulting in overfitting to small validation sets and poor generalization to larger test sets. Medical datasets exhibit high class imbalance and background similarity, leading to increased false positives and lower mean Average Precision (map) in target domains. To overcome these challenges, we propose a novel FSDAOD strategy for microscopic imaging. Our contributions include a domain adaptive class balancing strategy for few-shot scenarios, multi-layer instance-level inter and intra-domain alignment to enhance similarity between class instances regardless of domain, and an instance-level classification loss applied in the middle layers of the object detector to enforce feature retention necessary for correct classification across domains. Extensive experimental results with competitive baselines demonstrate the effectiveness of our approach, achieving state-of-the-art results on two public microscopic datasets. Code available at https://github.co/intelligentMachinesLab/few-shot-domain-adaptive-microscopy
Joint Stream: Malignant Region Learning for Breast Cancer Diagnosis
Jun 26, 2024



Early diagnosis of breast cancer (BC) significantly contributes to reducing the mortality rate worldwide. The detection of different factors and biomarkers such as Estrogen receptor (ER), Progesterone receptor (PR), Human epidermal growth factor receptor 2 (HER2) gene, Histological grade (HG), Auxiliary lymph node (ALN) status, and Molecular subtype (MS) can play a significant role in improved BC diagnosis. However, the existing methods predict only a single factor which makes them less suitable to use in diagnosis and designing a strategy for treatment. In this paper, we propose to classify the six essential indicating factors (ER, PR, HER2, ALN, HG, MS) for early BC diagnosis using H\&E stained WSI's. To precisely capture local neighboring relationships, we use spatial and frequency domain information from the large patch size of WSI's malignant regions. Furthermore, to cater the variable number of regions of interest sizes and give due attention to each region, we propose a malignant region learning attention network. Our experimental results demonstrate that combining spatial and frequency information using the malignant region learning module significantly improves multi-factor and single-factor classification performance on publicly available datasets.
A Large-scale Multi Domain Leukemia Dataset for the White Blood Cells Detection with Morphological Attributes for Explainability
May 17, 2024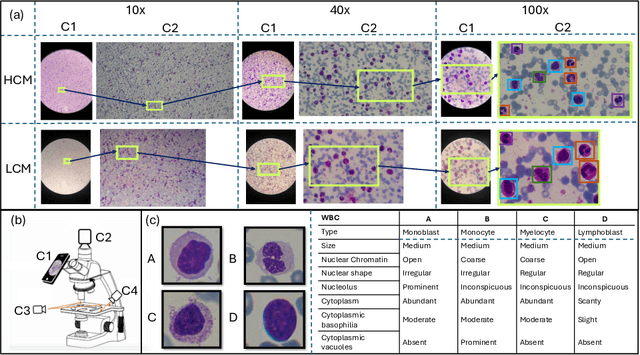
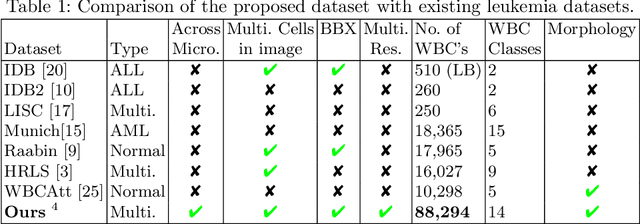
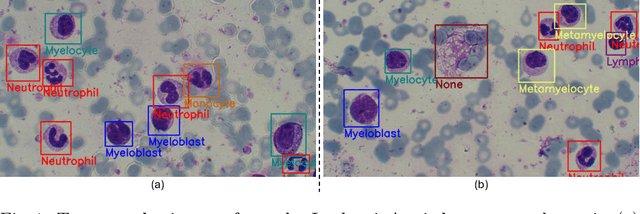
Earlier diagnosis of Leukemia can save thousands of lives annually. The prognosis of leukemia is challenging without the morphological information of White Blood Cells (WBC) and relies on the accessibility of expensive microscopes and the availability of hematologists to analyze Peripheral Blood Samples (PBS). Deep Learning based methods can be employed to assist hematologists. However, these algorithms require a large amount of labeled data, which is not readily available. To overcome this limitation, we have acquired a realistic, generalized, and large dataset. To collect this comprehensive dataset for real-world applications, two microscopes from two different cost spectrums (high-cost HCM and low-cost LCM) are used for dataset capturing at three magnifications (100x, 40x, 10x) through different sensors (high-end camera for HCM, middle-level camera for LCM and mobile-phone camera for both). The high-sensor camera is 47 times more expensive than the middle-level camera and HCM is 17 times more expensive than LCM. In this collection, using HCM at high resolution (100x), experienced hematologists annotated 10.3k WBC types (14) and artifacts, having 55k morphological labels (Cell Size, Nuclear Chromatin, Nuclear Shape, etc.) from 2.4k images of several PBS leukemia patients. Later on, these annotations are transferred to other 2 magnifications of HCM, and 3 magnifications of LCM, and on each camera captured images. Along with the LeukemiaAttri dataset, we provide baselines over multiple object detectors and Unsupervised Domain Adaptation (UDA) strategies, along with morphological information-based attribute prediction. The dataset will be publicly available after publication to facilitate the research in this direction.
Leveraging Topology for Domain Adaptive Road Segmentation in Satellite and Aerial Imagery
Sep 27, 2023Getting precise aspects of road through segmentation from remote sensing imagery is useful for many real-world applications such as autonomous vehicles, urban development and planning, and achieving sustainable development goals. Roads are only a small part of the image, and their appearance, type, width, elevation, directions, etc. exhibit large variations across geographical areas. Furthermore, due to differences in urbanization styles, planning, and the natural environments; regions along the roads vary significantly. Due to these variations among the train and test domains, the road segmentation algorithms fail to generalize to new geographical locations. Unlike the generic domain alignment scenarios, road segmentation has no scene structure, and generic domain adaptation methods are unable to enforce topological properties like continuity, connectivity, smoothness, etc., thus resulting in degraded domain alignment. In this work, we propose a topology-aware unsupervised domain adaptation approach for road segmentation in remote sensing imagery. Specifically, we predict road skeleton, an auxiliary task to impose the topological constraints. To enforce consistent predictions of road and skeleton, especially in the unlabeled target domain, the conformity loss is defined across the skeleton prediction head and the road-segmentation head. Furthermore, for self-training, we filter out the noisy pseudo-labels by using a connectivity-based pseudo-labels refinement strategy, on both road and skeleton segmentation heads, thus avoiding holes and discontinuities. Extensive experiments on the benchmark datasets show the effectiveness of the proposed approach compared to existing state-of-the-art methods. Specifically, for SpaceNet to DeepGlobe adaptation, the proposed approach outperforms the competing methods by a minimum margin of 6.6%, 6.7%, and 9.8% in IoU, F1-score, and APLS, respectively.
GeoDTR+: Toward generic cross-view geolocalization via geometric disentanglement
Aug 18, 2023Cross-View Geo-Localization (CVGL) estimates the location of a ground image by matching it to a geo-tagged aerial image in a database. Recent works achieve outstanding progress on CVGL benchmarks. However, existing methods still suffer from poor performance in cross-area evaluation, in which the training and testing data are captured from completely distinct areas. We attribute this deficiency to the lack of ability to extract the geometric layout of visual features and models' overfitting to low-level details. Our preliminary work introduced a Geometric Layout Extractor (GLE) to capture the geometric layout from input features. However, the previous GLE does not fully exploit information in the input feature. In this work, we propose GeoDTR+ with an enhanced GLE module that better models the correlations among visual features. To fully explore the LS techniques from our preliminary work, we further propose Contrastive Hard Samples Generation (CHSG) to facilitate model training. Extensive experiments show that GeoDTR+ achieves state-of-the-art (SOTA) results in cross-area evaluation on CVUSA, CVACT, and VIGOR by a large margin ($16.44\%$, $22.71\%$, and $17.02\%$ without polar transformation) while keeping the same-area performance comparable to existing SOTA. Moreover, we provide detailed analyses of GeoDTR+.
R2S100K: Road-Region Segmentation Dataset For Semi-Supervised Autonomous Driving in the Wild
Aug 11, 2023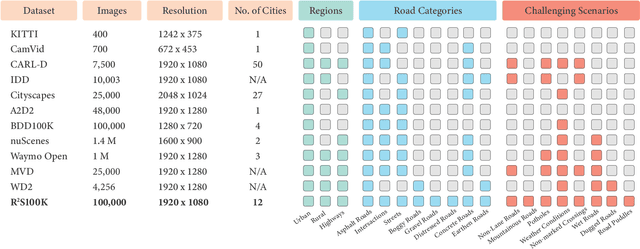
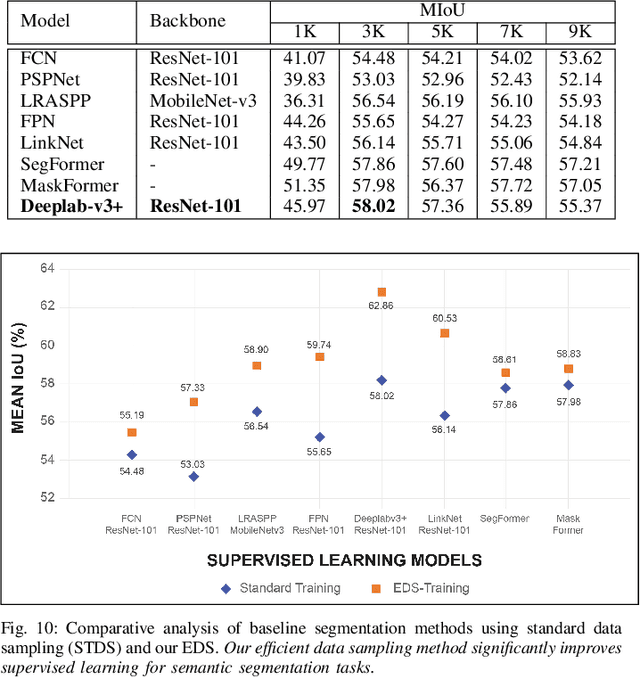


Semantic understanding of roadways is a key enabling factor for safe autonomous driving. However, existing autonomous driving datasets provide well-structured urban roads while ignoring unstructured roadways containing distress, potholes, water puddles, and various kinds of road patches i.e., earthen, gravel etc. To this end, we introduce Road Region Segmentation dataset (R2S100K) -- a large-scale dataset and benchmark for training and evaluation of road segmentation in aforementioned challenging unstructured roadways. R2S100K comprises 100K images extracted from a large and diverse set of video sequences covering more than 1000 KM of roadways. Out of these 100K privacy respecting images, 14,000 images have fine pixel-labeling of road regions, with 86,000 unlabeled images that can be leveraged through semi-supervised learning methods. Alongside, we present an Efficient Data Sampling (EDS) based self-training framework to improve learning by leveraging unlabeled data. Our experimental results demonstrate that the proposed method significantly improves learning methods in generalizability and reduces the labeling cost for semantic segmentation tasks. Our benchmark will be publicly available to facilitate future research at https://r2s100k.github.io/.
Cross-view Geo-localization via Learning Disentangled Geometric Layout Correspondence
Dec 20, 2022



Cross-view geo-localization aims to estimate the location of a query ground image by matching it to a reference geo-tagged aerial images database. As an extremely challenging task, its difficulties root in the drastic view changes and different capturing time between two views. Despite these difficulties, recent works achieve outstanding progress on cross-view geo-localization benchmarks. However, existing methods still suffer from poor performance on the cross-area benchmarks, in which the training and testing data are captured from two different regions. We attribute this deficiency to the lack of ability to extract the spatial configuration of visual feature layouts and models' overfitting on low-level details from the training set. In this paper, we propose GeoDTR which explicitly disentangles geometric information from raw features and learns the spatial correlations among visual features from aerial and ground pairs with a novel geometric layout extractor module. This module generates a set of geometric layout descriptors, modulating the raw features and producing high-quality latent representations. In addition, we elaborate on two categories of data augmentations, (i) Layout simulation, which varies the spatial configuration while keeping the low-level details intact. (ii) Semantic augmentation, which alters the low-level details and encourages the model to capture spatial configurations. These augmentations help to improve the performance of the cross-view geo-localization models, especially on the cross-area benchmarks. Moreover, we propose a counterfactual-based learning process to benefit the geometric layout extractor in exploring spatial information. Extensive experiments show that GeoDTR not only achieves state-of-the-art results but also significantly boosts the performance on same-area and cross-area benchmarks.