 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNumColor: Precise Numeric Color Control in Text-to-Image Generation
Mar 13, 2026Text-to-image diffusion models excel at generating images from natural language descriptions, yet fail to interpret numerical colors such as hex codes (#FF5733) and RGB values (rgb(255,87,51)). This limitation stems from subword tokenization, which fragments color codes into semantically meaningless tokens that text encoders cannot map to coherent color representations. We present NumColor, that enables precise numerical color control across multiple diffusion architectures. NumColor comprises two components: a Color Token Aggregator that detects color specifications regardless of tokenization, and a ColorBook containing 6,707 learnable embeddings that map colors to embedding space of text encoder in perceptually uniform CIE Lab space. We introduce two auxiliary losses, directional alignment and interpolation consistency, to enforce geometric correspondence between Lab and embedding spaces, enabling smooth color interpolation. To train the ColorBook, we construct NumColor-Data, a synthetic dataset of 500K rendered images with unambiguous color-to-pixel correspondence, eliminating the annotation ambiguity inherent in photographic datasets. Although trained solely on FLUX, NumColor transfers zero-shot to SD3, SD3.5, PixArt-α, and PixArt-Σ without model-specific adaptation. NumColor improves numerical color accuracy by 4-9x across five models, while simultaneously improving color harmony scores by 10-30x on GenColorBench benchmark.
LumiCtrl : Learning Illuminant Prompts for Lighting Control in Personalized Text-to-Image Models
Dec 19, 2025Current text-to-image (T2I) models have demonstrated remarkable progress in creative image generation, yet they still lack precise control over scene illuminants, which is a crucial factor for content designers aiming to manipulate the mood, atmosphere, and visual aesthetics of generated images. In this paper, we present an illuminant personalization method named LumiCtrl that learns an illuminant prompt given a single image of an object. LumiCtrl consists of three basic components: given an image of the object, our method applies (a) physics-based illuminant augmentation along the Planckian locus to create fine-tuning variants under standard illuminants; (b) edge-guided prompt disentanglement using a frozen ControlNet to ensure prompts focus on illumination rather than structure; and (c) a masked reconstruction loss that focuses learning on the foreground object while allowing the background to adapt contextually, enabling what we call contextual light adaptation. We qualitatively and quantitatively compare LumiCtrl against other T2I customization methods. The results show that our method achieves significantly better illuminant fidelity, aesthetic quality, and scene coherence compared to existing personalization baselines. A human preference study further confirms strong user preference for LumiCtrl outputs. The code and data will be released upon publication.
GenColorBench: A Color Evaluation Benchmark for Text-to-Image Generation Models
Oct 23, 2025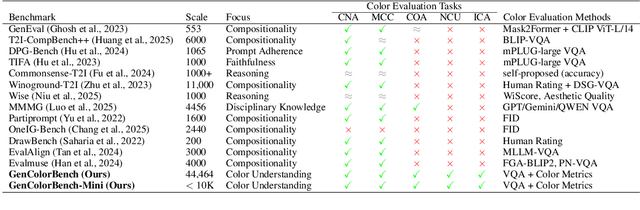

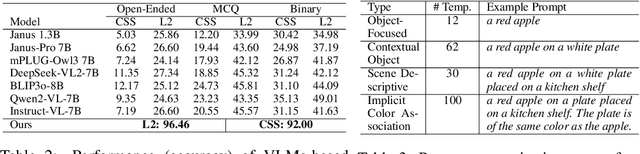
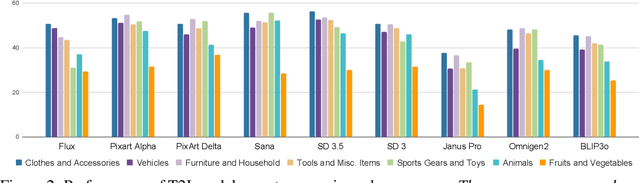
Recent years have seen impressive advances in text-to-image generation, with image generative or unified models producing high-quality images from text. Yet these models still struggle with fine-grained color controllability, often failing to accurately match colors specified in text prompts. While existing benchmarks evaluate compositional reasoning and prompt adherence, none systematically assess color precision. Color is fundamental to human visual perception and communication, critical for applications from art to design workflows requiring brand consistency. However, current benchmarks either neglect color or rely on coarse assessments, missing key capabilities such as interpreting RGB values or aligning with human expectations. To this end, we propose GenColorBench, the first comprehensive benchmark for text-to-image color generation, grounded in color systems like ISCC-NBS and CSS3/X11, including numerical colors which are absent elsewhere. With 44K color-focused prompts covering 400+ colors, it reveals models' true capabilities via perceptual and automated assessments. Evaluations of popular text-to-image models using GenColorBench show performance variations, highlighting which color conventions models understand best and identifying failure modes. Our GenColorBench assessments will guide improvements in precise color generation. The benchmark will be made public upon acceptance.
Color Names in Vision-Language Models
Sep 26, 2025Color serves as a fundamental dimension of human visual perception and a primary means of communicating about objects and scenes. As vision-language models (VLMs) become increasingly prevalent, understanding whether they name colors like humans is crucial for effective human-AI interaction. We present the first systematic evaluation of color naming capabilities across VLMs, replicating classic color naming methodologies using 957 color samples across five representative models. Our results show that while VLMs achieve high accuracy on prototypical colors from classical studies, performance drops significantly on expanded, non-prototypical color sets. We identify 21 common color terms that consistently emerge across all models, revealing two distinct approaches: constrained models using predominantly basic terms versus expansive models employing systematic lightness modifiers. Cross-linguistic analysis across nine languages demonstrates severe training imbalances favoring English and Chinese, with hue serving as the primary driver of color naming decisions. Finally, ablation studies reveal that language model architecture significantly influences color naming independent of visual processing capabilities.
An h-space Based Adversarial Attack for Protection Against Few-shot Personalization
Jul 23, 2025The versatility of diffusion models in generating customized images from few samples raises significant privacy concerns, particularly regarding unauthorized modifications of private content. This concerning issue has renewed the efforts in developing protection mechanisms based on adversarial attacks, which generate effective perturbations to poison diffusion models. Our work is motivated by the observation that these models exhibit a high degree of abstraction within their semantic latent space (`h-space'), which encodes critical high-level features for generating coherent and meaningful content. In this paper, we propose a novel anti-customization approach, called HAAD (h-space based Adversarial Attack for Diffusion models), that leverages adversarial attacks to craft perturbations based on the h-space that can efficiently degrade the image generation process. Building upon HAAD, we further introduce a more efficient variant, HAAD-KV, that constructs perturbations solely based on the KV parameters of the h-space. This strategy offers a stronger protection, that is computationally less expensive. Despite their simplicity, our methods outperform state-of-the-art adversarial attacks, highlighting their effectiveness.
Leveraging Semantic Attribute Binding for Free-Lunch Color Control in Diffusion Models
Mar 12, 2025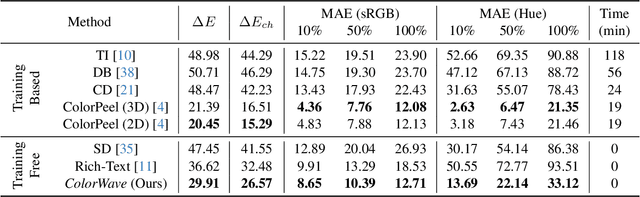
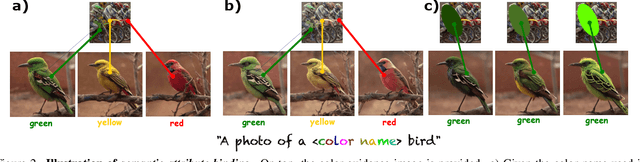
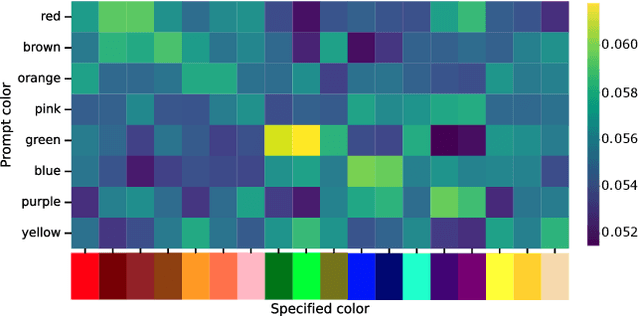
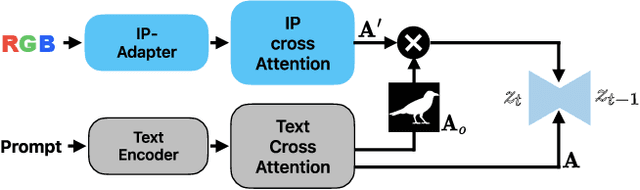
Recent advances in text-to-image (T2I) diffusion models have enabled remarkable control over various attributes, yet precise color specification remains a fundamental challenge. Existing approaches, such as ColorPeel, rely on model personalization, requiring additional optimization and limiting flexibility in specifying arbitrary colors. In this work, we introduce ColorWave, a novel training-free approach that achieves exact RGB-level color control in diffusion models without fine-tuning. By systematically analyzing the cross-attention mechanisms within IP-Adapter, we uncover an implicit binding between textual color descriptors and reference image features. Leveraging this insight, our method rewires these bindings to enforce precise color attribution while preserving the generative capabilities of pretrained models. Our approach maintains generation quality and diversity, outperforming prior methods in accuracy and applicability across diverse object categories. Through extensive evaluations, we demonstrate that ColorWave establishes a new paradigm for structured, color-consistent diffusion-based image synthesis.
Privacy Protection in Personalized Diffusion Models via Targeted Cross-Attention Adversarial Attack
Nov 25, 2024



The growing demand for customized visual content has led to the rise of personalized text-to-image (T2I) diffusion models. Despite their remarkable potential, they pose significant privacy risk when misused for malicious purposes. In this paper, we propose a novel and efficient adversarial attack method, Concept Protection by Selective Attention Manipulation (CoPSAM) which targets only the cross-attention layers of a T2I diffusion model. For this purpose, we carefully construct an imperceptible noise to be added to clean samples to get their adversarial counterparts. This is obtained during the fine-tuning process by maximizing the discrepancy between the corresponding cross-attention maps of the user-specific token and the class-specific token, respectively. Experimental validation on a subset of CelebA-HQ face images dataset demonstrates that our approach outperforms existing methods. Besides this, our method presents two important advantages derived from the qualitative evaluation: (i) we obtain better protection results for lower noise levels than our competitors; and (ii) we protect the content from unauthorized use thereby protecting the individual's identity from potential misuse.
ColorPeel: Color Prompt Learning with Diffusion Models via Color and Shape Disentanglement
Jul 09, 2024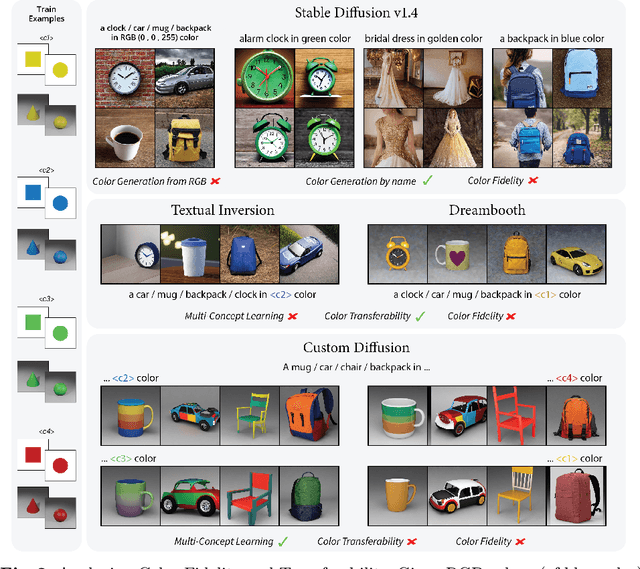
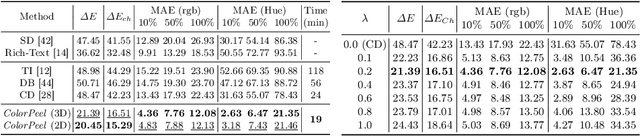
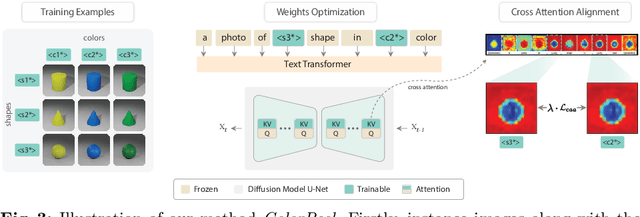
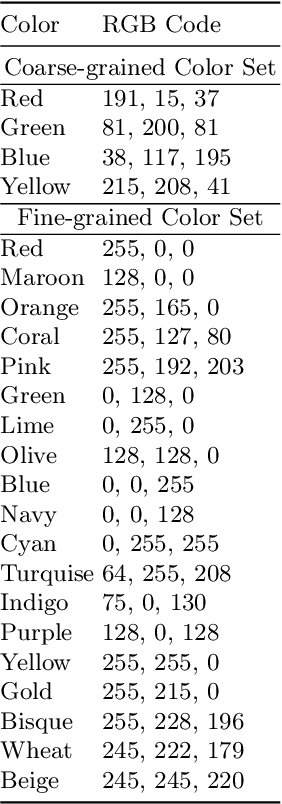
Text-to-Image (T2I) generation has made significant advancements with the advent of diffusion models. These models exhibit remarkable abilities to produce images based on textual prompts. Current T2I models allow users to specify object colors using linguistic color names. However, these labels encompass broad color ranges, making it difficult to achieve precise color matching. To tackle this challenging task, named color prompt learning, we propose to learn specific color prompts tailored to user-selected colors. Existing T2I personalization methods tend to result in color-shape entanglement. To overcome this, we generate several basic geometric objects in the target color, allowing for color and shape disentanglement during the color prompt learning. Our method, denoted as ColorPeel, successfully assists the T2I models to peel off the novel color prompts from these colored shapes. In the experiments, we demonstrate the efficacy of ColorPeel in achieving precise color generation with T2I models. Furthermore, we generalize ColorPeel to effectively learn abstract attribute concepts, including textures, materials, etc. Our findings represent a significant step towards improving precision and versatility of T2I models, offering new opportunities for creative applications and design tasks. Our project is available at https://moatifbutt.github.io/colorpeel/.
Dynamic Prompt Learning: Addressing Cross-Attention Leakage for Text-Based Image Editing
Sep 27, 2023Large-scale text-to-image generative models have been a ground-breaking development in generative AI, with diffusion models showing their astounding ability to synthesize convincing images following an input text prompt. The goal of image editing research is to give users control over the generated images by modifying the text prompt. Current image editing techniques are susceptible to unintended modifications of regions outside the targeted area, such as on the background or on distractor objects which have some semantic or visual relationship with the targeted object. According to our experimental findings, inaccurate cross-attention maps are at the root of this problem. Based on this observation, we propose Dynamic Prompt Learning (DPL) to force cross-attention maps to focus on correct noun words in the text prompt. By updating the dynamic tokens for nouns in the textual input with the proposed leakage repairment losses, we achieve fine-grained image editing over particular objects while preventing undesired changes to other image regions. Our method DPL, based on the publicly available Stable Diffusion, is extensively evaluated on a wide range of images, and consistently obtains superior results both quantitatively (CLIP score, Structure-Dist) and qualitatively (on user-evaluation). We show improved prompt editing results for Word-Swap, Prompt Refinement, and Attention Re-weighting, especially for complex multi-object scenes.
R2S100K: Road-Region Segmentation Dataset For Semi-Supervised Autonomous Driving in the Wild
Aug 11, 2023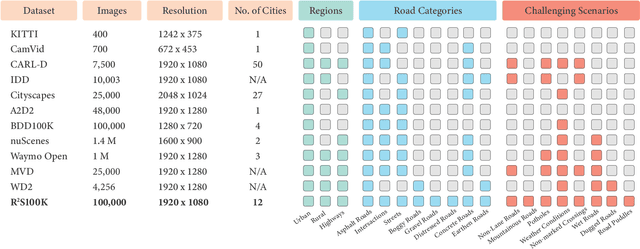
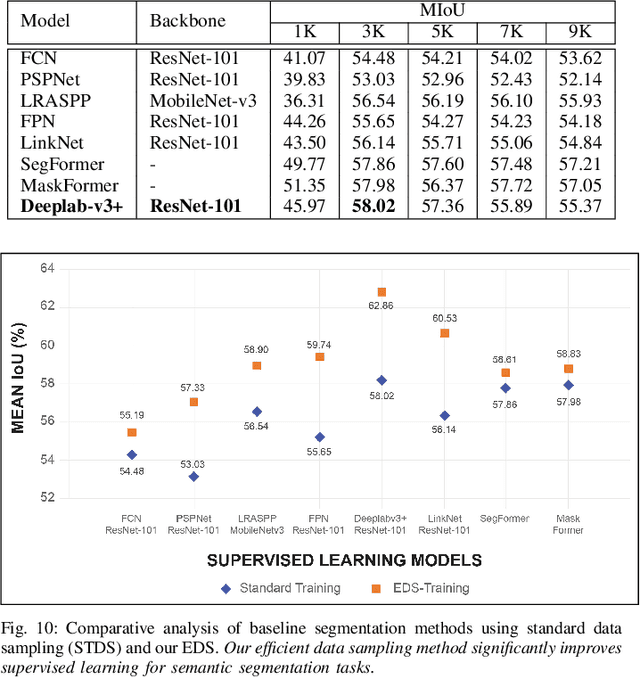


Semantic understanding of roadways is a key enabling factor for safe autonomous driving. However, existing autonomous driving datasets provide well-structured urban roads while ignoring unstructured roadways containing distress, potholes, water puddles, and various kinds of road patches i.e., earthen, gravel etc. To this end, we introduce Road Region Segmentation dataset (R2S100K) -- a large-scale dataset and benchmark for training and evaluation of road segmentation in aforementioned challenging unstructured roadways. R2S100K comprises 100K images extracted from a large and diverse set of video sequences covering more than 1000 KM of roadways. Out of these 100K privacy respecting images, 14,000 images have fine pixel-labeling of road regions, with 86,000 unlabeled images that can be leveraged through semi-supervised learning methods. Alongside, we present an Efficient Data Sampling (EDS) based self-training framework to improve learning by leveraging unlabeled data. Our experimental results demonstrate that the proposed method significantly improves learning methods in generalizability and reduces the labeling cost for semantic segmentation tasks. Our benchmark will be publicly available to facilitate future research at https://r2s100k.github.io/.