 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFree-Lunch Color-Texture Disentanglement for Stylized Image Generation
Mar 21, 2025



Recent advances in Text-to-Image (T2I) diffusion models have transformed image generation, enabling significant progress in stylized generation using only a few style reference images. However, current diffusion-based methods struggle with fine-grained style customization due to challenges in controlling multiple style attributes, such as color and texture. This paper introduces the first tuning-free approach to achieve free-lunch color-texture disentanglement in stylized T2I generation, addressing the need for independently controlled style elements for the Disentangled Stylized Image Generation (DisIG) problem. Our approach leverages the Image-Prompt Additivity property in the CLIP image embedding space to develop techniques for separating and extracting Color-Texture Embeddings (CTE) from individual color and texture reference images. To ensure that the color palette of the generated image aligns closely with the color reference, we apply a whitening and coloring transformation to enhance color consistency. Additionally, to prevent texture loss due to the signal-leak bias inherent in diffusion training, we introduce a noise term that preserves textural fidelity during the Regularized Whitening and Coloring Transformation (RegWCT). Through these methods, our Style Attributes Disentanglement approach (SADis) delivers a more precise and customizable solution for stylized image generation. Experiments on images from the WikiArt and StyleDrop datasets demonstrate that, both qualitatively and quantitatively, SADis surpasses state-of-the-art stylization methods in the DisIG task.Code will be released at https://deepffff.github.io/sadis.github.io/.
Leveraging Semantic Attribute Binding for Free-Lunch Color Control in Diffusion Models
Mar 12, 2025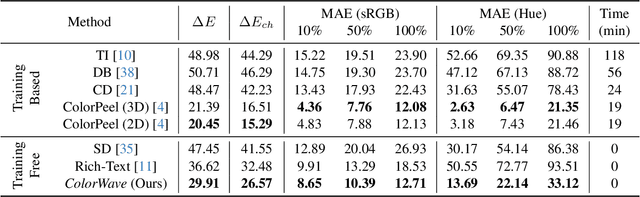
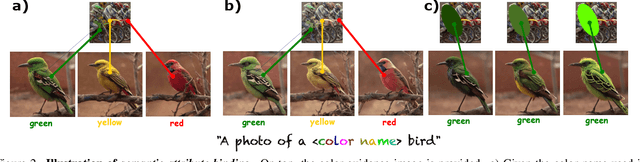
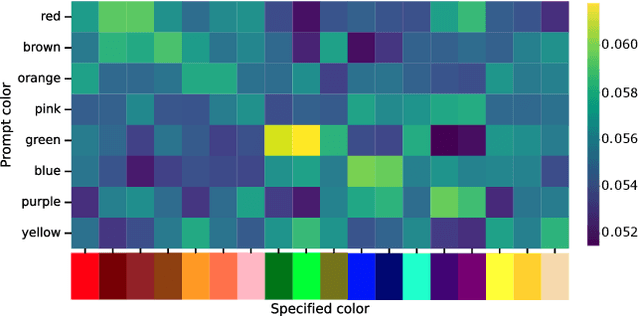
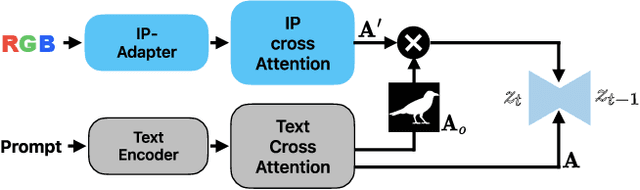
Recent advances in text-to-image (T2I) diffusion models have enabled remarkable control over various attributes, yet precise color specification remains a fundamental challenge. Existing approaches, such as ColorPeel, rely on model personalization, requiring additional optimization and limiting flexibility in specifying arbitrary colors. In this work, we introduce ColorWave, a novel training-free approach that achieves exact RGB-level color control in diffusion models without fine-tuning. By systematically analyzing the cross-attention mechanisms within IP-Adapter, we uncover an implicit binding between textual color descriptors and reference image features. Leveraging this insight, our method rewires these bindings to enforce precise color attribution while preserving the generative capabilities of pretrained models. Our approach maintains generation quality and diversity, outperforming prior methods in accuracy and applicability across diverse object categories. Through extensive evaluations, we demonstrate that ColorWave establishes a new paradigm for structured, color-consistent diffusion-based image synthesis.