 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-free image inversion for one-step diffusion models
May 31, 2026In this work, we introduce a novel training-free inversion (TFinv) framework for one-step diffusion models,addressing key challenges in real image inversion and editing. We first identify two critical factors hamperingreal-image inversion and editing: (1) Initial Latent Editability, which is related to the distance between theinitial noise and the ideal Gaussian distribution, and (2) Caption Gap, which means the alignment betweentext captions and image representations. Both factors influence inversion efficiency and the editability ofone-step diffusion models. Then, we propose two novel techniques: iterative noise alignment (iterNA), whichminimizes the distribution gap to align with the normal Gaussian distribution, and suffix learning (suffL),which enhances text-to-image caption alignment by introducing learned suffix prompt tokens. These techniquesenable precise inversion of input images into their initial noise representations and facilitate image editing.Furthermore, we propose a mask-based editing technique for localized edits while preserving backgroundintegrity. Comprehensive experiments on the PIE-Bench dataset validate that our method TFinv not onlyachieves state-of-the-art performance in one-step diffusion editing, but also significantly outperforms existingmultistep approaches in efficiency. The code is available at https://github.com/tttao-uwu/TFinv.git.
Cross-Modal Prototype Alignment and Mixing for Training-Free Few-Shot Classification
Mar 25, 2026Vision-language models (VLMs) like CLIP are trained with the objective of aligning text and image pairs. To improve CLIP-based few-shot image classification, recent works have observed that, along with text embeddings, image embeddings from the training set are an important source of information. In this work we investigate the impact of directly mixing image and text prototypes for few-shot classification and analyze this from a bias-variance perspective. We show that mixing prototypes acts like a shrinkage estimator. Although mixed prototypes improve classification performance, the image prototypes still add some noise in the form of instance-specific background or context information. In order to capture only information from the image space relevant to the given classification task, we propose projecting image prototypes onto the principal directions of the semantic text embedding space to obtain a text-aligned semantic image subspace. These text-aligned image prototypes, when mixed with text embeddings, further improve classification. However, for downstream datasets with poor cross-modal alignment in CLIP, semantic alignment might be suboptimal. We show that the image subspace can still be leveraged by modeling the anisotropy using class covariances. We demonstrate that combining a text-aligned mixed prototype classifier and an image-specific LDA classifier outperforms existing methods across few-shot classification benchmarks.
IsoCLIP: Decomposing CLIP Projectors for Efficient Intra-modal Alignment
Mar 20, 2026Vision-Language Models like CLIP are extensively used for inter-modal tasks which involve both visual and text modalities. However, when the individual modality encoders are applied to inherently intra-modal tasks like image-to-image retrieval, their performance suffers from the intra-modal misalignment. In this paper we study intra-modal misalignment in CLIP with a focus on the role of the projectors that map pre-projection image and text embeddings into the shared embedding space. By analyzing the form of the cosine similarity applied to projected features, and its interaction with the contrastive CLIP loss, we show that there is an inter-modal operator responsible for aligning the two modalities during training, and a second, intra-modal operator that only enforces intra-modal normalization but does nothing to promote intra-modal alignment. Via spectral analysis of the inter-modal operator, we identify an approximately isotropic subspace in which the two modalities are well-aligned, as well as anisotropic directions specific to each modality. We demonstrate that this aligned subspace can be directly obtained from the projector weights and that removing the anisotropic directions improves intra-modal alignment. Our experiments on intra-modal retrieval and classification benchmarks show that our training-free method reduces intra-modal misalignment, greatly lowers latency, and outperforms existing approaches across multiple pre-trained CLIP-like models. The code is publicly available at: https://github.com/simomagi/IsoCLIP.
Modular Memory is the Key to Continual Learning Agents
Mar 02, 2026Foundation models have transformed machine learning through large-scale pretraining and increased test-time compute. Despite surpassing human performance in several domains, these models remain fundamentally limited in continuous operation, experience accumulation, and personalization, capabilities that are central to adaptive intelligence. While continual learning research has long targeted these goals, its historical focus on in-weight learning (IWL), i.e., updating a single model's parameters to absorb new knowledge, has rendered catastrophic forgetting a persistent challenge. Our position is that combining the strengths of In-Weight Learning (IWL) and the newly emerged capabilities of In-Context Learning (ICL) through the design of modular memory is the missing piece for continual adaptation at scale. We outline a conceptual framework for modular memory-centric architectures that leverage ICL for rapid adaptation and knowledge accumulation, and IWL for stable updates to model capabilities, charting a practical roadmap toward continually learning agents.
Revisiting Weight Regularization for Low-Rank Continual Learning
Feb 19, 2026Continual Learning (CL) with large-scale pre-trained models (PTMs) has recently gained wide attention, shifting the focus from training from scratch to continually adapting PTMs. This has given rise to a promising paradigm: parameter-efficient continual learning (PECL), where task interference is typically mitigated by assigning a task-specific module during training, such as low-rank adapters. However, weight regularization techniques, such as Elastic Weight Consolidation (EWC)-a key strategy in CL-remain underexplored in this new paradigm. In this paper, we revisit weight regularization in low-rank CL as a new perspective for mitigating task interference in PECL. Unlike existing low-rank CL methods, we mitigate task interference by regularizing a shared low-rank update through EWC, thereby keeping the storage requirement and inference costs constant regardless of the number of tasks. Our proposed method EWC-LoRA leverages a low-rank representation to estimate parameter importance over the full-dimensional space. This design offers a practical, computational- and memory-efficient solution for CL with PTMs, and provides insights that may inform the broader application of regularization techniques within PECL. Extensive experiments on various benchmarks demonstrate the effectiveness of EWC-LoRA, achieving a stability-plasticity trade-off superior to existing low-rank CL approaches. These results indicate that, even under low-rank parameterizations, weight regularization remains an effective mechanism for mitigating task interference. Code is available at: https://github.com/yaoyz96/low-rank-cl.
EchoDistill: Bidirectional Concept Distillation for One-Step Diffusion Personalization
Oct 23, 2025Recent advances in accelerating text-to-image (T2I) diffusion models have enabled the synthesis of high-fidelity images even in a single step. However, personalizing these models to incorporate novel concepts remains a challenge due to the limited capacity of one-step models to capture new concept distributions effectively. We propose a bidirectional concept distillation framework, EchoDistill, to enable one-step diffusion personalization (1-SDP). Our approach involves an end-to-end training process where a multi-step diffusion model (teacher) and a one-step diffusion model (student) are trained simultaneously. The concept is first distilled from the teacher model to the student, and then echoed back from the student to the teacher. During the EchoDistill, we share the text encoder between the two models to ensure consistent semantic understanding. Following this, the student model is optimized with adversarial losses to align with the real image distribution and with alignment losses to maintain consistency with the teacher's output. Furthermore, we introduce the bidirectional echoing refinement strategy, wherein the student model leverages its faster generation capability to feedback to the teacher model. This bidirectional concept distillation mechanism not only enhances the student ability to personalize novel concepts but also improves the generative quality of the teacher model. Our experiments demonstrate that this collaborative framework significantly outperforms existing personalization methods over the 1-SDP setup, establishing a novel paradigm for rapid and effective personalization in T2I diffusion models.
Continual Learning for VLMs: A Survey and Taxonomy Beyond Forgetting
Aug 06, 2025Vision-language models (VLMs) have achieved impressive performance across diverse multimodal tasks by leveraging large-scale pre-training. However, enabling them to learn continually from non-stationary data remains a major challenge, as their cross-modal alignment and generalization capabilities are particularly vulnerable to catastrophic forgetting. Unlike traditional unimodal continual learning (CL), VLMs face unique challenges such as cross-modal feature drift, parameter interference due to shared architectures, and zero-shot capability erosion. This survey offers the first focused and systematic review of continual learning for VLMs (VLM-CL). We begin by identifying the three core failure modes that degrade performance in VLM-CL. Based on these, we propose a challenge-driven taxonomy that maps solutions to their target problems: (1) \textit{Multi-Modal Replay Strategies} address cross-modal drift through explicit or implicit memory mechanisms; (2) \textit{Cross-Modal Regularization} preserves modality alignment during updates; and (3) \textit{Parameter-Efficient Adaptation} mitigates parameter interference with modular or low-rank updates. We further analyze current evaluation protocols, datasets, and metrics, highlighting the need for better benchmarks that capture VLM-specific forgetting and compositional generalization. Finally, we outline open problems and future directions, including continual pre-training and compositional zero-shot learning. This survey aims to serve as a comprehensive and diagnostic reference for researchers developing lifelong vision-language systems. All resources are available at: https://github.com/YuyangSunshine/Awesome-Continual-learning-of-Vision-Language-Models.
One-Way Ticket:Time-Independent Unified Encoder for Distilling Text-to-Image Diffusion Models
May 28, 2025
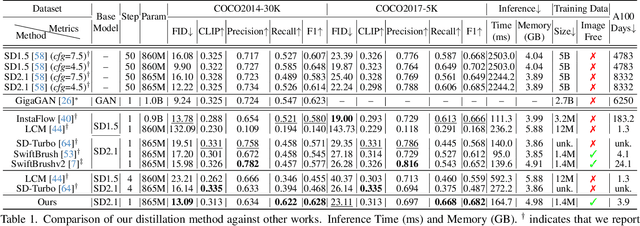

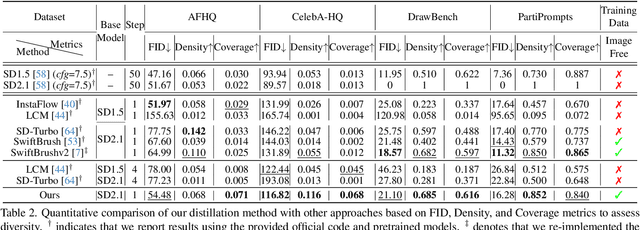
Text-to-Image (T2I) diffusion models have made remarkable advancements in generative modeling; however, they face a trade-off between inference speed and image quality, posing challenges for efficient deployment. Existing distilled T2I models can generate high-fidelity images with fewer sampling steps, but often struggle with diversity and quality, especially in one-step models. From our analysis, we observe redundant computations in the UNet encoders. Our findings suggest that, for T2I diffusion models, decoders are more adept at capturing richer and more explicit semantic information, while encoders can be effectively shared across decoders from diverse time steps. Based on these observations, we introduce the first Time-independent Unified Encoder TiUE for the student model UNet architecture, which is a loop-free image generation approach for distilling T2I diffusion models. Using a one-pass scheme, TiUE shares encoder features across multiple decoder time steps, enabling parallel sampling and significantly reducing inference time complexity. In addition, we incorporate a KL divergence term to regularize noise prediction, which enhances the perceptual realism and diversity of the generated images. Experimental results demonstrate that TiUE outperforms state-of-the-art methods, including LCM, SD-Turbo, and SwiftBrushv2, producing more diverse and realistic results while maintaining the computational efficiency.
Free-Lunch Color-Texture Disentanglement for Stylized Image Generation
Mar 21, 2025



Recent advances in Text-to-Image (T2I) diffusion models have transformed image generation, enabling significant progress in stylized generation using only a few style reference images. However, current diffusion-based methods struggle with fine-grained style customization due to challenges in controlling multiple style attributes, such as color and texture. This paper introduces the first tuning-free approach to achieve free-lunch color-texture disentanglement in stylized T2I generation, addressing the need for independently controlled style elements for the Disentangled Stylized Image Generation (DisIG) problem. Our approach leverages the Image-Prompt Additivity property in the CLIP image embedding space to develop techniques for separating and extracting Color-Texture Embeddings (CTE) from individual color and texture reference images. To ensure that the color palette of the generated image aligns closely with the color reference, we apply a whitening and coloring transformation to enhance color consistency. Additionally, to prevent texture loss due to the signal-leak bias inherent in diffusion training, we introduce a noise term that preserves textural fidelity during the Regularized Whitening and Coloring Transformation (RegWCT). Through these methods, our Style Attributes Disentanglement approach (SADis) delivers a more precise and customizable solution for stylized image generation. Experiments on images from the WikiArt and StyleDrop datasets demonstrate that, both qualitatively and quantitatively, SADis surpasses state-of-the-art stylization methods in the DisIG task.Code will be released at https://deepffff.github.io/sadis.github.io/.
EFC++: Elastic Feature Consolidation with Prototype Re-balancing for Cold Start Exemplar-free Incremental Learning
Mar 13, 2025



Exemplar-Free Class Incremental Learning (EFCIL) aims to learn from a sequence of tasks without having access to previous task data. In this paper, we consider the challenging Cold Start scenario in which insufficient data is available in the first task to learn a high-quality backbone. This is especially challenging for EFCIL since it requires high plasticity, resulting in feature drift which is difficult to compensate for in the exemplar-free setting. To address this problem, we propose an effective approach to consolidate feature representations by regularizing drift in directions highly relevant to previous tasks and employs prototypes to reduce task-recency bias. Our approach, which we call Elastic Feature Consolidation++ (EFC++) exploits a tractable second-order approximation of feature drift based on a proposed Empirical Feature Matrix (EFM). The EFM induces a pseudo-metric in feature space which we use to regularize feature drift in important directions and to update Gaussian prototypes. In addition, we introduce a post-training prototype re-balancing phase that updates classifiers to compensate for feature drift. Experimental results on CIFAR-100, Tiny-ImageNet, ImageNet-Subset, ImageNet-1K and DomainNet demonstrate that EFC++ is better able to learn new tasks by maintaining model plasticity and significantly outperform the state-of-the-art.