 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEFC++: Elastic Feature Consolidation with Prototype Re-balancing for Cold Start Exemplar-free Incremental Learning
Mar 13, 2025



Exemplar-Free Class Incremental Learning (EFCIL) aims to learn from a sequence of tasks without having access to previous task data. In this paper, we consider the challenging Cold Start scenario in which insufficient data is available in the first task to learn a high-quality backbone. This is especially challenging for EFCIL since it requires high plasticity, resulting in feature drift which is difficult to compensate for in the exemplar-free setting. To address this problem, we propose an effective approach to consolidate feature representations by regularizing drift in directions highly relevant to previous tasks and employs prototypes to reduce task-recency bias. Our approach, which we call Elastic Feature Consolidation++ (EFC++) exploits a tractable second-order approximation of feature drift based on a proposed Empirical Feature Matrix (EFM). The EFM induces a pseudo-metric in feature space which we use to regularize feature drift in important directions and to update Gaussian prototypes. In addition, we introduce a post-training prototype re-balancing phase that updates classifiers to compensate for feature drift. Experimental results on CIFAR-100, Tiny-ImageNet, ImageNet-Subset, ImageNet-1K and DomainNet demonstrate that EFC++ is better able to learn new tasks by maintaining model plasticity and significantly outperform the state-of-the-art.
How green is continual learning, really? Analyzing the energy consumption in continual training of vision foundation models
Sep 27, 2024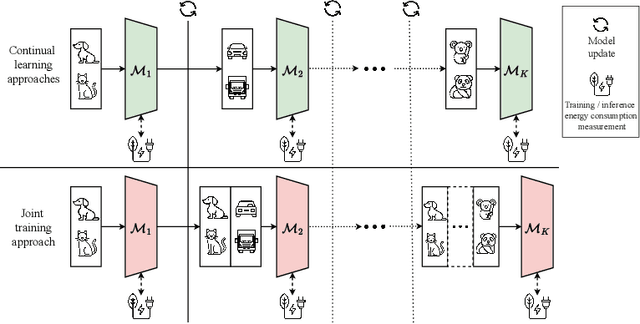
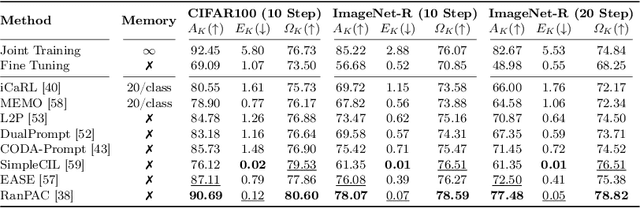
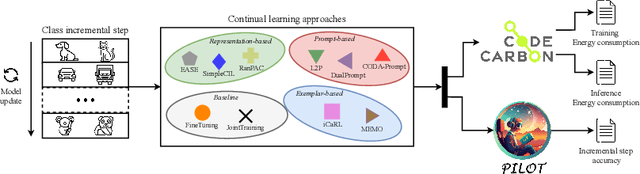
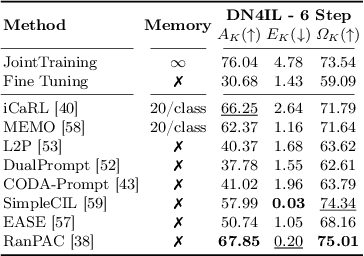
With the ever-growing adoption of AI, its impact on the environment is no longer negligible. Despite the potential that continual learning could have towards Green AI, its environmental sustainability remains relatively uncharted. In this work we aim to gain a systematic understanding of the energy efficiency of continual learning algorithms. To that end, we conducted an extensive set of empirical experiments comparing the energy consumption of recent representation-, prompt-, and exemplar-based continual learning algorithms and two standard baseline (fine tuning and joint training) when used to continually adapt a pre-trained ViT-B/16 foundation model. We performed our experiments on three standard datasets: CIFAR-100, ImageNet-R, and DomainNet. Additionally, we propose a novel metric, the Energy NetScore, which we use measure the algorithm efficiency in terms of energy-accuracy trade-off. Through numerous evaluations varying the number and size of the incremental learning steps, our experiments demonstrate that different types of continual learning algorithms have very different impacts on energy consumption during both training and inference. Although often overlooked in the continual learning literature, we found that the energy consumed during the inference phase is crucial for evaluating the environmental sustainability of continual learning models.
Elastic Feature Consolidation for Cold Start Exemplar-free Incremental Learning
Feb 06, 2024Exemplar-Free Class Incremental Learning (EFCIL) aims to learn from a sequence of tasks without having access to previous task data. In this paper, we consider the challenging Cold Start scenario in which insufficient data is available in the first task to learn a high-quality backbone. This is especially challenging for EFCIL since it requires high plasticity, which results in feature drift which is difficult to compensate for in the exemplar-free setting. To address this problem, we propose a simple and effective approach that consolidates feature representations by regularizing drift in directions highly relevant to previous tasks and employs prototypes to reduce task-recency bias. Our method, called Elastic Feature Consolidation (EFC), exploits a tractable second-order approximation of feature drift based on an Empirical Feature Matrix (EFM). The EFM induces a pseudo-metric in feature space which we use to regularize feature drift in important directions and to update Gaussian prototypes used in a novel asymmetric cross entropy loss which effectively balances prototype rehearsal with data from new tasks. Experimental results on CIFAR-100, Tiny-ImageNet, ImageNet-Subset and ImageNet-1K demonstrate that Elastic Feature Consolidation is better able to learn new tasks by maintaining model plasticity and significantly outperform the state-of-the-art.