 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow green is continual learning, really? Analyzing the energy consumption in continual training of vision foundation models
Sep 27, 2024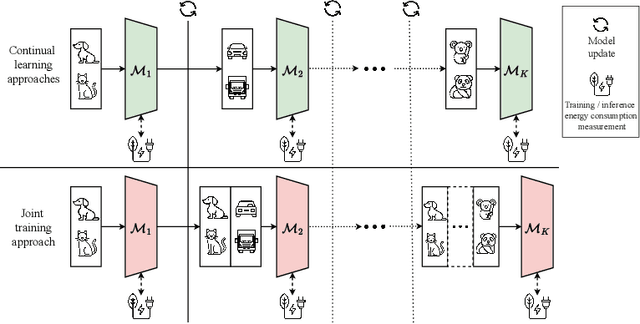
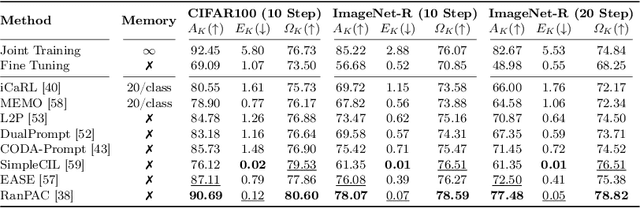
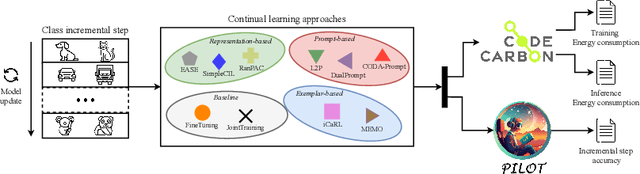
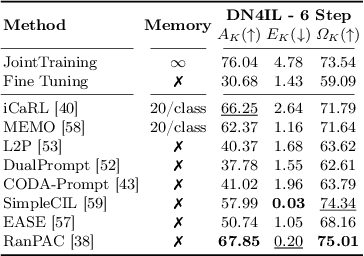
With the ever-growing adoption of AI, its impact on the environment is no longer negligible. Despite the potential that continual learning could have towards Green AI, its environmental sustainability remains relatively uncharted. In this work we aim to gain a systematic understanding of the energy efficiency of continual learning algorithms. To that end, we conducted an extensive set of empirical experiments comparing the energy consumption of recent representation-, prompt-, and exemplar-based continual learning algorithms and two standard baseline (fine tuning and joint training) when used to continually adapt a pre-trained ViT-B/16 foundation model. We performed our experiments on three standard datasets: CIFAR-100, ImageNet-R, and DomainNet. Additionally, we propose a novel metric, the Energy NetScore, which we use measure the algorithm efficiency in terms of energy-accuracy trade-off. Through numerous evaluations varying the number and size of the incremental learning steps, our experiments demonstrate that different types of continual learning algorithms have very different impacts on energy consumption during both training and inference. Although often overlooked in the continual learning literature, we found that the energy consumed during the inference phase is crucial for evaluating the environmental sustainability of continual learning models.
Training Green AI Models Using Elite Samples
Feb 19, 2024



The substantial increase in AI model training has considerable environmental implications, mandating more energy-efficient and sustainable AI practices. On the one hand, data-centric approaches show great potential towards training energy-efficient AI models. On the other hand, instance selection methods demonstrate the capability of training AI models with minimised training sets and negligible performance degradation. Despite the growing interest in both topics, the impact of data-centric training set selection on energy efficiency remains to date unexplored. This paper presents an evolutionary-based sampling framework aimed at (i) identifying elite training samples tailored for datasets and model pairs, (ii) comparing model performance and energy efficiency gains against typical model training practice, and (iii) investigating the feasibility of this framework for fostering sustainable model training practices. To evaluate the proposed framework, we conducted an empirical experiment including 8 commonly used AI classification models and 25 publicly available datasets. The results showcase that by considering 10% elite training samples, the models' performance can show a 50% improvement and remarkable energy savings of 98% compared to the common training practice.
A Systematic Review of Green AI
Jan 31, 2023With the ever-growing adoption of AI-based systems, the carbon footprint of AI is no longer negligible. AI researchers and practitioners are therefore urged to hold themselves accountable for the carbon emissions of the AI models they design and use. This led in recent years to the appearance of researches tackling AI environmental sustainability, a field referred to as Green AI. Despite the rapid growth of interest in the topic, a comprehensive overview of Green AI research is to date still missing. To address this gap, in this paper, we present a systematic review of the Green AI literature. From the analysis of 98 primary studies, different patterns emerge. The topic experienced a considerable growth from 2020 onward. Most studies consider monitoring AI model footprint, tuning hyperparameters to improve model sustainability, or benchmarking models. A mix of position papers, observational studies, and solution papers are present. Most papers focus on the training phase, are algorithm-agnostic or study neural networks, and use image data. Laboratory experiments are the most common research strategy. Reported Green AI energy savings go up to 115%, with savings over 50% being rather common. Industrial parties are involved in Green AI studies, albeit most target academic readers. Green AI tool provisioning is scarce. As a conclusion, the Green AI research field results to have reached a considerable level of maturity. Therefore, from this review emerges that the time is suitable to adopt other Green AI research strategies, and port the numerous promising academic results to industrial practice.
Data-Centric Green AI: An Exploratory Empirical Study
Apr 07, 2022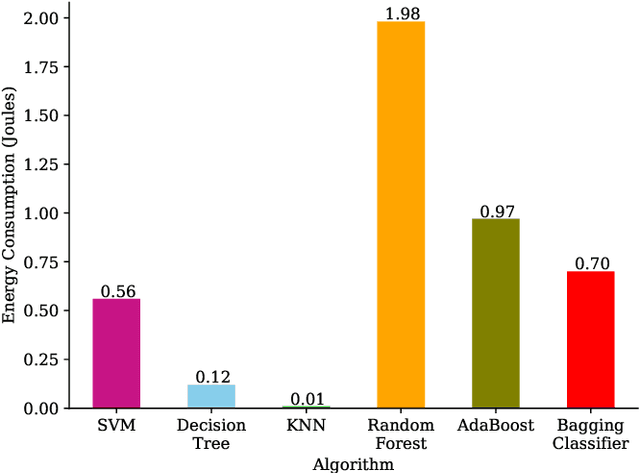
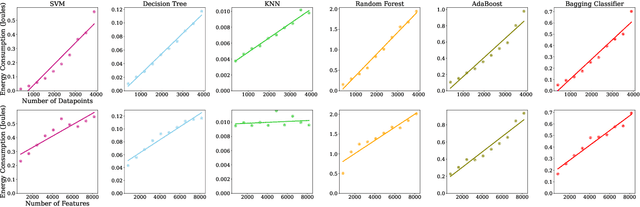
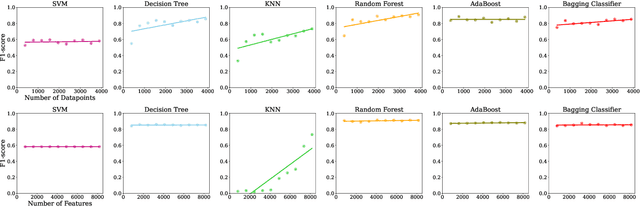
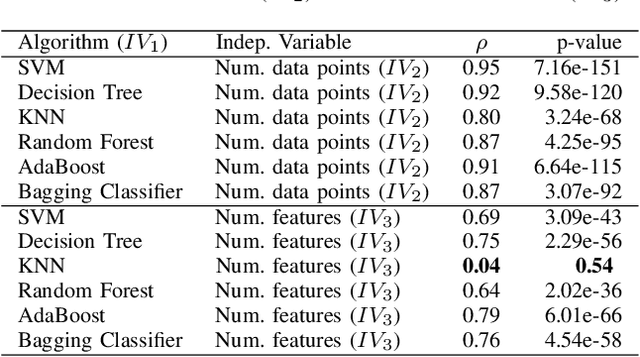
With the growing availability of large-scale datasets, and the popularization of affordable storage and computational capabilities, the energy consumed by AI is becoming a growing concern. To address this issue, in recent years, studies have focused on demonstrating how AI energy efficiency can be improved by tuning the model training strategy. Nevertheless, how modifications applied to datasets can impact the energy consumption of AI is still an open question. To fill this gap, in this exploratory study, we evaluate if data-centric approaches can be utilized to improve AI energy efficiency. To achieve our goal, we conduct an empirical experiment, executed by considering 6 different AI algorithms, a dataset comprising 5,574 data points, and two dataset modifications (number of data points and number of features). Our results show evidence that, by exclusively conducting modifications on datasets, energy consumption can be drastically reduced (up to 92.16%), often at the cost of a negligible or even absent accuracy decline. As additional introductory results, we demonstrate how, by exclusively changing the algorithm used, energy savings up to two orders of magnitude can be achieved. In conclusion, this exploratory investigation empirically demonstrates the importance of applying data-centric techniques to improve AI energy efficiency. Our results call for a research agenda that focuses on data-centric techniques, to further enable and democratize Green AI.
Characterizing Technical Debt and Antipatterns in AI-Based Systems: A Systematic Mapping Study
Mar 17, 2021
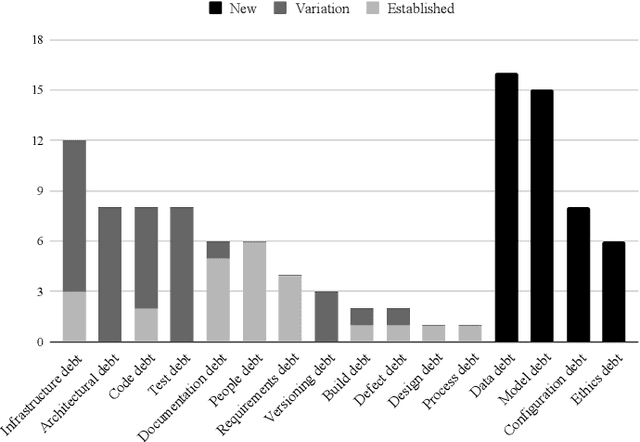
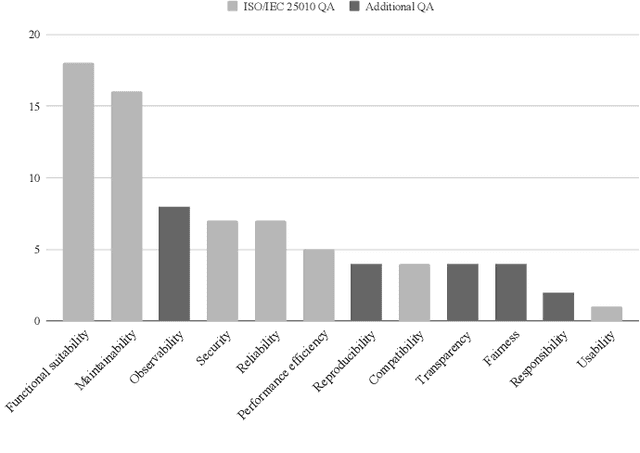
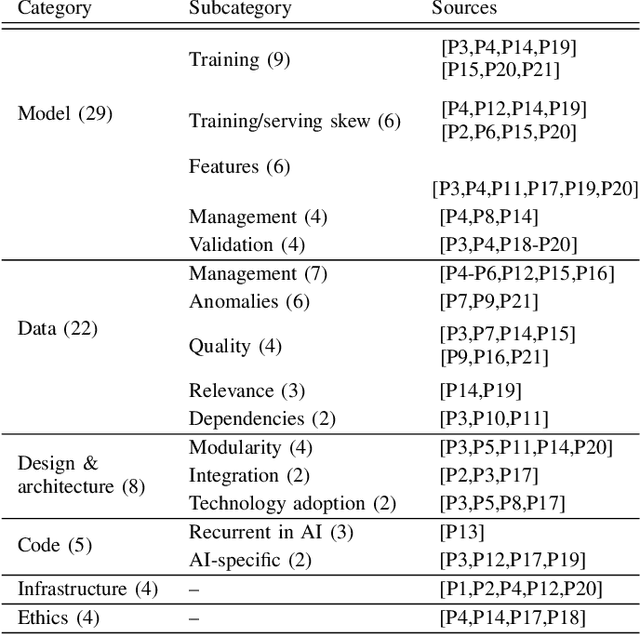
Background: With the rising popularity of Artificial Intelligence (AI), there is a growing need to build large and complex AI-based systems in a cost-effective and manageable way. Like with traditional software, Technical Debt (TD) will emerge naturally over time in these systems, therefore leading to challenges and risks if not managed appropriately. The influence of data science and the stochastic nature of AI-based systems may also lead to new types of TD or antipatterns, which are not yet fully understood by researchers and practitioners. Objective: The goal of our study is to provide a clear overview and characterization of the types of TD (both established and new ones) that appear in AI-based systems, as well as the antipatterns and related solutions that have been proposed. Method: Following the process of a systematic mapping study, 21 primary studies are identified and analyzed. Results: Our results show that (i) established TD types, variations of them, and four new TD types (data, model, configuration, and ethics debt) are present in AI-based systems, (ii) 72 antipatterns are discussed in the literature, the majority related to data and model deficiencies, and (iii) 46 solutions have been proposed, either to address specific TD types, antipatterns, or TD in general. Conclusions: Our results can support AI professionals with reasoning about and communicating aspects of TD present in their systems. Additionally, they can serve as a foundation for future research to further our understanding of TD in AI-based systems.