 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInnovating for Tomorrow: The Convergence of SE and Green AI
Jun 26, 2024
The latest advancements in machine learning, specifically in foundation models, are revolutionizing the frontiers of existing software engineering (SE) processes. This is a bi-directional phenomona, where 1) software systems are now challenged to provide AI-enabled features to their users, and 2) AI is used to automate tasks within the software development lifecycle. In an era where sustainability is a pressing societal concern, our community needs to adopt a long-term plan enabling a conscious transformation that aligns with environmental sustainability values. In this paper, we reflect on the impact of adopting environmentally friendly practices to create AI-enabled software systems and make considerations on the environmental impact of using foundation models for software development.
Batching for Green AI -- An Exploratory Study on Inference
Jul 21, 2023The batch size is an essential parameter to tune during the development of new neural networks. Amongst other quality indicators, it has a large degree of influence on the model's accuracy, generalisability, training times and parallelisability. This fact is generally known and commonly studied. However, during the application phase of a deep learning model, when the model is utilised by an end-user for inference, we find that there is a disregard for the potential benefits of introducing a batch size. In this study, we examine the effect of input batching on the energy consumption and response times of five fully-trained neural networks for computer vision that were considered state-of-the-art at the time of their publication. The results suggest that batching has a significant effect on both of these metrics. Furthermore, we present a timeline of the energy efficiency and accuracy of neural networks over the past decade. We find that in general, energy consumption rises at a much steeper pace than accuracy and question the necessity of this evolution. Additionally, we highlight one particular network, ShuffleNetV2(2018), that achieved a competitive performance for its time while maintaining a much lower energy consumption. Nevertheless, we highlight that the results are model dependent.
The Two Faces of AI in Green Mobile Computing: A Literature Review
Jul 21, 2023



Artificial intelligence is bringing ever new functionalities to the realm of mobile devices that are now considered essential (e.g., camera and voice assistants, recommender systems). Yet, operating artificial intelligence takes up a substantial amount of energy. However, artificial intelligence is also being used to enable more energy-efficient solutions for mobile systems. Hence, artificial intelligence has two faces in that regard, it is both a key enabler of desired (efficient) mobile functionalities and a major power draw on these devices, playing a part in both the solution and the problem. In this paper, we present a review of the literature of the past decade on the usage of artificial intelligence within the realm of green mobile computing. From the analysis of 34 papers, we highlight the emerging patterns and map the field into 13 main topics that are summarized in details. Our results showcase that the field is slowly increasing in the past years, more specifically, since 2019. Regarding the double impact AI has on the mobile energy consumption, the energy consumption of AI-based mobile systems is under-studied in comparison to the usage of AI for energy-efficient mobile computing, and we argue for more exploratory studies in that direction. We observe that although most studies are framed as solution papers (94%), the large majority do not make those solutions publicly available to the community. Moreover, we also show that most contributions are purely academic (28 out of 34 papers) and that we need to promote the involvement of the mobile software industry in this field.
Do DL models and training environments have an impact on energy consumption?
Jul 18, 2023



Current research in the computer vision field mainly focuses on improving Deep Learning (DL) correctness and inference time performance. However, there is still little work on the huge carbon footprint that has training DL models. This study aims to analyze the impact of the model architecture and training environment when training greener computer vision models. We divide this goal into two research questions. First, we analyze the effects of model architecture on achieving greener models while keeping correctness at optimal levels. Second, we study the influence of the training environment on producing greener models. To investigate these relationships, we collect multiple metrics related to energy efficiency and model correctness during the models' training. Then, we outline the trade-offs between the measured energy efficiency and the models' correctness regarding model architecture, and their relationship with the training environment. We conduct this research in the context of a computer vision system for image classification. In conclusion, we show that selecting the proper model architecture and training environment can reduce energy consumption dramatically (up to 98.83%) at the cost of negligible decreases in correctness. Also, we find evidence that GPUs should scale with the models' computational complexity for better energy efficiency.
Uncovering Energy-Efficient Practices in Deep Learning Training: Preliminary Steps Towards Green AI
Mar 24, 2023Modern AI practices all strive towards the same goal: better results. In the context of deep learning, the term "results" often refers to the achieved accuracy on a competitive problem set. In this paper, we adopt an idea from the emerging field of Green AI to consider energy consumption as a metric of equal importance to accuracy and to reduce any irrelevant tasks or energy usage. We examine the training stage of the deep learning pipeline from a sustainability perspective, through the study of hyperparameter tuning strategies and the model complexity, two factors vastly impacting the overall pipeline's energy consumption. First, we investigate the effectiveness of grid search, random search and Bayesian optimisation during hyperparameter tuning, and we find that Bayesian optimisation significantly dominates the other strategies. Furthermore, we analyse the architecture of convolutional neural networks with the energy consumption of three prominent layer types: convolutional, linear and ReLU layers. The results show that convolutional layers are the most computationally expensive by a strong margin. Additionally, we observe diminishing returns in accuracy for more energy-hungry models. The overall energy consumption of training can be halved by reducing the network complexity. In conclusion, we highlight innovative and promising energy-efficient practices for training deep learning models. To expand the application of Green AI, we advocate for a shift in the design of deep learning models, by considering the trade-off between energy efficiency and accuracy.
A Systematic Review of Green AI
Jan 31, 2023With the ever-growing adoption of AI-based systems, the carbon footprint of AI is no longer negligible. AI researchers and practitioners are therefore urged to hold themselves accountable for the carbon emissions of the AI models they design and use. This led in recent years to the appearance of researches tackling AI environmental sustainability, a field referred to as Green AI. Despite the rapid growth of interest in the topic, a comprehensive overview of Green AI research is to date still missing. To address this gap, in this paper, we present a systematic review of the Green AI literature. From the analysis of 98 primary studies, different patterns emerge. The topic experienced a considerable growth from 2020 onward. Most studies consider monitoring AI model footprint, tuning hyperparameters to improve model sustainability, or benchmarking models. A mix of position papers, observational studies, and solution papers are present. Most papers focus on the training phase, are algorithm-agnostic or study neural networks, and use image data. Laboratory experiments are the most common research strategy. Reported Green AI energy savings go up to 115%, with savings over 50% being rather common. Industrial parties are involved in Green AI studies, albeit most target academic readers. Green AI tool provisioning is scarce. As a conclusion, the Green AI research field results to have reached a considerable level of maturity. Therefore, from this review emerges that the time is suitable to adopt other Green AI research strategies, and port the numerous promising academic results to industrial practice.
MLSmellHound: A Context-Aware Code Analysis Tool
May 08, 2022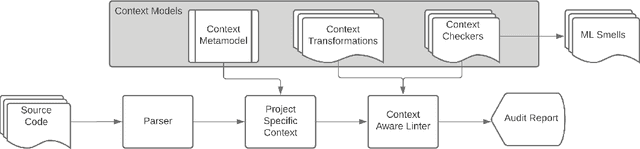
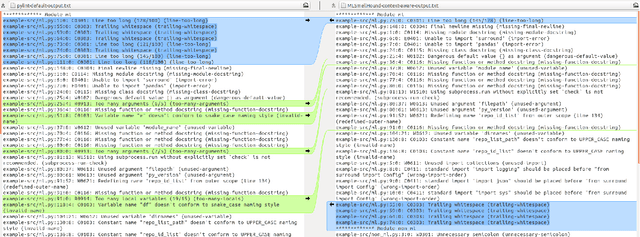
Meeting the rise of industry demand to incorporate machine learning (ML) components into software systems requires interdisciplinary teams contributing to a shared code base. To maintain consistency, reduce defects and ensure maintainability, developers use code analysis tools to aid them in identifying defects and maintaining standards. With the inclusion of machine learning, tools must account for the cultural differences within the teams which manifests as multiple programming languages, and conflicting definitions and objectives. Existing tools fail to identify these cultural differences and are geared towards software engineering which reduces their adoption in ML projects. In our approach we attempt to resolve this problem by exploring the use of context which includes i) purpose of the source code, ii) technical domain, iii) problem domain, iv) team norms, v) operational environment, and vi) development lifecycle stage to provide contextualised error reporting for code analysis. To demonstrate our approach, we adapt Pylint as an example and apply a set of contextual transformations to the linting results based on the domain of individual project files under analysis. This allows for contextualised and meaningful error reporting for the end-user.
Data-Centric Green AI: An Exploratory Empirical Study
Apr 07, 2022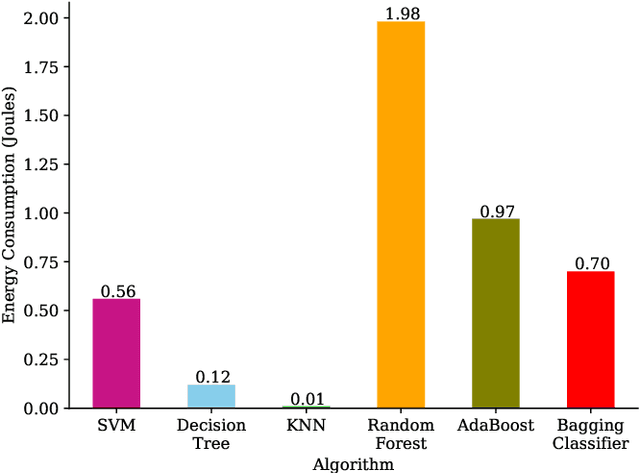
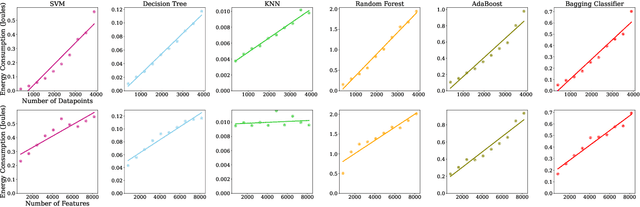
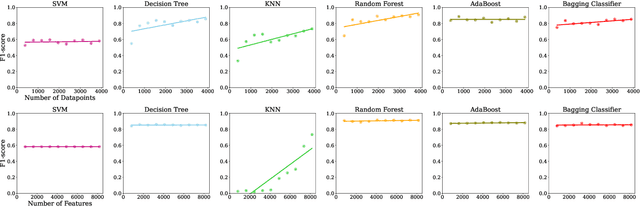
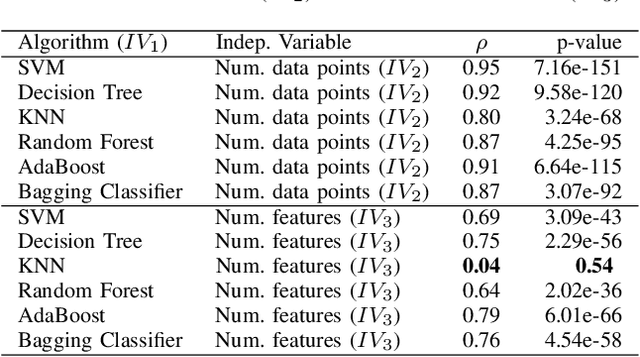
With the growing availability of large-scale datasets, and the popularization of affordable storage and computational capabilities, the energy consumed by AI is becoming a growing concern. To address this issue, in recent years, studies have focused on demonstrating how AI energy efficiency can be improved by tuning the model training strategy. Nevertheless, how modifications applied to datasets can impact the energy consumption of AI is still an open question. To fill this gap, in this exploratory study, we evaluate if data-centric approaches can be utilized to improve AI energy efficiency. To achieve our goal, we conduct an empirical experiment, executed by considering 6 different AI algorithms, a dataset comprising 5,574 data points, and two dataset modifications (number of data points and number of features). Our results show evidence that, by exclusively conducting modifications on datasets, energy consumption can be drastically reduced (up to 92.16%), often at the cost of a negligible or even absent accuracy decline. As additional introductory results, we demonstrate how, by exclusively changing the algorithm used, energy savings up to two orders of magnitude can be achieved. In conclusion, this exploratory investigation empirically demonstrates the importance of applying data-centric techniques to improve AI energy efficiency. Our results call for a research agenda that focuses on data-centric techniques, to further enable and democratize Green AI.
Code Smells for Machine Learning Applications
Mar 30, 2022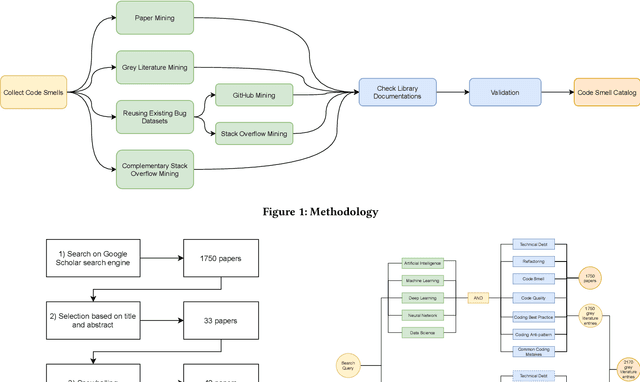
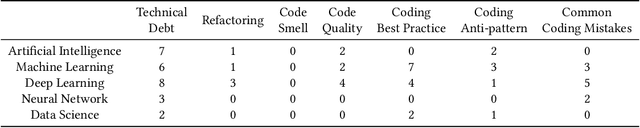
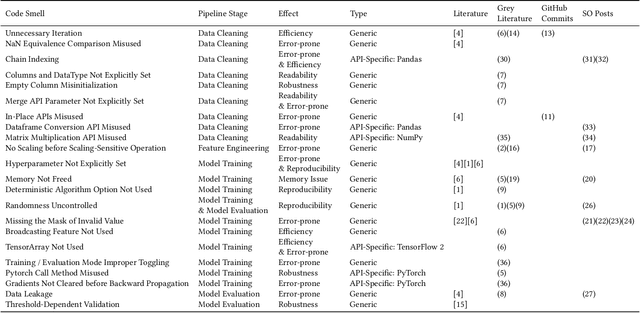

The popularity of machine learning has wildly expanded in recent years. Machine learning techniques have been heatedly studied in academia and applied in the industry to create business value. However, there is a lack of guidelines for code quality in machine learning applications. In particular, code smells have rarely been studied in this domain. Although machine learning code is usually integrated as a small part of an overarching system, it usually plays an important role in its core functionality. Hence ensuring code quality is quintessential to avoid issues in the long run. This paper proposes and identifies a list of 22 machine learning-specific code smells collected from various sources, including papers, grey literature, GitHub commits, and Stack Overflow posts. We pinpoint each smell with a description of its context, potential issues in the long run, and proposed solutions. In addition, we link them to their respective pipeline stage and the evidence from both academic and grey literature. The code smell catalog helps data scientists and developers produce and maintain high-quality machine learning application code.
"Project smells" -- Experiences in Analysing the Software Quality of ML Projects with mllint
Jan 20, 2022


Machine Learning (ML) projects incur novel challenges in their development and productionisation over traditional software applications, though established principles and best practices in ensuring the project's software quality still apply. While using static analysis to catch code smells has been shown to improve software quality attributes, it is only a small piece of the software quality puzzle, especially in the case of ML projects given their additional challenges and lower degree of Software Engineering (SE) experience in the data scientists that develop them. We introduce the novel concept of project smells which consider deficits in project management as a more holistic perspective on software quality in ML projects. An open-source static analysis tool mllint was also implemented to help detect and mitigate these. Our research evaluates this novel concept of project smells in the industrial context of ING, a global bank and large software- and data-intensive organisation. We also investigate the perceived importance of these project smells for proof-of-concept versus production-ready ML projects, as well as the perceived obstructions and benefits to using static analysis tools such as mllint. Our findings indicate a need for context-aware static analysis tools, that fit the needs of the project at its current stage of development, while requiring minimal configuration effort from the user.