 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneous Improvement of ML Model Fairness and Performance by Identifying Bias in Data
Oct 24, 2022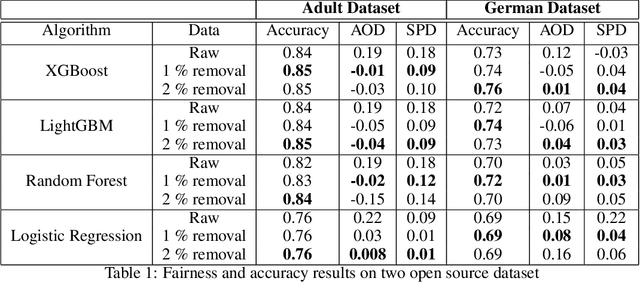
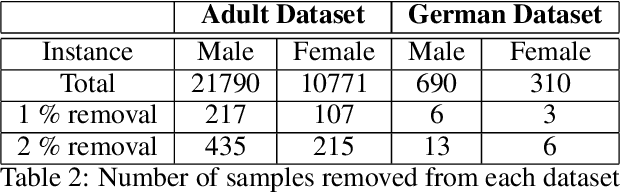
Machine learning models built on datasets containing discriminative instances attributed to various underlying factors result in biased and unfair outcomes. It's a well founded and intuitive fact that existing bias mitigation strategies often sacrifice accuracy in order to ensure fairness. But when AI engine's prediction is used for decision making which reflects on revenue or operational efficiency such as credit risk modelling, it would be desirable by the business if accuracy can be somehow reasonably preserved. This conflicting requirement of maintaining accuracy and fairness in AI motivates our research. In this paper, we propose a fresh approach for simultaneous improvement of fairness and accuracy of ML models within a realistic paradigm. The essence of our work is a data preprocessing technique that can detect instances ascribing a specific kind of bias that should be removed from the dataset before training and we further show that such instance removal will have no adverse impact on model accuracy. In particular, we claim that in the problem settings where instances exist with similar feature but different labels caused by variation in protected attributes , an inherent bias gets induced in the dataset, which can be identified and mitigated through our novel scheme. Our experimental evaluation on two open-source datasets demonstrates how the proposed method can mitigate bias along with improving rather than degrading accuracy, while offering certain set of control for end user.
MLSmellHound: A Context-Aware Code Analysis Tool
May 08, 2022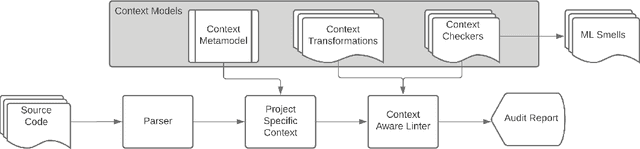
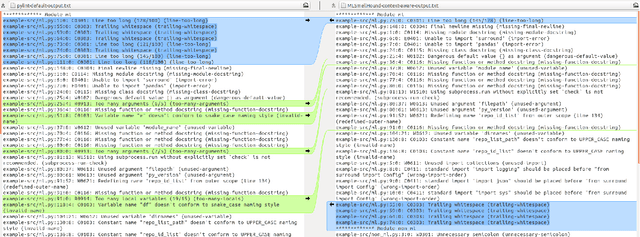
Meeting the rise of industry demand to incorporate machine learning (ML) components into software systems requires interdisciplinary teams contributing to a shared code base. To maintain consistency, reduce defects and ensure maintainability, developers use code analysis tools to aid them in identifying defects and maintaining standards. With the inclusion of machine learning, tools must account for the cultural differences within the teams which manifests as multiple programming languages, and conflicting definitions and objectives. Existing tools fail to identify these cultural differences and are geared towards software engineering which reduces their adoption in ML projects. In our approach we attempt to resolve this problem by exploring the use of context which includes i) purpose of the source code, ii) technical domain, iii) problem domain, iv) team norms, v) operational environment, and vi) development lifecycle stage to provide contextualised error reporting for code analysis. To demonstrate our approach, we adapt Pylint as an example and apply a set of contextual transformations to the linting results based on the domain of individual project files under analysis. This allows for contextualised and meaningful error reporting for the end-user.