 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroupMixNorm Layer for Learning Fair Models
Dec 19, 2023Recent research has identified discriminatory behavior of automated prediction algorithms towards groups identified on specific protected attributes (e.g., gender, ethnicity, age group, etc.). When deployed in real-world scenarios, such techniques may demonstrate biased predictions resulting in unfair outcomes. Recent literature has witnessed algorithms for mitigating such biased behavior mostly by adding convex surrogates of fairness metrics such as demographic parity or equalized odds in the loss function, which are often not easy to estimate. This research proposes a novel in-processing based GroupMixNorm layer for mitigating bias from deep learning models. The GroupMixNorm layer probabilistically mixes group-level feature statistics of samples across different groups based on the protected attribute. The proposed method improves upon several fairness metrics with minimal impact on overall accuracy. Analysis on benchmark tabular and image datasets demonstrates the efficacy of the proposed method in achieving state-of-the-art performance. Further, the experimental analysis also suggests the robustness of the GroupMixNorm layer against new protected attributes during inference and its utility in eliminating bias from a pre-trained network.
Simultaneous Improvement of ML Model Fairness and Performance by Identifying Bias in Data
Oct 24, 2022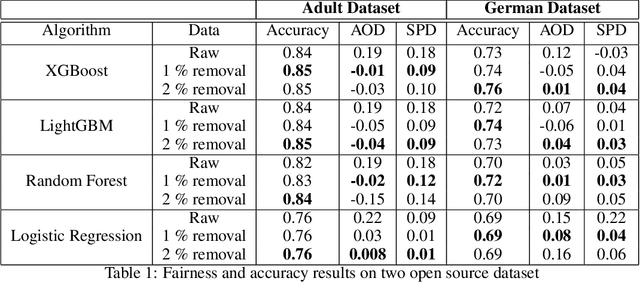
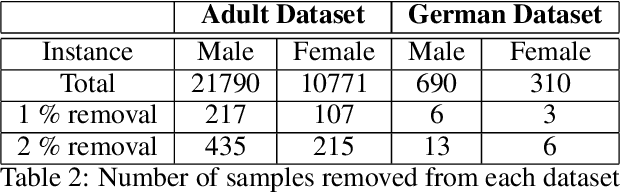
Machine learning models built on datasets containing discriminative instances attributed to various underlying factors result in biased and unfair outcomes. It's a well founded and intuitive fact that existing bias mitigation strategies often sacrifice accuracy in order to ensure fairness. But when AI engine's prediction is used for decision making which reflects on revenue or operational efficiency such as credit risk modelling, it would be desirable by the business if accuracy can be somehow reasonably preserved. This conflicting requirement of maintaining accuracy and fairness in AI motivates our research. In this paper, we propose a fresh approach for simultaneous improvement of fairness and accuracy of ML models within a realistic paradigm. The essence of our work is a data preprocessing technique that can detect instances ascribing a specific kind of bias that should be removed from the dataset before training and we further show that such instance removal will have no adverse impact on model accuracy. In particular, we claim that in the problem settings where instances exist with similar feature but different labels caused by variation in protected attributes , an inherent bias gets induced in the dataset, which can be identified and mitigated through our novel scheme. Our experimental evaluation on two open-source datasets demonstrates how the proposed method can mitigate bias along with improving rather than degrading accuracy, while offering certain set of control for end user.
FairGen: Fair Synthetic Data Generation
Oct 24, 2022With the rising adoption of Machine Learning across the domains like banking, pharmaceutical, ed-tech, etc, it has become utmost important to adopt responsible AI methods to ensure models are not unfairly discriminating against any group. Given the lack of clean training data, generative adversarial techniques are preferred to generate synthetic data with several state-of-the-art architectures readily available across various domains from unstructured data such as text, images to structured datasets modelling fraud detection and many more. These techniques overcome several challenges such as class imbalance, limited training data, restricted access to data due to privacy issues. Existing work focusing on generating fair data either works for a certain GAN architecture or is very difficult to tune across the GANs. In this paper, we propose a pipeline to generate fairer synthetic data independent of the GAN architecture. The proposed paper utilizes a pre-processing algorithm to identify and remove bias inducing samples. In particular, we claim that while generating synthetic data most GANs amplify bias present in the training data but by removing these bias inducing samples, GANs essentially focuses more on real informative samples. Our experimental evaluation on two open-source datasets demonstrates how the proposed pipeline is generating fair data along with improved performance in some cases.