 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical Bias Mitigation through Proxy Sensitive Attribute Label Generation
Dec 26, 2023Addressing bias in the trained machine learning system often requires access to sensitive attributes. In practice, these attributes are not available either due to legal and policy regulations or data unavailability for a given demographic. Existing bias mitigation algorithms are limited in their applicability to real-world scenarios as they require access to sensitive attributes to achieve fairness. In this research work, we aim to address this bottleneck through our proposed unsupervised proxy-sensitive attribute label generation technique. Towards this end, we propose a two-stage approach of unsupervised embedding generation followed by clustering to obtain proxy-sensitive labels. The efficacy of our work relies on the assumption that bias propagates through non-sensitive attributes that are correlated to the sensitive attributes and, when mapped to the high dimensional latent space, produces clusters of different demographic groups that exist in the data. Experimental results demonstrate that bias mitigation using existing algorithms such as Fair Mixup and Adversarial Debiasing yields comparable results on derived proxy labels when compared against using true sensitive attributes.
GroupMixNorm Layer for Learning Fair Models
Dec 19, 2023Recent research has identified discriminatory behavior of automated prediction algorithms towards groups identified on specific protected attributes (e.g., gender, ethnicity, age group, etc.). When deployed in real-world scenarios, such techniques may demonstrate biased predictions resulting in unfair outcomes. Recent literature has witnessed algorithms for mitigating such biased behavior mostly by adding convex surrogates of fairness metrics such as demographic parity or equalized odds in the loss function, which are often not easy to estimate. This research proposes a novel in-processing based GroupMixNorm layer for mitigating bias from deep learning models. The GroupMixNorm layer probabilistically mixes group-level feature statistics of samples across different groups based on the protected attribute. The proposed method improves upon several fairness metrics with minimal impact on overall accuracy. Analysis on benchmark tabular and image datasets demonstrates the efficacy of the proposed method in achieving state-of-the-art performance. Further, the experimental analysis also suggests the robustness of the GroupMixNorm layer against new protected attributes during inference and its utility in eliminating bias from a pre-trained network.
Transitioning from Real to Synthetic data: Quantifying the bias in model
May 10, 2021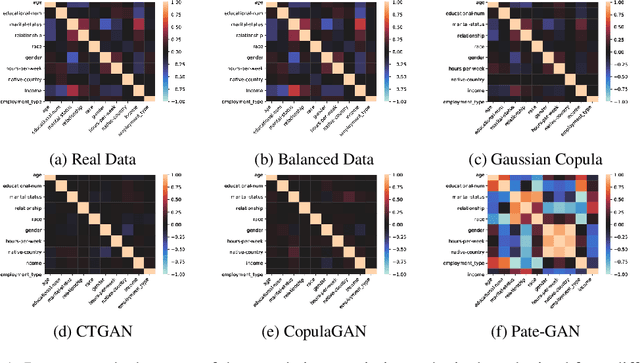
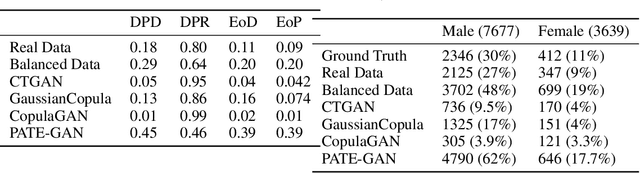
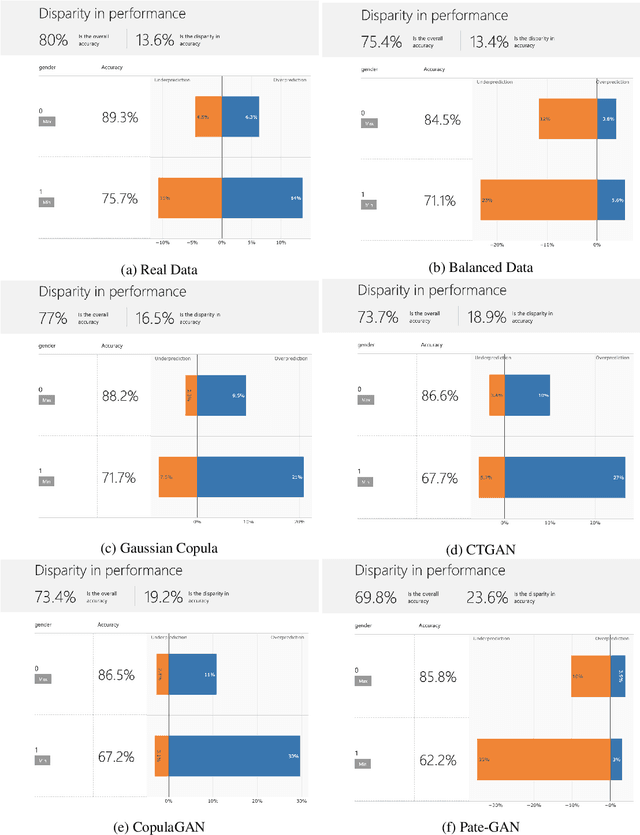
With the advent of generative modeling techniques, synthetic data and its use has penetrated across various domains from unstructured data such as image, text to structured dataset modeling healthcare outcome, risk decisioning in financial domain, and many more. It overcomes various challenges such as limited training data, class imbalance, restricted access to dataset owing to privacy issues. To ensure the trained model used for automated decisioning purposes makes a fair decision there exist prior work to quantify and mitigate those issues. This study aims to establish a trade-off between bias and fairness in the models trained using synthetic data. Variants of synthetic data generation techniques were studied to understand bias amplification including differentially private generation schemes. Through experiments on a tabular dataset, we demonstrate there exist a varying levels of bias impact on models trained using synthetic data. Techniques generating less correlated feature performs well as evident through fairness metrics with 94\%, 82\%, and 88\% relative drop in DPD (demographic parity difference), EoD (equality of odds) and EoP (equality of opportunity) respectively, and 24\% relative improvement in DRP (demographic parity ratio) with respect to the real dataset. We believe the outcome of our research study will help data science practitioners understand the bias in the use of synthetic data.
Towards Zero-Shot Learning with Fewer Seen Class Examples
Nov 14, 2020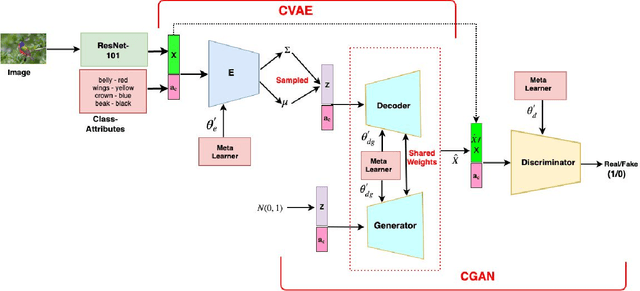
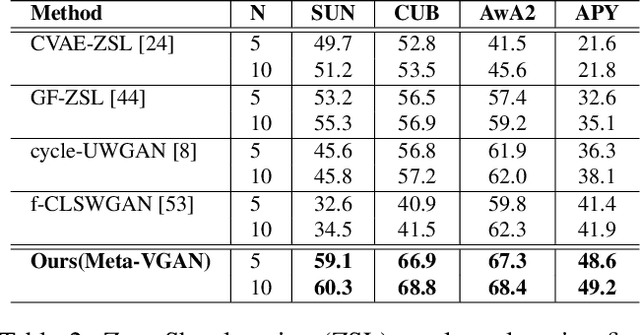
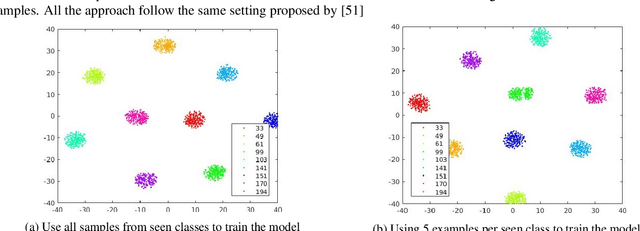
We present a meta-learning based generative model for zero-shot learning (ZSL) towards a challenging setting when the number of training examples from each \emph{seen} class is very few. This setup contrasts with the conventional ZSL approaches, where training typically assumes the availability of a sufficiently large number of training examples from each of the seen classes. The proposed approach leverages meta-learning to train a deep generative model that integrates variational autoencoder and generative adversarial networks. We propose a novel task distribution where meta-train and meta-validation classes are disjoint to simulate the ZSL behaviour in training. Once trained, the model can generate synthetic examples from seen and unseen classes. Synthesize samples can then be used to train the ZSL framework in a supervised manner. The meta-learner enables our model to generates high-fidelity samples using only a small number of training examples from seen classes. We conduct extensive experiments and ablation studies on four benchmark datasets of ZSL and observe that the proposed model outperforms state-of-the-art approaches by a significant margin when the number of examples per seen class is very small.
Stacked Adversarial Network for Zero-Shot Sketch based Image Retrieval
Jan 18, 2020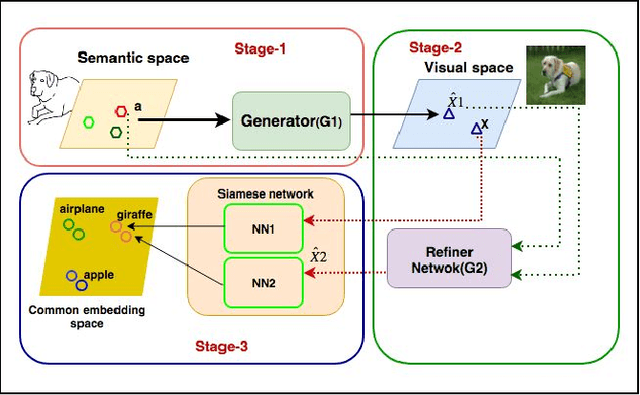
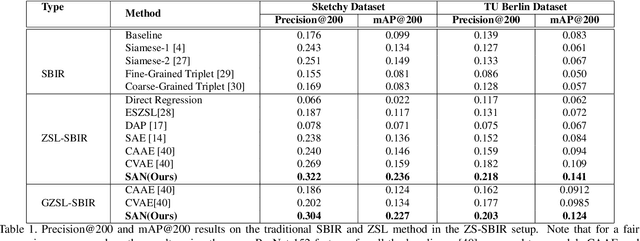
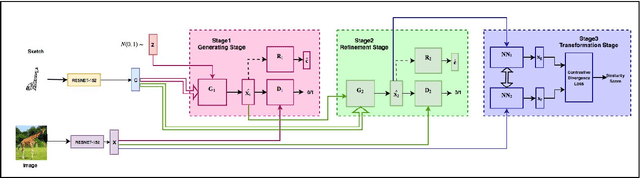
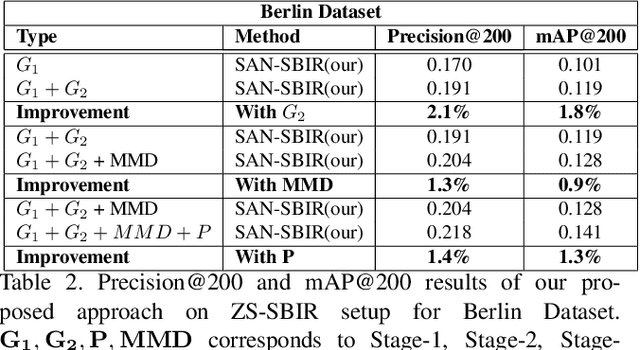
Conventional approaches to Sketch-Based Image Retrieval (SBIR) assume that the data of all the classes are available during training. The assumption may not always be practical since the data of a few classes may be unavailable, or the classes may not appear at the time of training. Zero-Shot Sketch-Based Image Retrieval (ZS-SBIR) relaxes this constraint and allows the algorithm to handle previously unseen classes during the test. This paper proposes a generative approach based on the Stacked Adversarial Network (SAN) and the advantage of Siamese Network (SN) for ZS-SBIR. While SAN generates a high-quality sample, SN learns a better distance metric compared to that of the nearest neighbor search. The capability of the generative model to synthesize image features based on the sketch reduces the SBIR problem to that of an image-to-image retrieval problem. We evaluate the efficacy of our proposed approach on TU-Berlin, and Sketchy database in both standard ZSL and generalized ZSL setting. The proposed method yields a significant improvement in standard ZSL as well as in a more challenging generalized ZSL setting (GZSL) for SBIR.
Blind Deblurring Using GANs
Jul 27, 2019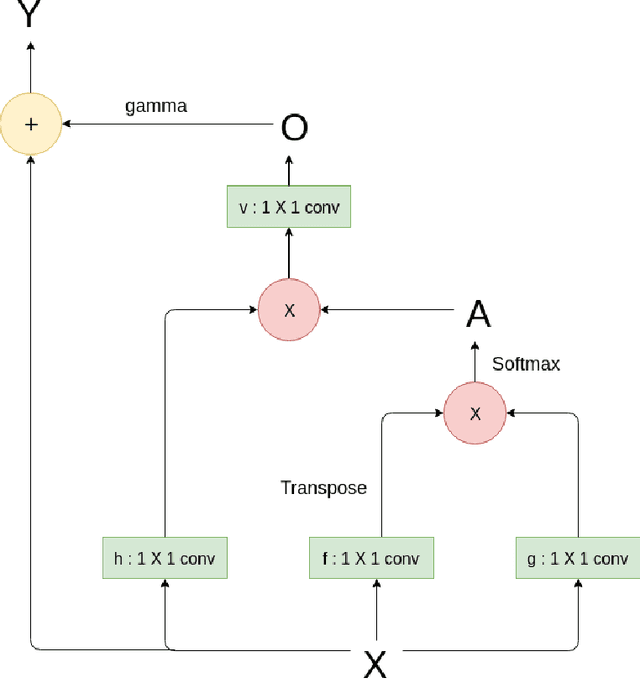


Deblurring is the task of restoring a blurred image to a sharp one, retrieving the information lost due to the blur. In blind deblurring we have no information regarding the blur kernel. As deblurring can be considered as an image to image translation task, deep learning based solutions, including the ones which use GAN (Generative Adversarial Network), have been proven effective for deblurring. Most of them have an encoder-decoder structure. Our objective is to try different GAN structures and improve its performance through various modifications to the existing structure for supervised deblurring. In supervised deblurring we have pairs of blurred and their corresponding sharp images, while in the unsupervised case we have a set of blurred and sharp images but their is no correspondence between them. Modifications to the structures is done to improve the global perception of the model. As blur is non-uniform in nature, for deblurring we require global information of the entire image, whereas convolution used in CNN is able to provide only local perception. Deep models can be used to improve global perception but due to large number of parameters it becomes difficult for it to converge and inference time increases, to solve this we propose the use of attention module (non-local block) which was previously used in language translation and other image to image translation tasks in deblurring. Use of residual connection also improves the performance of deblurring as features from the lower layers are added to the upper layers of the model. It has been found that classical losses like L1, L2, and perceptual loss also help in training of GANs when added together with adversarial loss. We also concatenate edge information of the image to observe its effects on deblurring. We also use feedback modules to retain long term dependencies